 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheMatAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 12, 2025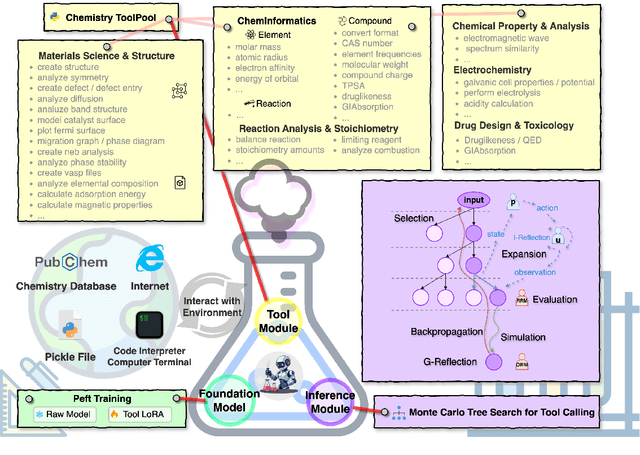
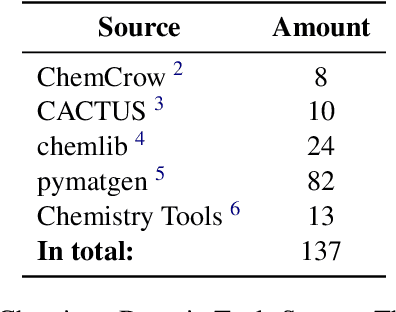
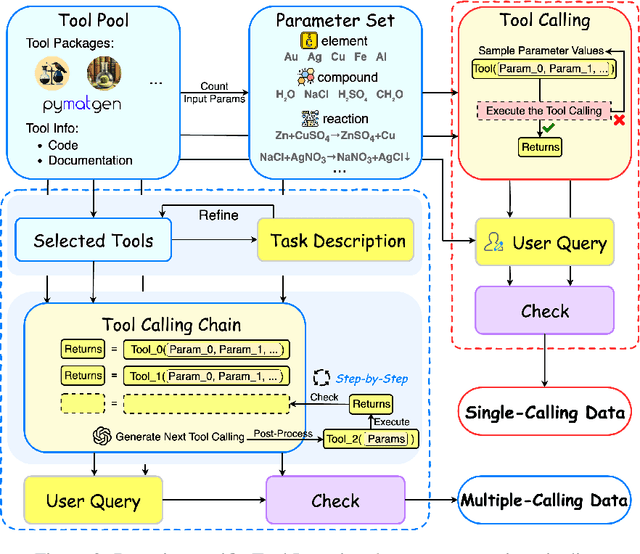
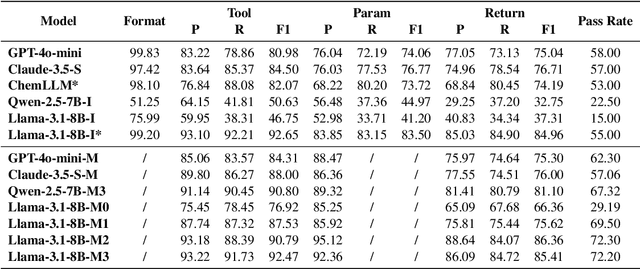
Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
ChemAgent: Enhancing LLMs for Chemistry and Materials Science through Tree-Search Based Tool Learning
Jun 09, 2025Large language models (LLMs) have recently demonstrated promising capabilities in chemistry tasks while still facing challenges due to outdated pretraining knowledge and the difficulty of incorporating specialized chemical expertise. To address these issues, we propose an LLM-based agent that synergistically integrates 137 external chemical tools created ranging from basic information retrieval to complex reaction predictions, and a dataset curation pipeline to generate the dataset ChemToolBench that facilitates both effective tool selection and precise parameter filling during fine-tuning and evaluation. We introduce a Hierarchical Evolutionary Monte Carlo Tree Search (HE-MCTS) framework, enabling independent optimization of tool planning and execution. By leveraging self-generated data, our approach supports step-level fine-tuning (FT) of the policy model and training task-adaptive PRM and ORM that surpass GPT-4o. Experimental evaluations demonstrate that our approach significantly improves performance in Chemistry QA and discovery tasks, offering a robust solution to integrate specialized tools with LLMs for advanced chemical applications. All datasets and code are available at https://github.com/AI4Chem/ChemistryAgent .
