 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdacc: Adaptive Compression and Activation Checkpointing for LLM Memory Management
Aug 01, 2025Training large language models often employs recomputation to alleviate memory pressure, which can introduce up to 30% overhead in real-world scenarios. In this paper, we propose Adacc, a novel memory management framework that combines adaptive compression and activation checkpointing to reduce the GPU memory footprint. It comprises three modules: (1) We design layer-specific compression algorithms that account for outliers in LLM tensors, instead of directly quantizing floats from FP16 to INT4, to ensure model accuracy. (2) We propose an optimal scheduling policy that employs MILP to determine the best memory optimization for each tensor. (3) To accommodate changes in training tensors, we introduce an adaptive policy evolution mechanism that adjusts the policy during training to enhance throughput. Experimental results show that Adacc can accelerate the LLM training by 1.01x to 1.37x compared to state-of-the-art frameworks, while maintaining comparable model accuracy to the Baseline.
Alignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025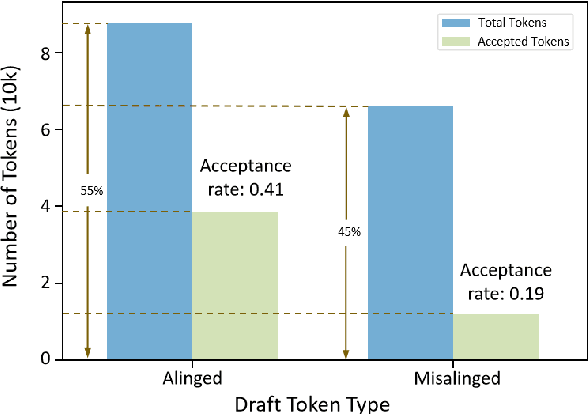
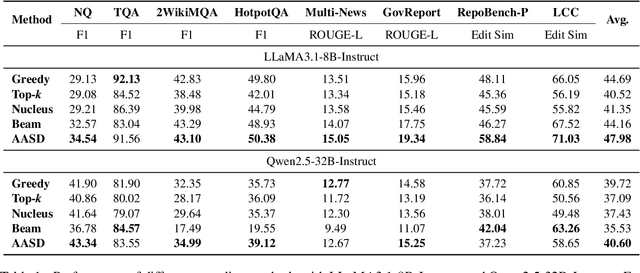
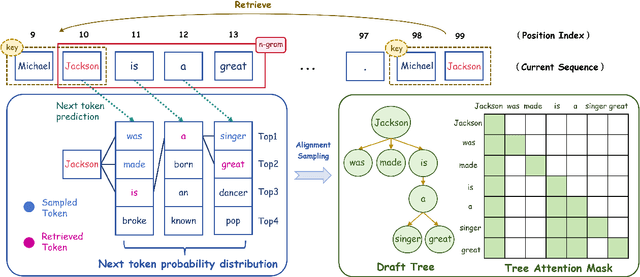
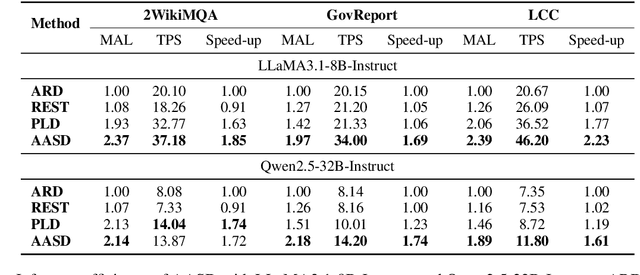
Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025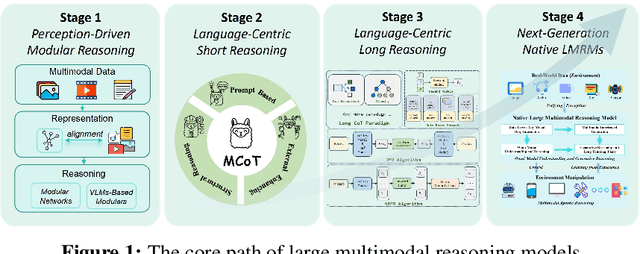
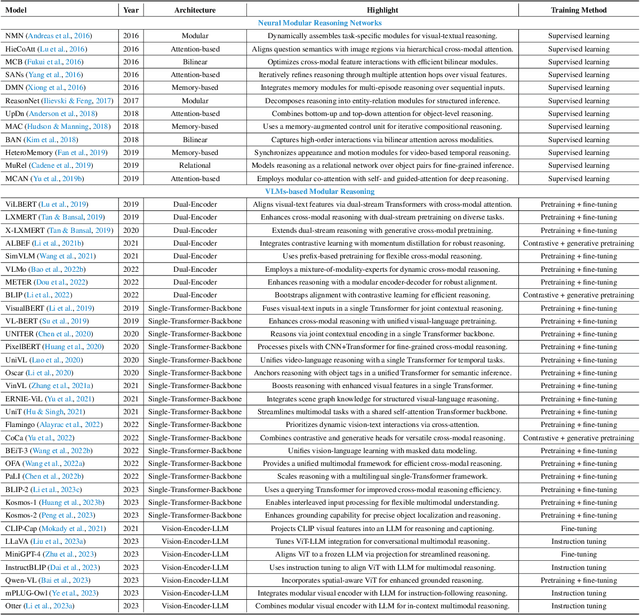
