 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNative and Compact Structured Latents for 3D Generation
Dec 16, 2025Recent advancements in 3D generative modeling have significantly improved the generation realism, yet the field is still hampered by existing representations, which struggle to capture assets with complex topologies and detailed appearance. This paper present an approach for learning a structured latent representation from native 3D data to address this challenge. At its core is a new sparse voxel structure called O-Voxel, an omni-voxel representation that encodes both geometry and appearance. O-Voxel can robustly model arbitrary topology, including open, non-manifold, and fully-enclosed surfaces, while capturing comprehensive surface attributes beyond texture color, such as physically-based rendering parameters. Based on O-Voxel, we design a Sparse Compression VAE which provides a high spatial compression rate and a compact latent space. We train large-scale flow-matching models comprising 4B parameters for 3D generation using diverse public 3D asset datasets. Despite their scale, inference remains highly efficient. Meanwhile, the geometry and material quality of our generated assets far exceed those of existing models. We believe our approach offers a significant advancement in 3D generative modeling.
Unveiling the Learning Mind of Language Models: A Cognitive Framework and Empirical Study
Jun 16, 2025
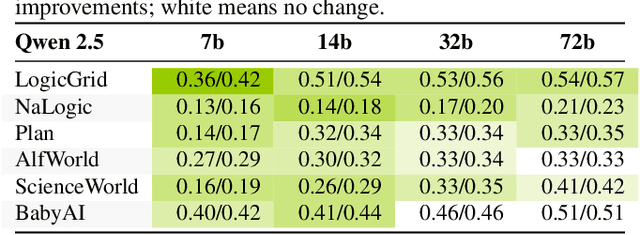

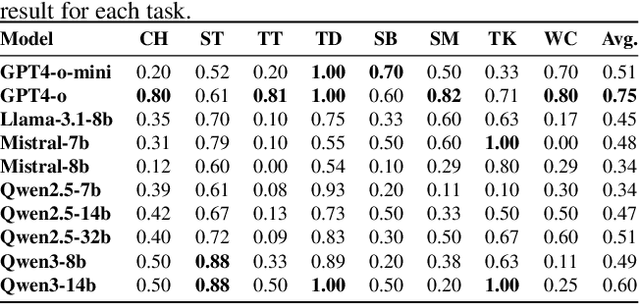
Large language models (LLMs) have shown impressive capabilities across tasks such as mathematics, coding, and reasoning, yet their learning ability, which is crucial for adapting to dynamic environments and acquiring new knowledge, remains underexplored. In this work, we address this gap by introducing a framework inspired by cognitive psychology and education. Specifically, we decompose general learning ability into three distinct, complementary dimensions: Learning from Instructor (acquiring knowledge via explicit guidance), Learning from Concept (internalizing abstract structures and generalizing to new contexts), and Learning from Experience (adapting through accumulated exploration and feedback). We conduct a comprehensive empirical study across the three learning dimensions and identify several insightful findings, such as (i) interaction improves learning; (ii) conceptual understanding is scale-emergent and benefits larger models; and (iii) LLMs are effective few-shot learners but not many-shot learners. Based on our framework and empirical findings, we introduce a benchmark that provides a unified and realistic evaluation of LLMs' general learning abilities across three learning cognition dimensions. It enables diagnostic insights and supports evaluation and development of more adaptive and human-like models.
LLM-powered Multi-agent Framework for Goal-oriented Learning in Intelligent Tutoring System
Jan 27, 2025



Intelligent Tutoring Systems (ITSs) have revolutionized education by offering personalized learning experiences. However, as goal-oriented learning, which emphasizes efficiently achieving specific objectives, becomes increasingly important in professional contexts, existing ITSs often struggle to deliver this type of targeted learning experience. In this paper, we propose GenMentor, an LLM-powered multi-agent framework designed to deliver goal-oriented, personalized learning within ITS. GenMentor begins by accurately mapping learners' goals to required skills using a fine-tuned LLM trained on a custom goal-to-skill dataset. After identifying the skill gap, it schedules an efficient learning path using an evolving optimization approach, driven by a comprehensive and dynamic profile of learners' multifaceted status. Additionally, GenMentor tailors learning content with an exploration-drafting-integration mechanism to align with individual learner needs. Extensive automated and human evaluations demonstrate GenMentor's effectiveness in learning guidance and content quality. Furthermore, we have deployed it in practice and also implemented it as an application. Practical human study with professional learners further highlights its effectiveness in goal alignment and resource targeting, leading to enhanced personalization. Supplementary resources are available at https://github.com/GeminiLight/gen-mentor.
