 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment-Augmented Speculative Decoding with Alignment Sampling and Conditional Verification
May 19, 2025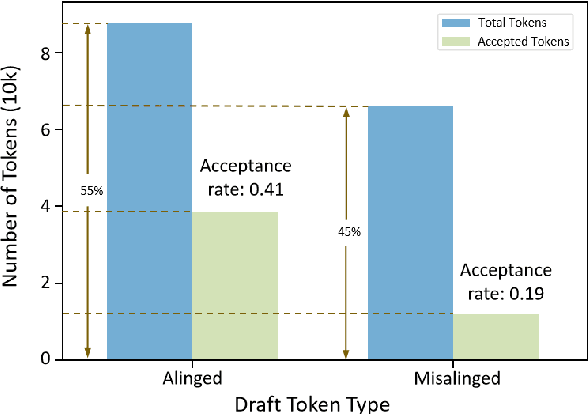
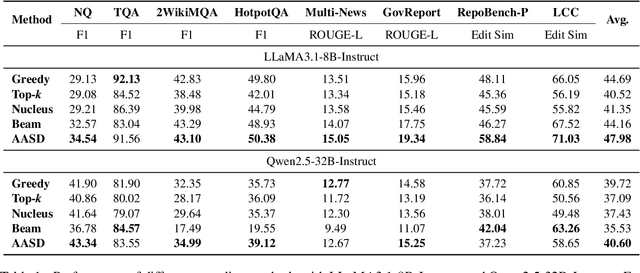
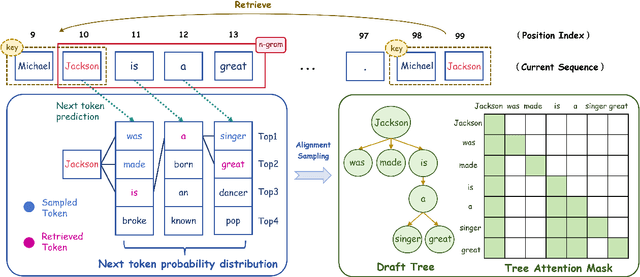
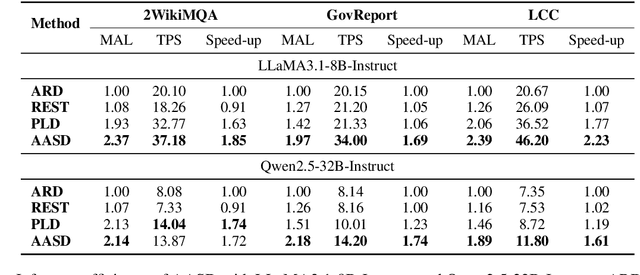
Recent works have revealed the great potential of speculative decoding in accelerating the autoregressive generation process of large language models. The success of these methods relies on the alignment between draft candidates and the sampled outputs of the target model. Existing methods mainly achieve draft-target alignment with training-based methods, e.g., EAGLE, Medusa, involving considerable training costs. In this paper, we present a training-free alignment-augmented speculative decoding algorithm. We propose alignment sampling, which leverages output distribution obtained in the prefilling phase to provide more aligned draft candidates. To further benefit from high-quality but non-aligned draft candidates, we also introduce a simple yet effective flexible verification strategy. Through an adaptive probability threshold, our approach can improve generation accuracy while further improving inference efficiency. Experiments on 8 datasets (including question answering, summarization and code completion tasks) show that our approach increases the average generation score by 3.3 points for the LLaMA3 model. Our method achieves a mean acceptance length up to 2.39 and speed up generation by 2.23.
Accurate KV Cache Quantization with Outlier Tokens Tracing
May 16, 2025The impressive capabilities of Large Language Models (LLMs) come at the cost of substantial computational resources during deployment. While KV Cache can significantly reduce recomputation during inference, it also introduces additional memory overhead. KV Cache quantization presents a promising solution, striking a good balance between memory usage and accuracy. Previous research has shown that the Keys are distributed by channel, while the Values are distributed by token. Consequently, the common practice is to apply channel-wise quantization to the Keys and token-wise quantization to the Values. However, our further investigation reveals that a small subset of unusual tokens exhibit unique characteristics that deviate from this pattern, which can substantially impact quantization accuracy. To address this, we develop a simple yet effective method to identify these tokens accurately during the decoding process and exclude them from quantization as outlier tokens, significantly improving overall accuracy. Extensive experiments show that our method achieves significant accuracy improvements under 2-bit quantization and can deliver a 6.4 times reduction in memory usage and a 2.3 times increase in throughput.
Taming the Titans: A Survey of Efficient LLM Inference Serving
Apr 28, 2025Large Language Models (LLMs) for Generative AI have achieved remarkable progress, evolving into sophisticated and versatile tools widely adopted across various domains and applications. However, the substantial memory overhead caused by their vast number of parameters, combined with the high computational demands of the attention mechanism, poses significant challenges in achieving low latency and high throughput for LLM inference services. Recent advancements, driven by groundbreaking research, have significantly accelerated progress in this field. This paper provides a comprehensive survey of these methods, covering fundamental instance-level approaches, in-depth cluster-level strategies, emerging scenario directions, and other miscellaneous but important areas. At the instance level, we review model placement, request scheduling, decoding length prediction, storage management, and the disaggregation paradigm. At the cluster level, we explore GPU cluster deployment, multi-instance load balancing, and cloud service solutions. For emerging scenarios, we organize the discussion around specific tasks, modules, and auxiliary methods. To ensure a holistic overview, we also highlight several niche yet critical areas. Finally, we outline potential research directions to further advance the field of LLM inference serving.
Beware of Calibration Data for Pruning Large Language Models
Oct 23, 2024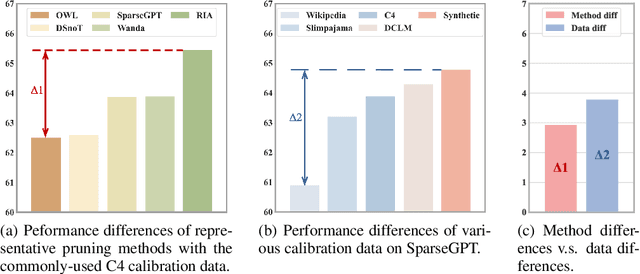