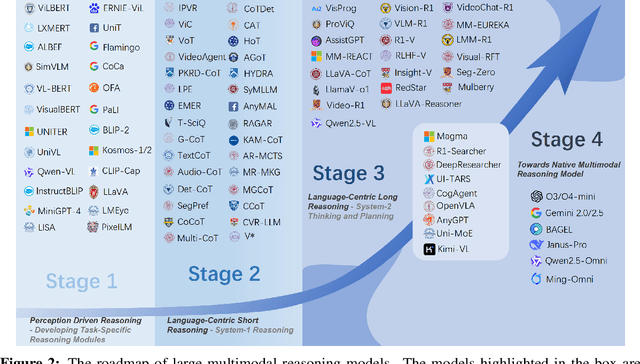
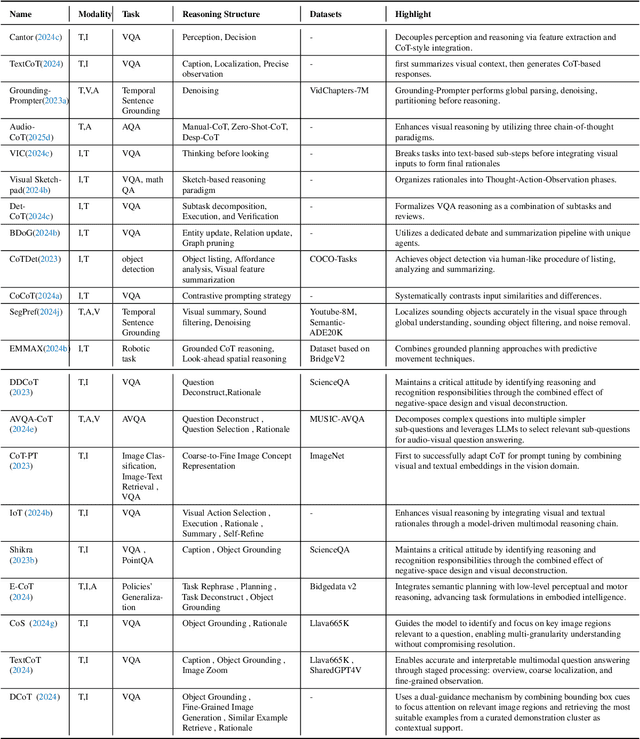
Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
Taming the Titans: A Survey of Efficient LLM Inference Serving
Apr 28, 2025Large Language Models (LLMs) for Generative AI have achieved remarkable progress, evolving into sophisticated and versatile tools widely adopted across various domains and applications. However, the substantial memory overhead caused by their vast number of parameters, combined with the high computational demands of the attention mechanism, poses significant challenges in achieving low latency and high throughput for LLM inference services. Recent advancements, driven by groundbreaking research, have significantly accelerated progress in this field. This paper provides a comprehensive survey of these methods, covering fundamental instance-level approaches, in-depth cluster-level strategies, emerging scenario directions, and other miscellaneous but important areas. At the instance level, we review model placement, request scheduling, decoding length prediction, storage management, and the disaggregation paradigm. At the cluster level, we explore GPU cluster deployment, multi-instance load balancing, and cloud service solutions. For emerging scenarios, we organize the discussion around specific tasks, modules, and auxiliary methods. To ensure a holistic overview, we also highlight several niche yet critical areas. Finally, we outline potential research directions to further advance the field of LLM inference serving.