FlagVNE: A Flexible and Generalizable Reinforcement Learning Framework for Network Resource Allocation
Apr 19, 2024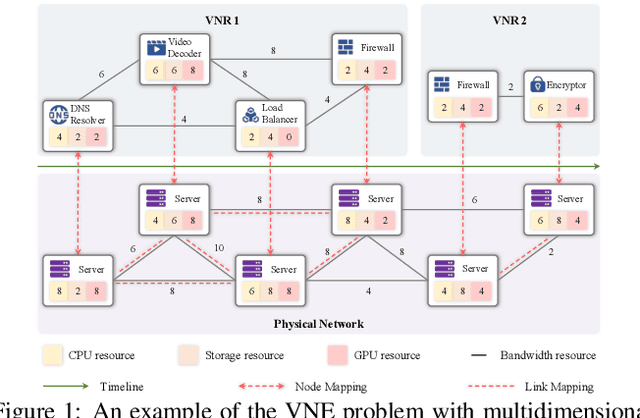
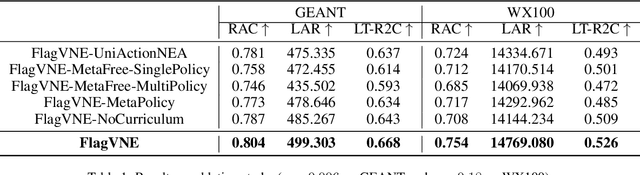
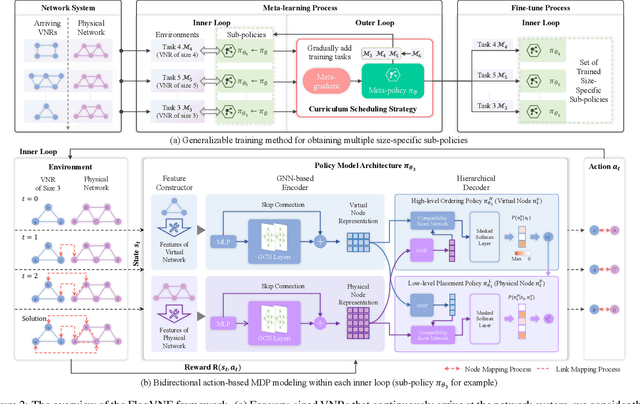
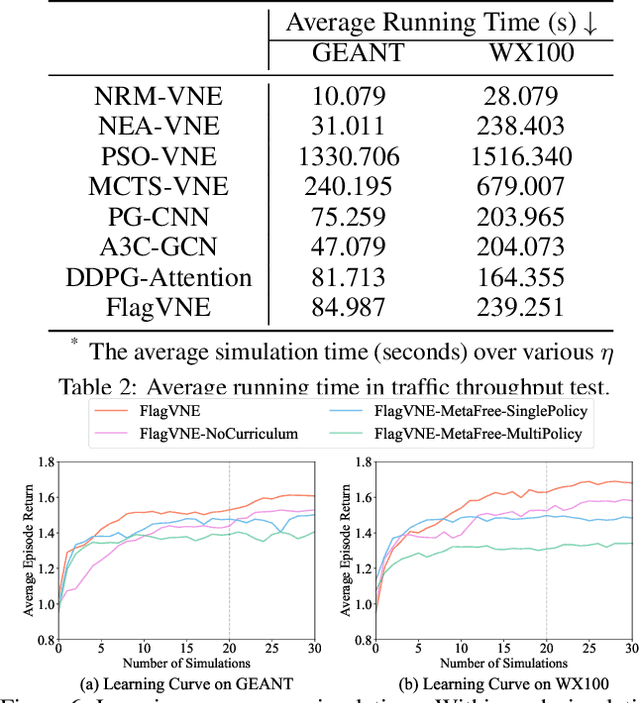
Virtual network embedding (VNE) is an essential resource allocation task in network virtualization, aiming to map virtual network requests (VNRs) onto physical infrastructure. Reinforcement learning (RL) has recently emerged as a promising solution to this problem. However, existing RL-based VNE methods are limited by the unidirectional action design and one-size-fits-all training strategy, resulting in restricted searchability and generalizability. In this paper, we propose a FLexible And Generalizable RL framework for VNE, named FlagVNE. Specifically, we design a bidirectional action-based Markov decision process model that enables the joint selection of virtual and physical nodes, thus improving the exploration flexibility of solution space. To tackle the expansive and dynamic action space, we design a hierarchical decoder to generate adaptive action probability distributions and ensure high training efficiency. Furthermore, to overcome the generalization issue for varying VNR sizes, we propose a meta-RL-based training method with a curriculum scheduling strategy, facilitating specialized policy training for each VNR size. Finally, extensive experimental results show the effectiveness of FlagVNE across multiple key metrics. Our code is available at GitHub (https://github.com/GeminiLight/flag-vne).
