 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaved Tool-Call Reasoning for Protein Function Understanding
Jan 07, 2026Recent advances in large language models (LLMs) have highlighted the effectiveness of chain-of-thought reasoning in symbolic domains such as mathematics and programming. However, our study shows that directly transferring such text-based reasoning paradigms to protein function understanding is ineffective: reinforcement learning mainly amplifies superficial keyword patterns while failing to introduce new biological knowledge, resulting in limited generalization. We argue that protein function prediction is a knowledge-intensive scientific task that fundamentally relies on external biological priors and computational tools rather than purely internal reasoning. To address this gap, we propose PFUA, a tool-augmented protein reasoning agent that unifies problem decomposition, tool invocation, and grounded answer generation. Instead of relying on long unconstrained reasoning traces, PFUA integrates domain-specific tools to produce verifiable intermediate evidence. Experiments on four benchmarks demonstrate that PFUA consistently outperforms text-only reasoning models with an average performance improvement of 103%.
HiEAG: Evidence-Augmented Generation for Out-of-Context Misinformation Detection
Nov 18, 2025Recent advancements in multimodal out-of-context (OOC) misinformation detection have made remarkable progress in checking the consistencies between different modalities for supporting or refuting image-text pairs. However, existing OOC misinformation detection methods tend to emphasize the role of internal consistency, ignoring the significant of external consistency between image-text pairs and external evidence. In this paper, we propose HiEAG, a novel Hierarchical Evidence-Augmented Generation framework to refine external consistency checking through leveraging the extensive knowledge of multimodal large language models (MLLMs). Our approach decomposes external consistency checking into a comprehensive engine pipeline, which integrates reranking and rewriting, apart from retrieval. Evidence reranking module utilizes Automatic Evidence Selection Prompting (AESP) that acquires the relevant evidence item from the products of evidence retrieval. Subsequently, evidence rewriting module leverages Automatic Evidence Generation Prompting (AEGP) to improve task adaptation on MLLM-based OOC misinformation detectors. Furthermore, our approach enables explanation for judgment, and achieves impressive performance with instruction tuning. Experimental results on different benchmark datasets demonstrate that our proposed HiEAG surpasses previous state-of-the-art (SOTA) methods in the accuracy over all samples.
MMD-Thinker: Adaptive Multi-Dimensional Thinking for Multimodal Misinformation Detection
Nov 17, 2025Multimodal misinformation floods on various social media, and continues to evolve in the era of AI-generated content (AIGC). The emerged misinformation with low creation cost and high deception poses significant threats to society. While recent studies leverage general-purpose multimodal large language models (MLLMs) to achieve remarkable results in detection, they encounter two critical limitations: (1) Insufficient reasoning, where general-purpose MLLMs often follow the uniform reasoning paradigm but generate inaccurate explanations and judgments, due to the lack of the task-specific knowledge of multimodal misinformation detection. (2) Reasoning biases, where a single thinking mode make detectors a suboptimal path for judgment, struggling to keep pace with the fast-growing and intricate multimodal misinformation. In this paper, we propose MMD-Thinker, a two-stage framework for multimodal misinformation detection through adaptive multi-dimensional thinking. First, we develop tailor-designed thinking mode for multimodal misinformation detection. Second, we adopt task-specific instruction tuning to inject the tailored thinking mode into general-purpose MLLMs. Third, we further leverage reinforcement learning strategy with a mixed advantage function, which incentivizes the reasoning capabilities in trajectories. Furthermore, we construct the multimodal misinformation reasoning (MMR) dataset, encompasses more than 8K image-text pairs with both reasoning processes and classification labels, to make progress in the relam of multimodal misinformation detection. Experimental results demonstrate that our proposed MMD-Thinker achieves state-of-the-art performance on both in-domain and out-of-domain benchmark datasets, while maintaining flexible inference and token usage. Code will be publicly available at Github.
Kimi Linear: An Expressive, Efficient Attention Architecture
Oct 30, 2025We introduce Kimi Linear, a hybrid linear attention architecture that, for the first time, outperforms full attention under fair comparisons across various scenarios -- including short-context, long-context, and reinforcement learning (RL) scaling regimes. At its core lies Kimi Delta Attention (KDA), an expressive linear attention module that extends Gated DeltaNet with a finer-grained gating mechanism, enabling more effective use of limited finite-state RNN memory. Our bespoke chunkwise algorithm achieves high hardware efficiency through a specialized variant of the Diagonal-Plus-Low-Rank (DPLR) transition matrices, which substantially reduces computation compared to the general DPLR formulation while remaining more consistent with the classical delta rule. We pretrain a Kimi Linear model with 3B activated parameters and 48B total parameters, based on a layerwise hybrid of KDA and Multi-Head Latent Attention (MLA). Our experiments show that with an identical training recipe, Kimi Linear outperforms full MLA with a sizeable margin across all evaluated tasks, while reducing KV cache usage by up to 75% and achieving up to 6 times decoding throughput for a 1M context. These results demonstrate that Kimi Linear can be a drop-in replacement for full attention architectures with superior performance and efficiency, including tasks with longer input and output lengths. To support further research, we open-source the KDA kernel and vLLM implementations, and release the pre-trained and instruction-tuned model checkpoints.