MSceneSpeech: A Multi-Scene Speech Dataset For Expressive Speech Synthesis
Jul 19, 2024



We introduce an open source high-quality Mandarin TTS dataset MSceneSpeech (Multiple Scene Speech Dataset), which is intended to provide resources for expressive speech synthesis. MSceneSpeech comprises numerous audio recordings and texts performed and recorded according to daily life scenarios. Each scenario includes multiple speakers and a diverse range of prosodic styles, making it suitable for speech synthesis that entails multi-speaker style and prosody modeling. We have established a robust baseline, through the prompting mechanism, that can effectively synthesize speech characterized by both user-specific timbre and scene-specific prosody with arbitrary text input. The open source MSceneSpeech Dataset and audio samples of our baseline are available at https://speechai-demo.github.io/MSceneSpeech/.
A General and Flexible Multi-concept Parsing Framework for Multilingual Semantic Matching
Mar 05, 2024



Sentence semantic matching is a research hotspot in natural language processing, which is considerably significant in various key scenarios, such as community question answering, searching, chatbot, and recommendation. Since most of the advanced models directly model the semantic relevance among words between two sentences while neglecting the \textit{keywords} and \textit{intents} concepts of them, DC-Match is proposed to disentangle keywords from intents and utilizes them to optimize the matching performance. Although DC-Match is a simple yet effective method for semantic matching, it highly depends on the external NER techniques to identify the keywords of sentences, which limits the performance of semantic matching for minor languages since satisfactory NER tools are usually hard to obtain. In this paper, we propose to generally and flexibly resolve the text into multi concepts for multilingual semantic matching to liberate the model from the reliance on NER models. To this end, we devise a \underline{M}ulti-\underline{C}oncept \underline{P}arsed \underline{S}emantic \underline{M}atching framework based on the pre-trained language models, abbreviated as \textbf{MCP-SM}, to extract various concepts and infuse them into the classification tokens. We conduct comprehensive experiments on English datasets QQP and MRPC, and Chinese dataset Medical-SM. Besides, we experiment on Arabic datasets MQ2Q and XNLI, the outstanding performance further prove MCP-SM's applicability in low-resource languages.
StyleSinger: Style Transfer for Out-of-Domain Singing Voice Synthesis
Jan 02, 2024
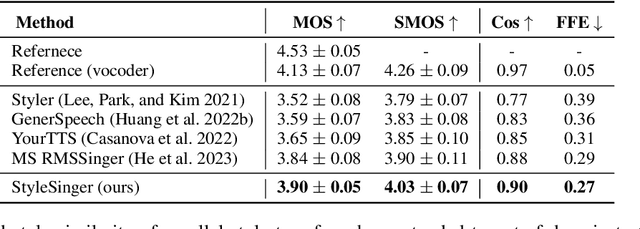

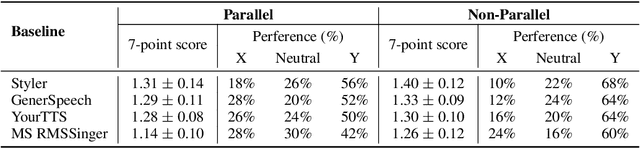
Style transfer for out-of-domain (OOD) singing voice synthesis (SVS) focuses on generating high-quality singing voices with unseen styles (such as timbre, emotion, pronunciation, and articulation skills) derived from reference singing voice samples. However, the endeavor to model the intricate nuances of singing voice styles is an arduous task, as singing voices possess a remarkable degree of expressiveness. Moreover, existing SVS methods encounter a decline in the quality of synthesized singing voices in OOD scenarios, as they rest upon the assumption that the target vocal attributes are discernible during the training phase. To overcome these challenges, we propose StyleSinger, the first singing voice synthesis model for zero-shot style transfer of out-of-domain reference singing voice samples. StyleSinger incorporates two critical approaches for enhanced effectiveness: 1) the Residual Style Adaptor (RSA) which employs a residual quantization module to capture diverse style characteristics in singing voices, and 2) the Uncertainty Modeling Layer Normalization (UMLN) to perturb the style attributes within the content representation during the training phase and thus improve the model generalization. Our extensive evaluations in zero-shot style transfer undeniably establish that StyleSinger outperforms baseline models in both audio quality and similarity to the reference singing voice samples. Access to singing voice samples can be found at https://stylesinger.github.io/.