Recognizing Unseen Objects via Multimodal Intensive Knowledge Graph Propagation
Jun 21, 2023



Zero-Shot Learning (ZSL), which aims at automatically recognizing unseen objects, is a promising learning paradigm to understand new real-world knowledge for machines continuously. Recently, the Knowledge Graph (KG) has been proven as an effective scheme for handling the zero-shot task with large-scale and non-attribute data. Prior studies always embed relationships of seen and unseen objects into visual information from existing knowledge graphs to promote the cognitive ability of the unseen data. Actually, real-world knowledge is naturally formed by multimodal facts. Compared with ordinary structural knowledge from a graph perspective, multimodal KG can provide cognitive systems with fine-grained knowledge. For example, the text description and visual content can depict more critical details of a fact than only depending on knowledge triplets. Unfortunately, this multimodal fine-grained knowledge is largely unexploited due to the bottleneck of feature alignment between different modalities. To that end, we propose a multimodal intensive ZSL framework that matches regions of images with corresponding semantic embeddings via a designed dense attention module and self-calibration loss. It makes the semantic transfer process of our ZSL framework learns more differentiated knowledge between entities. Our model also gets rid of the performance limitation of only using rough global features. We conduct extensive experiments and evaluate our model on large-scale real-world data. The experimental results clearly demonstrate the effectiveness of the proposed model in standard zero-shot classification tasks.
Learning Profitable NFT Image Diffusions via Multiple Visual-Policy Guided Reinforcement Learning
Jun 20, 2023



We study the task of generating profitable Non-Fungible Token (NFT) images from user-input texts. Recent advances in diffusion models have shown great potential for image generation. However, existing works can fall short in generating visually-pleasing and highly-profitable NFT images, mainly due to the lack of 1) plentiful and fine-grained visual attribute prompts for an NFT image, and 2) effective optimization metrics for generating high-quality NFT images. To solve these challenges, we propose a Diffusion-based generation framework with Multiple Visual-Policies as rewards (i.e., Diffusion-MVP) for NFT images. The proposed framework consists of a large language model (LLM), a diffusion-based image generator, and a series of visual rewards by design. First, the LLM enhances a basic human input (such as "panda") by generating more comprehensive NFT-style prompts that include specific visual attributes, such as "panda with Ninja style and green background." Second, the diffusion-based image generator is fine-tuned using a large-scale NFT dataset to capture fine-grained image styles and accessory compositions of popular NFT elements. Third, we further propose to utilize multiple visual-policies as optimization goals, including visual rarity levels, visual aesthetic scores, and CLIP-based text-image relevances. This design ensures that our proposed Diffusion-MVP is capable of minting NFT images with high visual quality and market value. To facilitate this research, we have collected the largest publicly available NFT image dataset to date, consisting of 1.5 million high-quality images with corresponding texts and market values. Extensive experiments including objective evaluations and user studies demonstrate that our framework can generate NFT images showing more visually engaging elements and higher market value, compared with SOTA approaches.
