 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Preference Optimization (RPO): Enhancing On-Policy Alignment via Hint-Guided Reflection
Dec 15, 2025Direct Preference Optimization (DPO) has emerged as a lightweight and effective alternative to Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning with AI Feedback (RLAIF) for aligning large language and vision-language models. However, the standard DPO formulation, in which both the chosen and rejected responses are generated by the same policy, suffers from a weak learning signal because the two responses often share similar errors and exhibit small Kullback-Leibler (KL) divergence. This leads to slow and unstable convergence. To address this limitation, we introduce Reflective Preference Optimization (RPO), a new framework that incorporates hint-guided reflection into the DPO paradigm. RPO uses external models to identify hallucination sources and generate concise reflective hints, enabling the construction of on-policy preference pairs with stronger contrastiveness and clearer preference signals. We theoretically show that conditioning on hints increases the expected preference margin through mutual information and improves sample efficiency while remaining within the policy distribution family. Empirically, RPO achieves superior alignment with fewer training samples and iterations, substantially reducing hallucination rates and delivering state-of-the-art performance across multimodal benchmarks.
CED: Catalog Extraction from Documents
Apr 28, 2023



Sentence-by-sentence information extraction from long documents is an exhausting and error-prone task. As the indicator of document skeleton, catalogs naturally chunk documents into segments and provide informative cascade semantics, which can help to reduce the search space. Despite their usefulness, catalogs are hard to be extracted without the assist from external knowledge. For documents that adhere to a specific template, regular expressions are practical to extract catalogs. However, handcrafted heuristics are not applicable when processing documents from different sources with diverse formats. To address this problem, we build a large manually annotated corpus, which is the first dataset for the Catalog Extraction from Documents (CED) task. Based on this corpus, we propose a transition-based framework for parsing documents into catalog trees. The experimental results demonstrate that our proposed method outperforms baseline systems and shows a good ability to transfer. We believe the CED task could fill the gap between raw text segments and information extraction tasks on extremely long documents. Data and code are available at \url{https://github.com/Spico197/CatalogExtraction}
A Survey on Arabic Named Entity Recognition: Past, Recent Advances, and Future Trends
Feb 08, 2023