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 26, 2023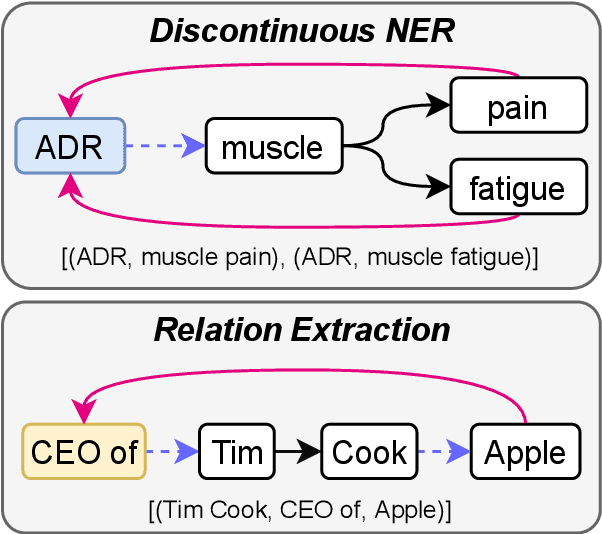
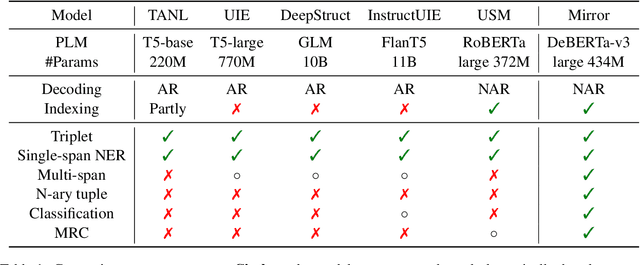

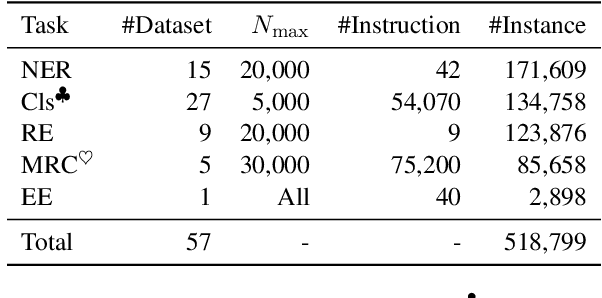
Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
TextrolSpeech: A Text Style Control Speech Corpus With Codec Language Text-to-Speech Models
Aug 28, 2023



Recently, there has been a growing interest in the field of controllable Text-to-Speech (TTS). While previous studies have relied on users providing specific style factor values based on acoustic knowledge or selecting reference speeches that meet certain requirements, generating speech solely from natural text prompts has emerged as a new challenge for researchers. This challenge arises due to the scarcity of high-quality speech datasets with natural text style prompt and the absence of advanced text-controllable TTS models. In light of this, 1) we propose TextrolSpeech, which is the first large-scale speech emotion dataset annotated with rich text attributes. The dataset comprises 236,220 pairs of style prompt in natural text descriptions with five style factors and corresponding speech samples. Through iterative experimentation, we introduce a multi-stage prompt programming approach that effectively utilizes the GPT model for generating natural style descriptions in large volumes. 2) Furthermore, to address the need for generating audio with greater style diversity, we propose an efficient architecture called Salle. This architecture treats text controllable TTS as a language model task, utilizing audio codec codes as an intermediate representation to replace the conventional mel-spectrogram. Finally, we successfully demonstrate the ability of the proposed model by showing a comparable performance in the controllable TTS task. Audio samples are available at https://sall-e.github.io/
Recognizing Unseen Objects via Multimodal Intensive Knowledge Graph Propagation
Jun 21, 2023



Zero-Shot Learning (ZSL), which aims at automatically recognizing unseen objects, is a promising learning paradigm to understand new real-world knowledge for machines continuously. Recently, the Knowledge Graph (KG) has been proven as an effective scheme for handling the zero-shot task with large-scale and non-attribute data. Prior studies always embed relationships of seen and unseen objects into visual information from existing knowledge graphs to promote the cognitive ability of the unseen data. Actually, real-world knowledge is naturally formed by multimodal facts. Compared with ordinary structural knowledge from a graph perspective, multimodal KG can provide cognitive systems with fine-grained knowledge. For example, the text description and visual content can depict more critical details of a fact than only depending on knowledge triplets. Unfortunately, this multimodal fine-grained knowledge is largely unexploited due to the bottleneck of feature alignment between different modalities. To that end, we propose a multimodal intensive ZSL framework that matches regions of images with corresponding semantic embeddings via a designed dense attention module and self-calibration loss. It makes the semantic transfer process of our ZSL framework learns more differentiated knowledge between entities. Our model also gets rid of the performance limitation of only using rough global features. We conduct extensive experiments and evaluate our model on large-scale real-world data. The experimental results clearly demonstrate the effectiveness of the proposed model in standard zero-shot classification tasks.