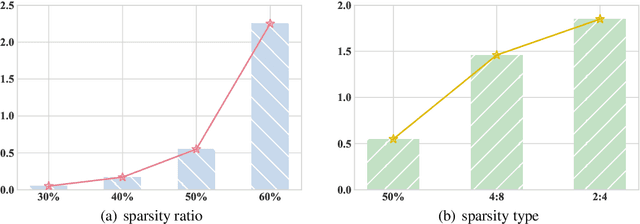

As large language models (LLMs) are widely applied across various fields, model compression has become increasingly crucial for reducing costs and improving inference efficiency. Post-training pruning is a promising method that does not require resource-intensive iterative training and only needs a small amount of calibration data to assess the importance of parameters. Previous research has primarily focused on designing advanced pruning methods, while different calibration data's impact on pruning performance still lacks systematical exploration. We fill this blank and surprisingly observe that the effects of calibration data even value more than designing advanced pruning strategies, especially for high sparsity. Our preliminary exploration also discloses that using calibration data similar to the training data can yield better performance. As pre-training data is usually inaccessible for advanced LLMs, we further provide a self-generating calibration data synthesis strategy to construct feasible calibration data. We conduct experiments on the recent strong open-source LLMs (e.g., DCLM, and LLaMA-3), and the results show that the proposed method outperforms commonly used calibration data and can effectively enhance strong pruning methods (e.g., Wanda, OWL).
A General and Flexible Multi-concept Parsing Framework for Multilingual Semantic Matching
Mar 05, 2024