As more and more Arabic texts emerged on the Internet, extracting important information from these Arabic texts is especially useful. As a fundamental technology, Named entity recognition (NER) serves as the core component in information extraction technology, while also playing a critical role in many other Natural Language Processing (NLP) systems, such as question answering and knowledge graph building. In this paper, we provide a comprehensive review of the development of Arabic NER, especially the recent advances in deep learning and pre-trained language model. Specifically, we first introduce the background of Arabic NER, including the characteristics of Arabic and existing resources for Arabic NER. Then, we systematically review the development of Arabic NER methods. Traditional Arabic NER systems focus on feature engineering and designing domain-specific rules. In recent years, deep learning methods achieve significant progress by representing texts via continuous vector representations. With the growth of pre-trained language model, Arabic NER yields better performance. Finally, we conclude the method gap between Arabic NER and NER methods from other languages, which helps outline future directions for Arabic NER.
Domain Adaptation for Semantic Parsing
Jun 23, 2020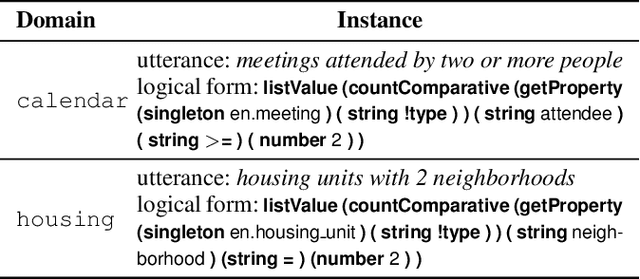
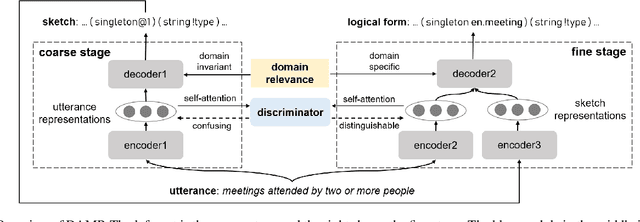
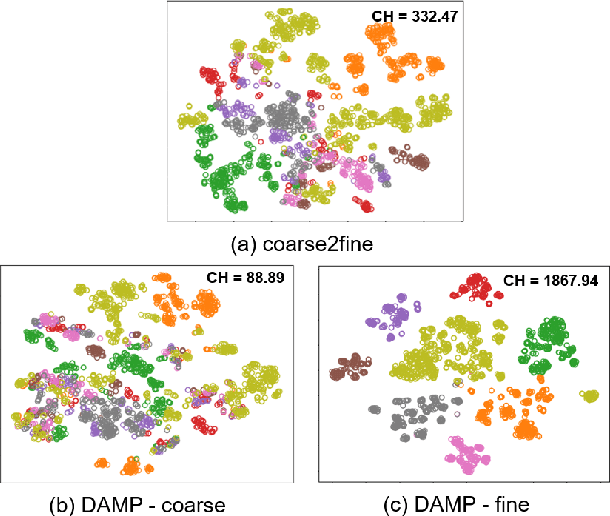
Recently, semantic parsing has attracted much attention in the community. Although many neural modeling efforts have greatly improved the performance, it still suffers from the data scarcity issue. In this paper, we propose a novel semantic parser for domain adaptation, where we have much fewer annotated data in the target domain compared to the source domain. Our semantic parser benefits from a two-stage coarse-to-fine framework, thus can provide different and accurate treatments for the two stages, i.e., focusing on domain invariant and domain specific information, respectively. In the coarse stage, our novel domain discrimination component and domain relevance attention encourage the model to learn transferable domain general structures. In the fine stage, the model is guided to concentrate on domain related details. Experiments on a benchmark dataset show that our method consistently outperforms several popular domain adaptation strategies. Additionally, we show that our model can well exploit limited target data to capture the difference between the source and target domain, even when the target domain has far fewer training instances.
A Sketch-Based System for Semantic Parsing
Sep 12, 2019
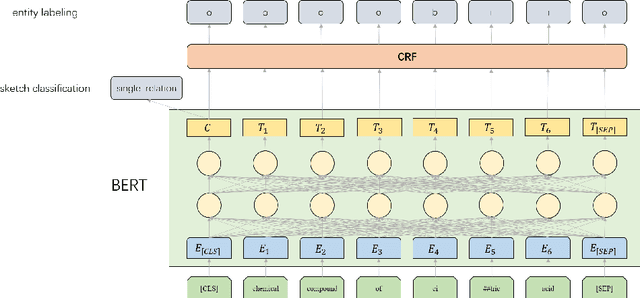


This paper presents our semantic parsing system for the evaluation task of open domain semantic parsing in NLPCC 2019. Many previous works formulate semantic parsing as a sequence-to-sequence(seq2seq) problem. Instead, we treat the task as a sketch-based problem in a coarse-to-fine(coarse2fine) fashion. The sketch is a high-level structure of the logical form exclusive of low-level details such as entities and predicates. In this way, we are able to optimize each part individually. Specifically, we decompose the process into three stages: the sketch classification determines the high-level structure while the entity labeling and the matching network fill in missing details. Moreover, we adopt the seq2seq method to evaluate logical form candidates from an overall perspective. The co-occurrence relationship between predicates and entities contribute to the reranking as well. Our submitted system achieves the exactly matching accuracy of 82.53% on full test set and 47.83% on hard test subset, which is the 3rd place in NLPCC 2019 Shared Task 2. After optimizations for parameters, network structure and sampling, the accuracy reaches 84.47% on full test set and 63.08% on hard test subset(Our code and data are available at https://github.com/zechagl/NLPCC2019-Semantic-Parsing).