 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Aware Diffusion Draft Trees for Speculative Decoding
Jun 01, 2026Speculative decoding accelerates inference by having a lightweight drafter propose tokens verified in parallel by the target language model. Block diffusion drafters such as DFlash generate an entire draft block in one pass, yielding per-position marginals; DDTree uses these to build a candidate tree that maximizes expected acceptance length under a fixed node budget. We observe, however, that acceptance length is non-decreasing in budget: it always favors larger trees regardless of verification cost, offering no principled basis for budget selection. We introduce \textbf{CaDDTree} (Cost-aware Diffusion Draft Tree), a method that directly optimizes token throughput (expected tokens generated per unit time) by jointly selecting the tree structure and node budget. We model draft and verification latencies explicitly, show that the throughput objective decomposes into a per-round one-dimensional search over the budget, and prove that under a convex verification cost the throughput function is \emph{unimodal}, enabling an efficient greedy stopping rule. CaDDTree requires no offline budget search, adapting the budget each round from the current per-position distributions and verification cost. Experiments on Qwen3-4B and Qwen3-8B across eight benchmarks spanning reasoning, coding, and instruction-following tasks show that \caDDTree{} matches or surpasses DDTree with oracle budget selection on nearly all tasks.
LLaDA2.1: Speeding Up Text Diffusion via Token Editing
Feb 09, 2026While LLaDA2.0 showcased the scaling potential of 100B-level block-diffusion models and their inherent parallelization, the delicate equilibrium between decoding speed and generation quality has remained an elusive frontier. Today, we unveil LLaDA2.1, a paradigm shift designed to transcend this trade-off. By seamlessly weaving Token-to-Token (T2T) editing into the conventional Mask-to-Token (M2T) scheme, we introduce a joint, configurable threshold-decoding scheme. This structural innovation gives rise to two distinct personas: the Speedy Mode (S Mode), which audaciously lowers the M2T threshold to bypass traditional constraints while relying on T2T to refine the output; and the Quality Mode (Q Mode), which leans into conservative thresholds to secure superior benchmark performances with manageable efficiency degrade. Furthering this evolution, underpinned by an expansive context window, we implement the first large-scale Reinforcement Learning (RL) framework specifically tailored for dLLMs, anchored by specialized techniques for stable gradient estimation. This alignment not only sharpens reasoning precision but also elevates instruction-following fidelity, bridging the chasm between diffusion dynamics and complex human intent. We culminate this work by releasing LLaDA2.1-Mini (16B) and LLaDA2.1-Flash (100B). Across 33 rigorous benchmarks, LLaDA2.1 delivers strong task performance and lightning-fast decoding speed. Despite its 100B volume, on coding tasks it attains an astounding 892 TPS on HumanEval+, 801 TPS on BigCodeBench, and 663 TPS on LiveCodeBench.