Sentence semantic matching is a research hotspot in natural language processing, which is considerably significant in various key scenarios, such as community question answering, searching, chatbot, and recommendation. Since most of the advanced models directly model the semantic relevance among words between two sentences while neglecting the \textit{keywords} and \textit{intents} concepts of them, DC-Match is proposed to disentangle keywords from intents and utilizes them to optimize the matching performance. Although DC-Match is a simple yet effective method for semantic matching, it highly depends on the external NER techniques to identify the keywords of sentences, which limits the performance of semantic matching for minor languages since satisfactory NER tools are usually hard to obtain. In this paper, we propose to generally and flexibly resolve the text into multi concepts for multilingual semantic matching to liberate the model from the reliance on NER models. To this end, we devise a \underline{M}ulti-\underline{C}oncept \underline{P}arsed \underline{S}emantic \underline{M}atching framework based on the pre-trained language models, abbreviated as \textbf{MCP-SM}, to extract various concepts and infuse them into the classification tokens. We conduct comprehensive experiments on English datasets QQP and MRPC, and Chinese dataset Medical-SM. Besides, we experiment on Arabic datasets MQ2Q and XNLI, the outstanding performance further prove MCP-SM's applicability in low-resource languages.
AraMUS: Pushing the Limits of Data and Model Scale for Arabic Natural Language Processing
Jun 11, 2023Developing monolingual large Pre-trained Language Models (PLMs) is shown to be very successful in handling different tasks in Natural Language Processing (NLP). In this work, we present AraMUS, the largest Arabic PLM with 11B parameters trained on 529GB of high-quality Arabic textual data. AraMUS achieves state-of-the-art performances on a diverse set of Arabic classification and generative tasks. Moreover, AraMUS shows impressive few-shot learning abilities compared with the best existing Arabic PLMs.
A Survey on Arabic Named Entity Recognition: Past, Recent Advances, and Future Trends
Feb 08, 2023



As more and more Arabic texts emerged on the Internet, extracting important information from these Arabic texts is especially useful. As a fundamental technology, Named entity recognition (NER) serves as the core component in information extraction technology, while also playing a critical role in many other Natural Language Processing (NLP) systems, such as question answering and knowledge graph building. In this paper, we provide a comprehensive review of the development of Arabic NER, especially the recent advances in deep learning and pre-trained language model. Specifically, we first introduce the background of Arabic NER, including the characteristics of Arabic and existing resources for Arabic NER. Then, we systematically review the development of Arabic NER methods. Traditional Arabic NER systems focus on feature engineering and designing domain-specific rules. In recent years, deep learning methods achieve significant progress by representing texts via continuous vector representations. With the growth of pre-trained language model, Arabic NER yields better performance. Finally, we conclude the method gap between Arabic NER and NER methods from other languages, which helps outline future directions for Arabic NER.
MuCPAD: A Multi-Domain Chinese Predicate-Argument Dataset
May 13, 2022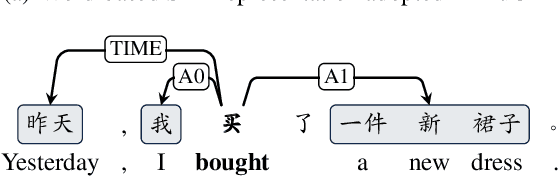