Multimodal Coreference Resolution for Chinese Social Media Dialogues: Dataset and Benchmark Approach
Apr 19, 2025Multimodal coreference resolution (MCR) aims to identify mentions referring to the same entity across different modalities, such as text and visuals, and is essential for understanding multimodal content. In the era of rapidly growing mutimodal content and social media, MCR is particularly crucial for interpreting user interactions and bridging text-visual references to improve communication and personalization. However, MCR research for real-world dialogues remains unexplored due to the lack of sufficient data resources.To address this gap, we introduce TikTalkCoref, the first Chinese multimodal coreference dataset for social media in real-world scenarios, derived from the popular Douyin short-video platform. This dataset pairs short videos with corresponding textual dialogues from user comments and includes manually annotated coreference clusters for both person mentions in the text and the coreferential person head regions in the corresponding video frames. We also present an effective benchmark approach for MCR, focusing on the celebrity domain, and conduct extensive experiments on our dataset, providing reliable benchmark results for this newly constructed dataset. We will release the TikTalkCoref dataset to facilitate future research on MCR for real-world social media dialogues.
APSeg: Auto-Prompt Model with Acquired and Injected Knowledge for Nuclear Instance Segmentation and Classification
Apr 03, 2025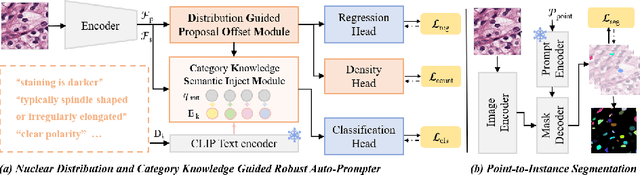
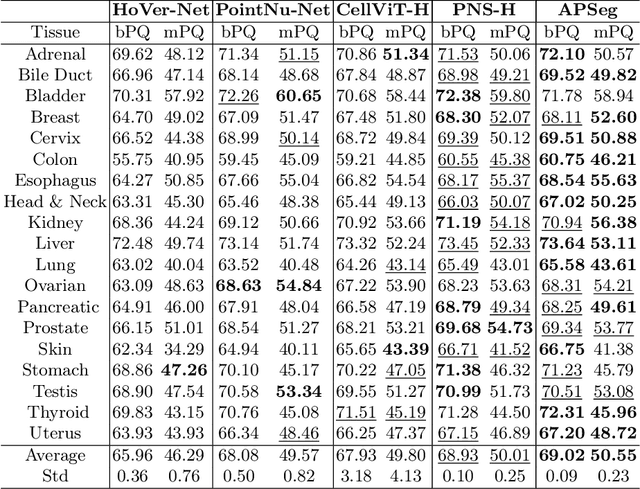
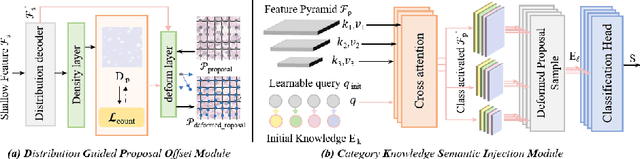
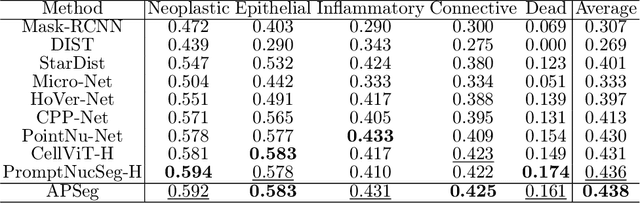
Nuclear instance segmentation and classification provide critical quantitative foundations for digital pathology diagnosis. With the advent of the foundational Segment Anything Model (SAM), the accuracy and efficiency of nuclear segmentation have improved significantly. However, SAM imposes a strong reliance on precise prompts, and its class-agnostic design renders its classification results entirely dependent on the provided prompts. Therefore, we focus on generating prompts with more accurate localization and classification and propose \textbf{APSeg}, \textbf{A}uto-\textbf{P}rompt model with acquired and injected knowledge for nuclear instance \textbf{Seg}mentation and classification. APSeg incorporates two knowledge-aware modules: (1) Distribution-Guided Proposal Offset Module (\textbf{DG-POM}), which learns distribution knowledge through density map guided, and (2) Category Knowledge Semantic Injection Module (\textbf{CK-SIM}), which injects morphological knowledge derived from category descriptions. We conducted extensive experiments on the PanNuke and CoNSeP datasets, demonstrating the effectiveness of our approach. The code will be released upon acceptance.