APSeg: Auto-Prompt Model with Acquired and Injected Knowledge for Nuclear Instance Segmentation and Classification
Apr 03, 2025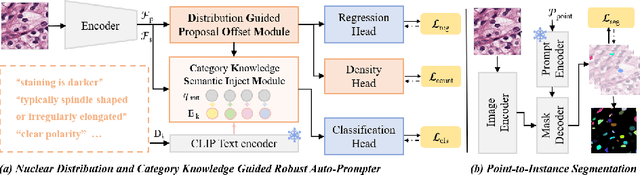
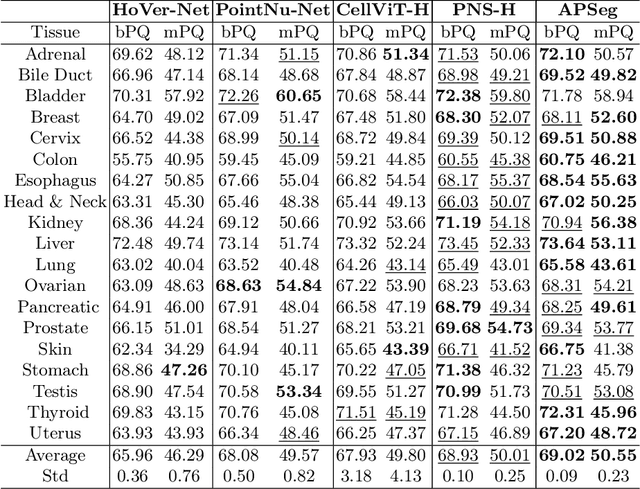
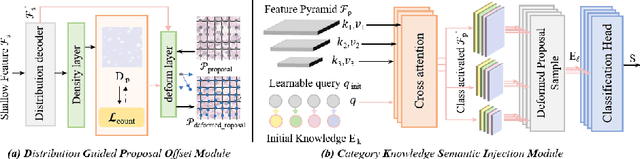
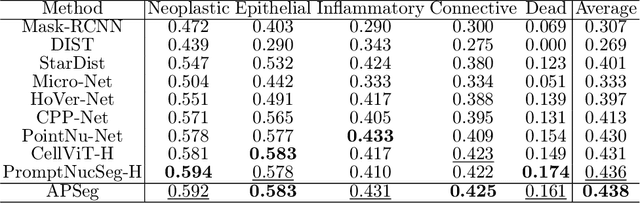
Nuclear instance segmentation and classification provide critical quantitative foundations for digital pathology diagnosis. With the advent of the foundational Segment Anything Model (SAM), the accuracy and efficiency of nuclear segmentation have improved significantly. However, SAM imposes a strong reliance on precise prompts, and its class-agnostic design renders its classification results entirely dependent on the provided prompts. Therefore, we focus on generating prompts with more accurate localization and classification and propose \textbf{APSeg}, \textbf{A}uto-\textbf{P}rompt model with acquired and injected knowledge for nuclear instance \textbf{Seg}mentation and classification. APSeg incorporates two knowledge-aware modules: (1) Distribution-Guided Proposal Offset Module (\textbf{DG-POM}), which learns distribution knowledge through density map guided, and (2) Category Knowledge Semantic Injection Module (\textbf{CK-SIM}), which injects morphological knowledge derived from category descriptions. We conducted extensive experiments on the PanNuke and CoNSeP datasets, demonstrating the effectiveness of our approach. The code will be released upon acceptance.
Instance Migration Diffusion for Nuclear Instance Segmentation in Pathology
Apr 02, 2025Nuclear instance segmentation plays a vital role in disease diagnosis within digital pathology. However, limited labeled data in pathological images restricts the overall performance of nuclear instance segmentation. To tackle this challenge, we propose a novel data augmentation framework Instance Migration Diffusion Model (IM-Diffusion), IM-Diffusion designed to generate more varied pathological images by constructing diverse nuclear layouts and internuclear spatial relationships. In detail, we introduce a Nuclear Migration Module (NMM) which constructs diverse nuclear layouts by simulating the process of nuclear migration. Building on this, we further present an Internuclear-regions Inpainting Module (IIM) to generate diverse internuclear spatial relationships by structure-aware inpainting. On the basis of the above, IM-Diffusion generates more diverse pathological images with different layouts and internuclear spatial relationships, thereby facilitating downstream tasks. Evaluation on the CoNSeP and GLySAC datasets demonstrate that the images generated by IM-Diffusion effectively enhance overall instance segmentation performance. Code will be made public later.