MM-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation
Dec 19, 2022We propose the first joint audio-video generation framework that brings engaging watching and listening experiences simultaneously, towards high-quality realistic videos. To generate joint audio-video pairs, we propose a novel Multi-Modal Diffusion model (i.e., MM-Diffusion), with two-coupled denoising autoencoders. In contrast to existing single-modal diffusion models, MM-Diffusion consists of a sequential multi-modal U-Net for a joint denoising process by design. Two subnets for audio and video learn to gradually generate aligned audio-video pairs from Gaussian noises. To ensure semantic consistency across modalities, we propose a novel random-shift based attention block bridging over the two subnets, which enables efficient cross-modal alignment, and thus reinforces the audio-video fidelity for each other. Extensive experiments show superior results in unconditional audio-video generation, and zero-shot conditional tasks (e.g., video-to-audio). In particular, we achieve the best FVD and FAD on Landscape and AIST++ dancing datasets. Turing tests of 10k votes further demonstrate dominant preferences for our model. The code and pre-trained models can be downloaded at https://github.com/researchmm/MM-Diffusion.
Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition
Apr 18, 2022
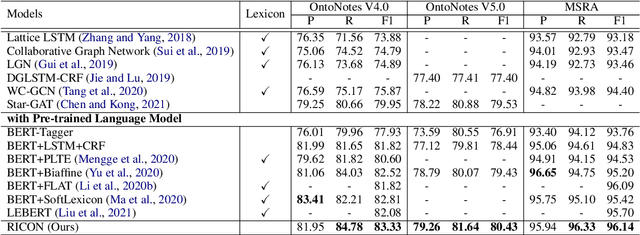
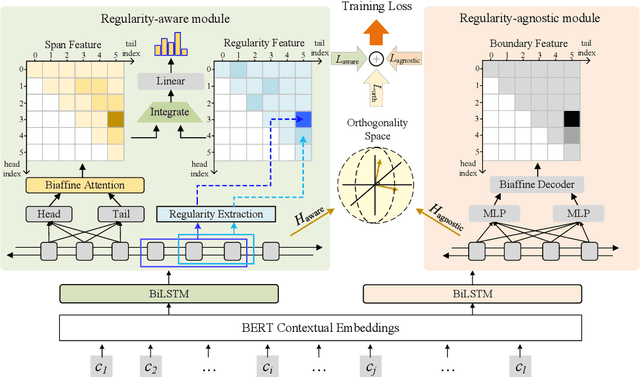
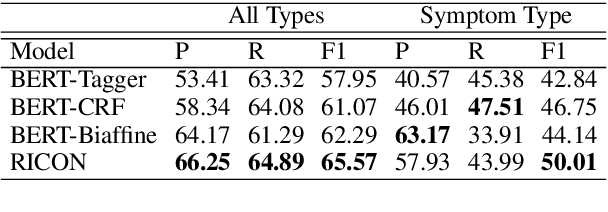
Recent years have witnessed the improving performance of Chinese Named Entity Recognition (NER) from proposing new frameworks or incorporating word lexicons. However, the inner composition of entity mentions in character-level Chinese NER has been rarely studied. Actually, most mentions of regular types have strong name regularity. For example, entities end with indicator words such as "company" or "bank" usually belong to organization. In this paper, we propose a simple but effective method for investigating the regularity of entity spans in Chinese NER, dubbed as Regularity-Inspired reCOgnition Network (RICON). Specifically, the proposed model consists of two branches: a regularity-aware module and a regularityagnostic module. The regularity-aware module captures the internal regularity of each span for better entity type prediction, while the regularity-agnostic module is employed to locate the boundary of entities and relieve the excessive attention to span regularity. An orthogonality space is further constructed to encourage two modules to extract different aspects of regularity features. To verify the effectiveness of our method, we conduct extensive experiments on three benchmark datasets and a practical medical dataset. The experimental results show that our RICON significantly outperforms previous state-of-the-art methods, including various lexicon-based methods.
Multi-Modal Knowledge Graph Construction and Application: A Survey
Feb 11, 2022



Recent years have witnessed the resurgence of knowledge engineering which is featured by the fast growth of knowledge graphs. However, most of existing knowledge graphs are represented with pure symbols, which hurts the machine's capability to understand the real world. The multi-modalization of knowledge graphs is an inevitable key step towards the realization of human-level machine intelligence. The results of this endeavor are Multi-modal Knowledge Graphs (MMKGs). In this survey on MMKGs constructed by texts and images, we first give definitions of MMKGs, followed with the preliminaries on multi-modal tasks and techniques. We then systematically review the challenges, progresses and opportunities on the construction and application of MMKGs respectively, with detailed analyses of the strength and weakness of different solutions. We finalize this survey with open research problems relevant to MMKGs.
