 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details
Jul 03, 2025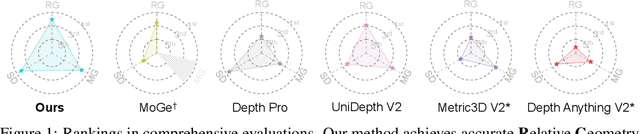
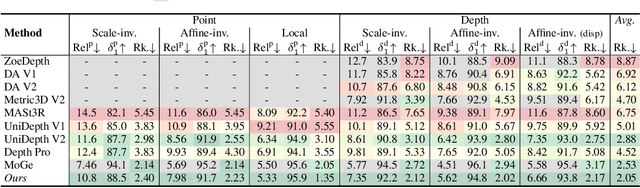
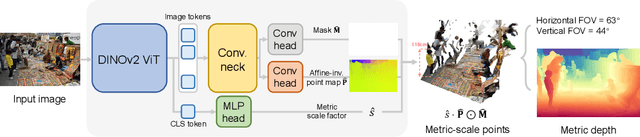
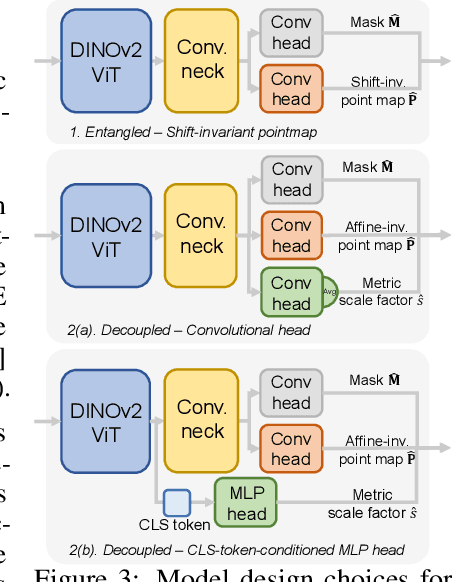
We propose MoGe-2, an advanced open-domain geometry estimation model that recovers a metric scale 3D point map of a scene from a single image. Our method builds upon the recent monocular geometry estimation approach, MoGe, which predicts affine-invariant point maps with unknown scales. We explore effective strategies to extend MoGe for metric geometry prediction without compromising the relative geometry accuracy provided by the affine-invariant point representation. Additionally, we discover that noise and errors in real data diminish fine-grained detail in the predicted geometry. We address this by developing a unified data refinement approach that filters and completes real data from different sources using sharp synthetic labels, significantly enhancing the granularity of the reconstructed geometry while maintaining the overall accuracy. We train our model on a large corpus of mixed datasets and conducted comprehensive evaluations, demonstrating its superior performance in achieving accurate relative geometry, precise metric scale, and fine-grained detail recovery -- capabilities that no previous methods have simultaneously achieved.
Structured 3D Latents for Scalable and Versatile 3D Generation
Dec 02, 2024



We introduce a novel 3D generation method for versatile and high-quality 3D asset creation. The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes. This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model, comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding. We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects. Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales. We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models. Code, model, and data will be released.