Instance Migration Diffusion for Nuclear Instance Segmentation in Pathology
Apr 02, 2025Nuclear instance segmentation plays a vital role in disease diagnosis within digital pathology. However, limited labeled data in pathological images restricts the overall performance of nuclear instance segmentation. To tackle this challenge, we propose a novel data augmentation framework Instance Migration Diffusion Model (IM-Diffusion), IM-Diffusion designed to generate more varied pathological images by constructing diverse nuclear layouts and internuclear spatial relationships. In detail, we introduce a Nuclear Migration Module (NMM) which constructs diverse nuclear layouts by simulating the process of nuclear migration. Building on this, we further present an Internuclear-regions Inpainting Module (IIM) to generate diverse internuclear spatial relationships by structure-aware inpainting. On the basis of the above, IM-Diffusion generates more diverse pathological images with different layouts and internuclear spatial relationships, thereby facilitating downstream tasks. Evaluation on the CoNSeP and GLySAC datasets demonstrate that the images generated by IM-Diffusion effectively enhance overall instance segmentation performance. Code will be made public later.
ChatMol: A Versatile Molecule Designer Based on the Numerically Enhanced Large Language Model
Feb 27, 2025



Goal-oriented de novo molecule design, namely generating molecules with specific property or substructure constraints, is a crucial yet challenging task in drug discovery. Existing methods, such as Bayesian optimization and reinforcement learning, often require training multiple property predictors and struggle to incorporate substructure constraints. Inspired by the success of Large Language Models (LLMs) in text generation, we propose ChatMol, a novel approach that leverages LLMs for molecule design across diverse constraint settings. Initially, we crafted a molecule representation compatible with LLMs and validated its efficacy across multiple online LLMs. Afterwards, we developed specific prompts geared towards diverse constrained molecule generation tasks to further fine-tune current LLMs while integrating feedback learning derived from property prediction. Finally, to address the limitations of LLMs in numerical recognition, we referred to the position encoding method and incorporated additional encoding for numerical values within the prompt. Experimental results across single-property, substructure-property, and multi-property constrained tasks demonstrate that ChatMol consistently outperforms state-of-the-art baselines, including VAE and RL-based methods. Notably, in multi-objective binding affinity maximization task, ChatMol achieves a significantly lower KD value of 0.25 for the protein target ESR1, while maintaining the highest overall performance, surpassing previous methods by 4.76%. Meanwhile, with numerical enhancement, the Pearson correlation coefficient between the instructed property values and those of the generated molecules increased by up to 0.49. These findings highlight the potential of LLMs as a versatile framework for molecule generation, offering a promising alternative to traditional latent space and RL-based approaches.
Gated Slot Attention for Efficient Linear-Time Sequence Modeling
Sep 11, 2024



Linear attention Transformers and their gated variants, celebrated for enabling parallel training and efficient recurrent inference, still fall short in recall-intensive tasks compared to traditional Transformers and demand significant resources for training from scratch. This paper introduces Gated Slot Attention (GSA), which enhances Attention with Bounded-memory-Control (ABC) by incorporating a gating mechanism inspired by Gated Linear Attention (GLA). Essentially, GSA comprises a two-layer GLA linked via softmax, utilizing context-aware memory reading and adaptive forgetting to improve memory capacity while maintaining compact recurrent state size. This design greatly enhances both training and inference efficiency through GLA's hardware-efficient training algorithm and reduced state size. Additionally, retaining the softmax operation is particularly beneficial in "finetuning pretrained Transformers to RNNs" (T2R) settings, reducing the need for extensive training from scratch. Extensive experiments confirm GSA's superior performance in scenarios requiring in-context recall and in T2R settings.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024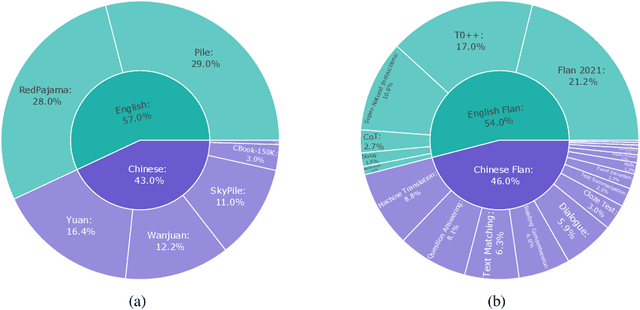

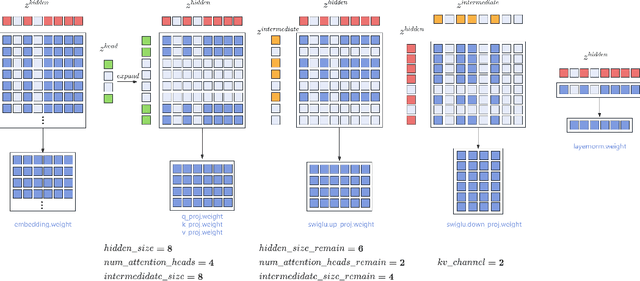
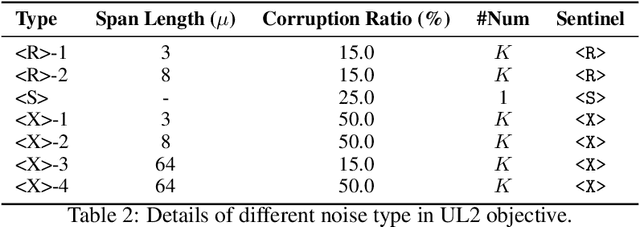
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.