Efficient Document-level Event Extraction via Pseudo-Trigger-aware Pruned Complete Graph
Dec 11, 2021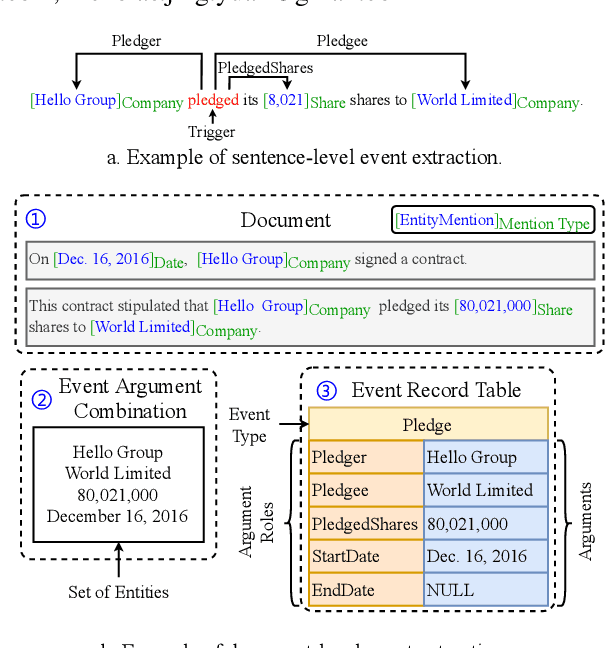
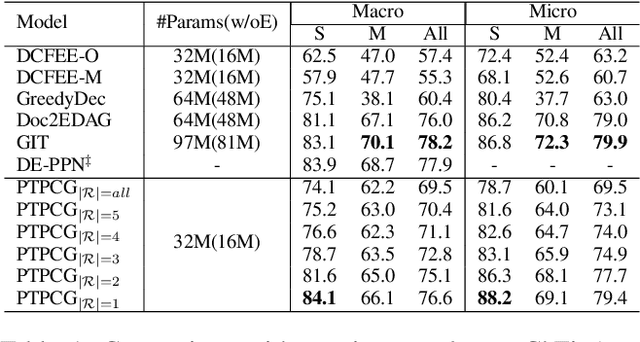
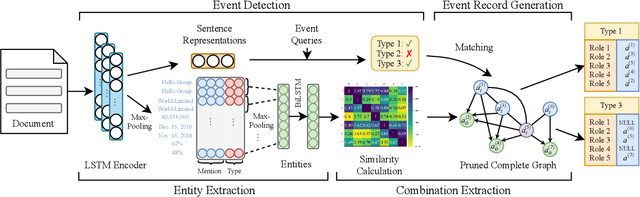
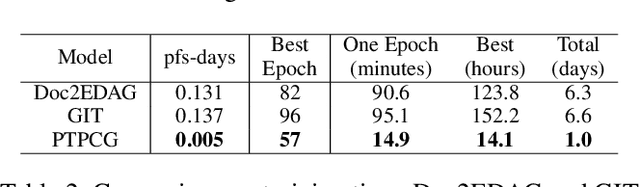
There are two main challenges in document-level event extraction: 1) argument entities are scattered in different sentences, and 2) event triggers are often not available. To address these challenges, most previous studies mainly focus on building argument chains in an autoregressive way, which is inefficient in both training and inference. In contrast to the previous studies, we propose a fast and lightweight model named as PTPCG. We design a non-autoregressive decoding algorithm to perform event argument combination extraction on pruned complete graphs, which are constructed under the guidance of the automatically selected pseudo triggers. Compared to the previous systems, our system achieves competitive results with lower resource consumption, taking only 3.6% GPU time (pfs-days) for training and up to 8.5 times faster for inference. Besides, our approach shows superior compatibility for the datasets with (or without) triggers and the pseudo triggers can be the supplements for annotated triggers to make further improvements.