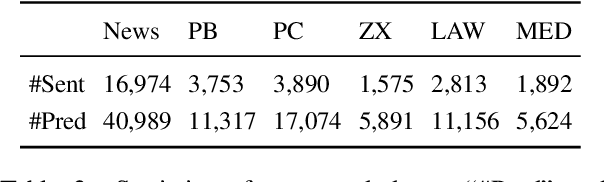
During the past decade, neural network models have made tremendous progress on in-domain semantic role labeling (SRL). However, performance drops dramatically under the out-of-domain setting. In order to facilitate research on cross-domain SRL, this paper presents MuCPAD, a multi-domain Chinese predicate-argument dataset, which consists of 30,897 sentences and 92,051 predicates from six different domains. MuCPAD exhibits three important features. 1) Based on a frame-free annotation methodology, we avoid writing complex frames for new predicates. 2) We explicitly annotate omitted core arguments to recover more complete semantic structure, considering that omission of content words is ubiquitous in multi-domain Chinese texts. 3) We compile 53 pages of annotation guidelines and adopt strict double annotation for improving data quality. This paper describes in detail the annotation methodology and annotation process of MuCPAD, and presents in-depth data analysis. We also give benchmark results on cross-domain SRL based on MuCPAD.
Fast and Accurate Span-based Semantic Role Labeling as Graph Parsing
Dec 06, 2021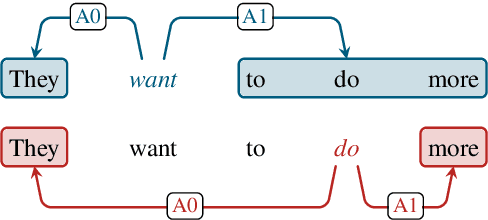
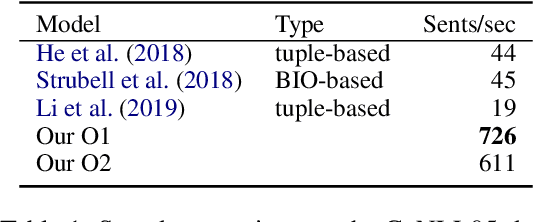
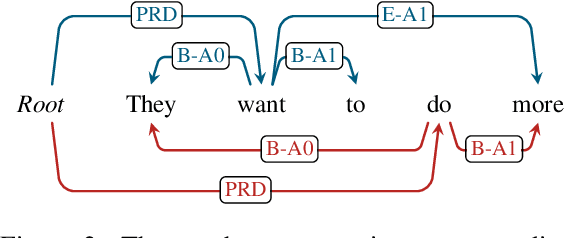
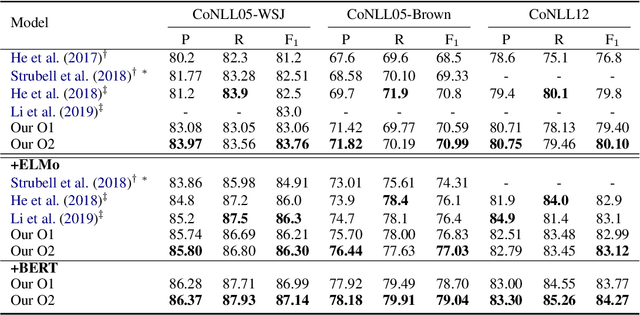
Currently, BIO-based and tuple-based approaches perform quite well on the span-based semantic role labeling (SRL) task. However, the BIO-based approach usually needs to encode a sentence once for each predicate when predicting its arguments, and the tuple-based approach has to deal with a huge search space of $O(n^3)$, greatly reducing the training and inference efficiency. The parsing speed is less than 50 sentences per second. Moreover, both BIO-based and tuple-based approaches usually consider only local structural information when making predictions. This paper proposes to cast end-to-end span-based SRL as a graph parsing task. Based on a novel graph representation schema, we present a fast and accurate SRL parser on the shoulder of recent works on high-order semantic dependency graph parsing. Moreover, we propose a constrained Viterbi procedure to ensure the legality of the output graph. Experiments on English CoNLL05 and CoNLL12 datasets show that our model achieves new state-of-the-art results under both settings of without and with pre-trained language models, and can parse over 600 sentences per second.
Semantic Role Labeling as Dependency Parsing: Exploring Latent Tree Structures Inside Arguments
Oct 13, 2021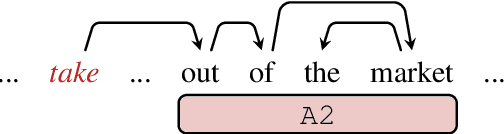

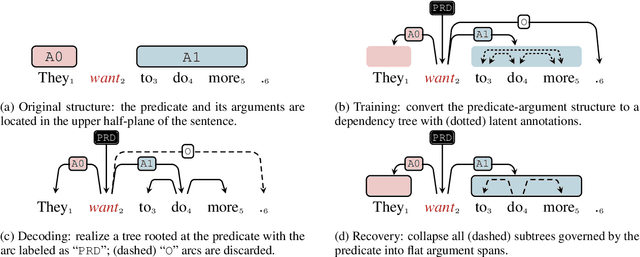

Semantic role labeling is a fundamental yet challenging task in the NLP community. Recent works of SRL mainly fall into two lines:1) BIO-based and 2) span-based. Despite effectiveness, they share some intrinsic drawbacks of not explicitly considering internal argument structures, which may potentially hinder the model's expressiveness. To remedy this, we propose to reduce SRL to a dependency parsing task and regard the flat argument spans as latent subtrees. In particular, we equip our formulation with a novel span-constrained TreeCRF model to make tree structures span-aware, and further extend it to the second-order case. Experiments on CoNLL05 and CoNLL12 benchmarks reveal that the results of our methods outperform all previous works and achieve the state-of-the-art.