SELT: Self-Evaluation Tree Search for LLMs with Task Decomposition
Jun 09, 2025While Large Language Models (LLMs) have achieved remarkable success in a wide range of applications, their performance often degrades in complex reasoning tasks. In this work, we introduce SELT (Self-Evaluation LLM Tree Search), a novel framework that leverages a modified Monte Carlo Tree Search (MCTS) to enhance LLM reasoning without relying on external reward models. By redefining the Upper Confidence Bound scoring to align with intrinsic self-evaluation capabilities of LLMs and decomposing the inference process into atomic subtasks augmented with semantic clustering at each node, SELT effectively balances exploration and exploitation, reduces redundant reasoning paths, and mitigates hallucination. We validate our approach on challenging benchmarks, including the knowledge-based MMLU and the Tool Learning dataset Seal-Tools, where SELT achieves significant improvements in answer accuracy and reasoning robustness compared to baseline methods. Notably, our framework operates without task-specific fine-tuning, demonstrating strong generalizability across diverse reasoning tasks. Relevant results and code are available at https://github.com/fairyshine/SELT .
Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Mar 21, 2025Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/fairyshine/Chain-of-Tools .
NesTools: A Dataset for Evaluating Nested Tool Learning Abilities of Large Language Models
Oct 15, 2024Large language models (LLMs) combined with tool learning have gained impressive results in real-world applications. During tool learning, LLMs may call multiple tools in nested orders, where the latter tool call may take the former response as its input parameters. However, current research on the nested tool learning capabilities is still under-explored, since the existing benchmarks lack of relevant data instances. To address this problem, we introduce NesTools to bridge the current gap in comprehensive nested tool learning evaluations. NesTools comprises a novel automatic data generation method to construct large-scale nested tool calls with different nesting structures. With manual review and refinement, the dataset is in high quality and closely aligned with real-world scenarios. Therefore, NesTools can serve as a new benchmark to evaluate the nested tool learning abilities of LLMs. We conduct extensive experiments on 22 LLMs, and provide in-depth analyses with NesTools, which shows that current LLMs still suffer from the complex nested tool learning task.
Seal-Tools: Self-Instruct Tool Learning Dataset for Agent Tuning and Detailed Benchmark
May 14, 2024This paper presents a new tool learning dataset Seal-Tools, which contains self-instruct API-like tools. Seal-Tools not only offers a large number of tools, but also includes instances which demonstrate the practical application of tools. Seeking to generate data on a large scale while ensuring reliability, we propose a self-instruct method to generate tools and instances, allowing precise control over the process. Moreover, our Seal-Tools contains hard instances that call multiple tools to complete the job, among which some are nested tool callings. For precise and comprehensive evaluation, we use strict format control and design three metrics from different dimensions. Therefore, Seal-Tools can serve as a new benchmark to evaluate the tool-calling ability of LLMs. Finally, we evaluate several prevalent LLMs and our finetuned model on Seal-Tools. The results show that current systems are far from perfect. The code, data and experiment results are available at https://github.com/fairyshine/Seal-Tools .
