 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaAligner: Conditional Weak-to-Strong Correction for Generalizable Multi-Objective Alignment of Language Models
Mar 25, 2024
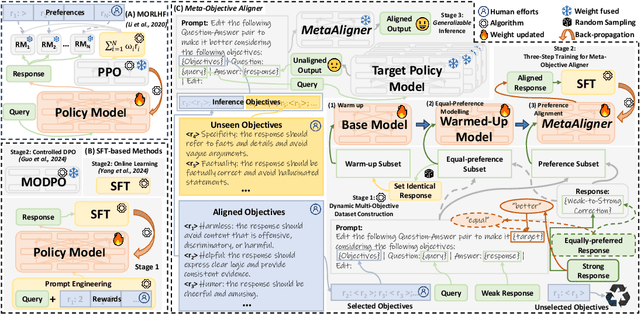


Recent advancements in large language models (LLMs) aim to tackle heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are parameter-adherent to the policy model, leading to two key limitations: (1) the high-cost repetition of their alignment algorithms for each new target model; (2) they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), a model that performs conditional weak-to-strong correction for weak responses to approach strong responses. MetaAligner is the first policy-agnostic and generalizable method for multi-objective preference alignment, which enables plug-and-play alignment by decoupling parameter updates from the policy models and facilitates zero-shot preference alignment for unseen objectives via in-context learning. Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 11 policy models with up to 63x more parameters, and outperforms previous alignment methods with down to 22.27x less computational resources. The model also accurately aligns with unseen objectives, marking the first step towards generalizable multi-objective preference alignment.
Automatic Evaluation for Mental Health Counseling using LLMs
Feb 19, 2024

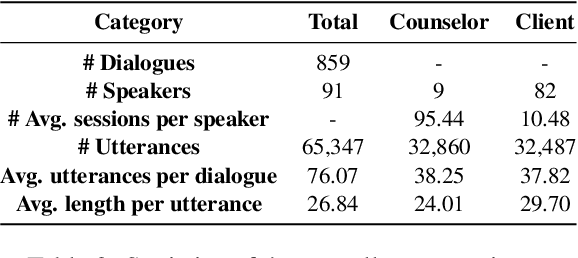

High-quality psychological counseling is crucial for mental health worldwide, and timely evaluation is vital for ensuring its effectiveness. However, obtaining professional evaluation for each counseling session is expensive and challenging. Existing methods that rely on self or third-party manual reports to assess the quality of counseling suffer from subjective biases and limitations of time-consuming. To address above challenges, this paper proposes an innovative and efficient automatic approach using large language models (LLMs) to evaluate the working alliance in counseling conversations. We collected a comprehensive counseling dataset and conducted multiple third-party evaluations based on therapeutic relationship theory. Our LLM-based evaluation, combined with our guidelines, shows high agreement with human evaluations and provides valuable insights into counseling scripts. This highlights the potential of LLMs as supervisory tools for psychotherapists. By integrating LLMs into the evaluation process, our approach offers a cost-effective and dependable means of assessing counseling quality, enhancing overall effectiveness.
PsyBench: a balanced and in-depth Psychological Chinese Evaluation Benchmark for Foundation Models
Nov 17, 2023As Large Language Models (LLMs) are becoming prevalent in various fields, there is an urgent need for improved NLP benchmarks that encompass all the necessary knowledge of individual discipline. Many contemporary benchmarks for foundational models emphasize a broad range of subjects but often fall short in presenting all the critical subjects and encompassing necessary professional knowledge of them. This shortfall has led to skewed results, given that LLMs exhibit varying performance across different subjects and knowledge areas. To address this issue, we present psybench, the first comprehensive Chinese evaluation suite that covers all the necessary knowledge required for graduate entrance exams. psybench offers a deep evaluation of a model's strengths and weaknesses in psychology through multiple-choice questions. Our findings show significant differences in performance across different sections of a subject, highlighting the risk of skewed results when the knowledge in test sets is not balanced. Notably, only the ChatGPT model reaches an average accuracy above $70\%$, indicating that there is still plenty of room for improvement. We expect that psybench will help to conduct thorough evaluations of base models' strengths and weaknesses and assist in practical application in the field of psychology.