MaintAGT:Sim2Real-Guided Multimodal Large Model for Intelligent Maintenance with Chain-of-Thought Reasoning
Nov 30, 2024



In recent years, large language models have made significant advancements in the field of natural language processing, yet there are still inadequacies in specific domain knowledge and applications. This paper Proposes MaintAGT, a professional large model for intelligent operations and maintenance, aimed at addressing this issue. The system comprises three key components: a signal-to-text model, a pure text model, and a multimodal model. Firstly, the signal-to-text model was designed to convert raw signal data into textual descriptions, bridging the gap between signal data and text-based analysis. Secondly, the pure text model was fine-tuned using the GLM4 model with specialized knowledge to enhance its understanding of domain-specific texts. Finally, these two models were integrated to develop a comprehensive multimodal model that effectively processes and analyzes both signal and textual data.The dataset used for training and evaluation was sourced from academic papers, textbooks, international standards, and vibration analyst training materials, undergoing meticulous preprocessing to ensure high-quality data. As a result, the model has demonstrated outstanding performance across multiple intelligent operations and maintenance tasks, providing a low-cost, high-quality method for constructing large-scale monitoring signal-text description-fault pattern datasets. Experimental results indicate that the model holds significant advantages in condition monitoring, signal processing, and fault diagnosis.In the constructed general test set, MaintAGT achieved an accuracy of 70%, surpassing all existing general large language models and reaching the level of an ISO Level III human vibration analyst.This advancement signifies a crucial step forward from traditional maintenance practices toward intelligent and AI-driven maintenance solutions.
OpenWebVoyager: Building Multimodal Web Agents via Iterative Real-World Exploration, Feedback and Optimization
Oct 25, 2024



The rapid development of large language and multimodal models has sparked significant interest in using proprietary models, such as GPT-4o, to develop autonomous agents capable of handling real-world scenarios like web navigation. Although recent open-source efforts have tried to equip agents with the ability to explore environments and continuously improve over time, they are building text-only agents in synthetic environments where the reward signals are clearly defined. Such agents struggle to generalize to realistic settings that require multimodal perception abilities and lack ground-truth signals. In this paper, we introduce an open-source framework designed to facilitate the development of multimodal web agent that can autonomously conduct real-world exploration and improve itself. We first train the base model with imitation learning to gain the basic abilities. We then let the agent explore the open web and collect feedback on its trajectories. After that, it further improves its policy by learning from well-performing trajectories judged by another general-purpose model. This exploration-feedback-optimization cycle can continue for several iterations. Experimental results show that our web agent successfully improves itself after each iteration, demonstrating strong performance across multiple test sets.
Facilitating Pornographic Text Detection for Open-Domain Dialogue Systems via Knowledge Distillation of Large Language Models
Mar 20, 2024



Pornographic content occurring in human-machine interaction dialogues can cause severe side effects for users in open-domain dialogue systems. However, research on detecting pornographic language within human-machine interaction dialogues is an important subject that is rarely studied. To advance in this direction, we introduce CensorChat, a dialogue monitoring dataset aimed at detecting whether the dialogue session contains pornographic content. To this end, we collect real-life human-machine interaction dialogues in the wild and break them down into single utterances and single-turn dialogues, with the last utterance spoken by the chatbot. We propose utilizing knowledge distillation of large language models to annotate the dataset. Specifically, first, the raw dataset is annotated by four open-source large language models, with the majority vote determining the label. Second, we use ChatGPT to update the empty label from the first step. Third, to ensure the quality of the validation and test sets, we utilize GPT-4 for label calibration. If the current label does not match the one generated by GPT-4, we employ a self-criticism strategy to verify its correctness. Finally, to facilitate the detection of pornographic text, we develop a series of text classifiers using a pseudo-labeled dataset. Detailed data analysis demonstrates that leveraging knowledge distillation techniques with large language models provides a practical and cost-efficient method for developing pornographic text detectors.
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Jan 28, 2024



The advancement of large language models (LLMs) leads to a new era marked by the development of autonomous applications in the real world, which drives innovation in the creation of advanced web-based agents. Existing web agents typically only handle one input modality and are evaluated only in simplified web simulators or static web snapshots, greatly limiting their applicability in real-world scenarios. To bridge this gap, we introduce WebVoyager, an innovative Large Multimodal Model (LMM) powered web agent that can complete user instructions end-to-end by interacting with real-world websites. Moreover, we propose a new evaluation protocol for web agents to address the challenges of automatic evaluation of open-ended web agent tasks, leveraging the robust multimodal comprehension capabilities of GPT-4V. We create a new benchmark by gathering real-world tasks from 15 widely used websites to evaluate our agents. We show that WebVoyager achieves a 55.7% task success rate, significantly surpassing the performance of both GPT-4 (All Tools) and the WebVoyager (text-only) setups, underscoring the exceptional capability of WebVoyager in practical applications. We found that our proposed automatic evaluation achieves 85.3% agreement with human judgment, paving the way for further development of web agents in a real-world setting.