Mirror: A Universal Framework for Various Information Extraction Tasks
Nov 26, 2023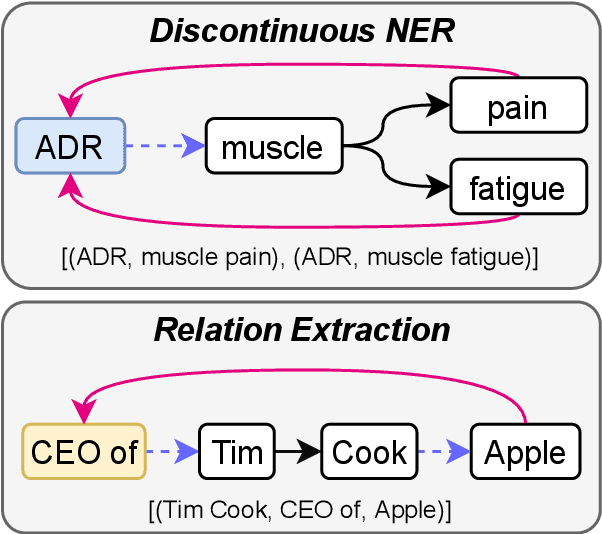
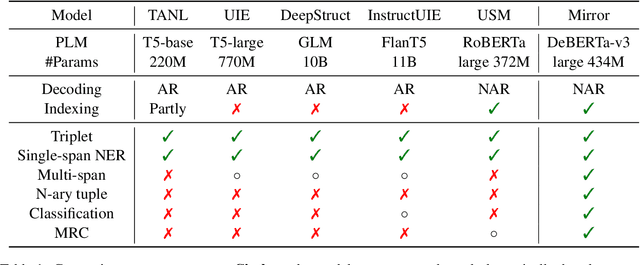

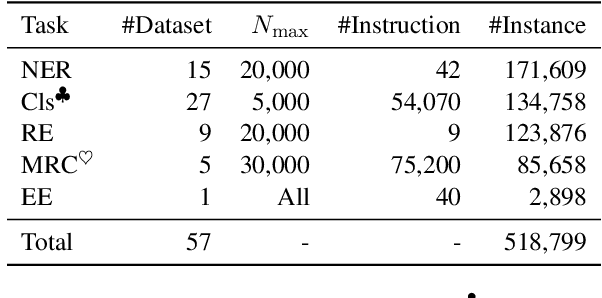
Sharing knowledge between information extraction tasks has always been a challenge due to the diverse data formats and task variations. Meanwhile, this divergence leads to information waste and increases difficulties in building complex applications in real scenarios. Recent studies often formulate IE tasks as a triplet extraction problem. However, such a paradigm does not support multi-span and n-ary extraction, leading to weak versatility. To this end, we reorganize IE problems into unified multi-slot tuples and propose a universal framework for various IE tasks, namely Mirror. Specifically, we recast existing IE tasks as a multi-span cyclic graph extraction problem and devise a non-autoregressive graph decoding algorithm to extract all spans in a single step. It is worth noting that this graph structure is incredibly versatile, and it supports not only complex IE tasks, but also machine reading comprehension and classification tasks. We manually construct a corpus containing 57 datasets for model pretraining, and conduct experiments on 30 datasets across 8 downstream tasks. The experimental results demonstrate that our model has decent compatibility and outperforms or reaches competitive performance with SOTA systems under few-shot and zero-shot settings. The code, model weights, and pretraining corpus are available at https://github.com/Spico197/Mirror .
CED: Catalog Extraction from Documents
Apr 28, 2023



Sentence-by-sentence information extraction from long documents is an exhausting and error-prone task. As the indicator of document skeleton, catalogs naturally chunk documents into segments and provide informative cascade semantics, which can help to reduce the search space. Despite their usefulness, catalogs are hard to be extracted without the assist from external knowledge. For documents that adhere to a specific template, regular expressions are practical to extract catalogs. However, handcrafted heuristics are not applicable when processing documents from different sources with diverse formats. To address this problem, we build a large manually annotated corpus, which is the first dataset for the Catalog Extraction from Documents (CED) task. Based on this corpus, we propose a transition-based framework for parsing documents into catalog trees. The experimental results demonstrate that our proposed method outperforms baseline systems and shows a good ability to transfer. We believe the CED task could fill the gap between raw text segments and information extraction tasks on extremely long documents. Data and code are available at \url{https://github.com/Spico197/CatalogExtraction}