PsyBench: a balanced and in-depth Psychological Chinese Evaluation Benchmark for Foundation Models
Nov 17, 2023As Large Language Models (LLMs) are becoming prevalent in various fields, there is an urgent need for improved NLP benchmarks that encompass all the necessary knowledge of individual discipline. Many contemporary benchmarks for foundational models emphasize a broad range of subjects but often fall short in presenting all the critical subjects and encompassing necessary professional knowledge of them. This shortfall has led to skewed results, given that LLMs exhibit varying performance across different subjects and knowledge areas. To address this issue, we present psybench, the first comprehensive Chinese evaluation suite that covers all the necessary knowledge required for graduate entrance exams. psybench offers a deep evaluation of a model's strengths and weaknesses in psychology through multiple-choice questions. Our findings show significant differences in performance across different sections of a subject, highlighting the risk of skewed results when the knowledge in test sets is not balanced. Notably, only the ChatGPT model reaches an average accuracy above $70\%$, indicating that there is still plenty of room for improvement. We expect that psybench will help to conduct thorough evaluations of base models' strengths and weaknesses and assist in practical application in the field of psychology.
Facilitating NSFW Text Detection in Open-Domain Dialogue Systems via Knowledge Distillation
Sep 19, 2023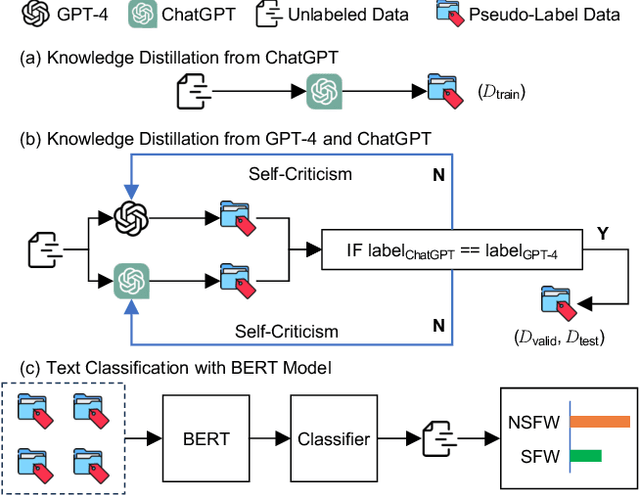



NSFW (Not Safe for Work) content, in the context of a dialogue, can have severe side effects on users in open-domain dialogue systems. However, research on detecting NSFW language, especially sexually explicit content, within a dialogue context has significantly lagged behind. To address this issue, we introduce CensorChat, a dialogue monitoring dataset aimed at NSFW dialogue detection. Leveraging knowledge distillation techniques involving GPT-4 and ChatGPT, this dataset offers a cost-effective means of constructing NSFW content detectors. The process entails collecting real-life human-machine interaction data and breaking it down into single utterances and single-turn dialogues, with the chatbot delivering the final utterance. ChatGPT is employed to annotate unlabeled data, serving as a training set. Rationale validation and test sets are constructed using ChatGPT and GPT-4 as annotators, with a self-criticism strategy for resolving discrepancies in labeling. A BERT model is fine-tuned as a text classifier on pseudo-labeled data, and its performance is assessed. The study emphasizes the importance of AI systems prioritizing user safety and well-being in digital conversations while respecting freedom of expression. The proposed approach not only advances NSFW content detection but also aligns with evolving user protection needs in AI-driven dialogues.