 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-Aware Diffusion Draft Trees for Speculative Decoding
Jun 01, 2026Speculative decoding accelerates inference by having a lightweight drafter propose tokens verified in parallel by the target language model. Block diffusion drafters such as DFlash generate an entire draft block in one pass, yielding per-position marginals; DDTree uses these to build a candidate tree that maximizes expected acceptance length under a fixed node budget. We observe, however, that acceptance length is non-decreasing in budget: it always favors larger trees regardless of verification cost, offering no principled basis for budget selection. We introduce \textbf{CaDDTree} (Cost-aware Diffusion Draft Tree), a method that directly optimizes token throughput (expected tokens generated per unit time) by jointly selecting the tree structure and node budget. We model draft and verification latencies explicitly, show that the throughput objective decomposes into a per-round one-dimensional search over the budget, and prove that under a convex verification cost the throughput function is \emph{unimodal}, enabling an efficient greedy stopping rule. CaDDTree requires no offline budget search, adapting the budget each round from the current per-position distributions and verification cost. Experiments on Qwen3-4B and Qwen3-8B across eight benchmarks spanning reasoning, coding, and instruction-following tasks show that \caDDTree{} matches or surpasses DDTree with oracle budget selection on nearly all tasks.
PsyCLIENT: Client Simulation via Conversational Trajectory Modeling for Trainee Practice and Model Evaluation in Mental Health Counseling
Jan 12, 2026LLM-based client simulation has emerged as a promising tool for training novice counselors and evaluating automated counseling systems. However, existing client simulation approaches face three key challenges: (1) limited diversity and realism in client profiles, (2) the lack of a principled framework for modeling realistic client behaviors, and (3) a scarcity in Chinese-language settings. To address these limitations, we propose PsyCLIENT, a novel simulation framework grounded in conversational trajectory modeling. By conditioning LLM generation on predefined real-world trajectories that incorporate explicit behavior labels and content constraints, our approach ensures diverse and realistic interactions. We further introduce PsyCLIENT-CP, the first open-source Chinese client profile dataset, covering 60 distinct counseling topics. Comprehensive evaluations involving licensed professional counselors demonstrate that PsyCLIENT significantly outperforms baselines in terms of authenticity and training effectiveness. Notably, the simulated clients are nearly indistinguishable from human clients, achieving an about 95\% expert confusion rate in discrimination tasks. These findings indicate that conversational trajectory modeling effectively bridges the gap between theoretical client profiles and dynamic, realistic simulations, offering a robust solution for mental health education and research. Code and data will be released to facilitate future research in mental health counseling.
PsyGUARD: An Automated System for Suicide Detection and Risk Assessment in Psychological Counseling
Sep 30, 2024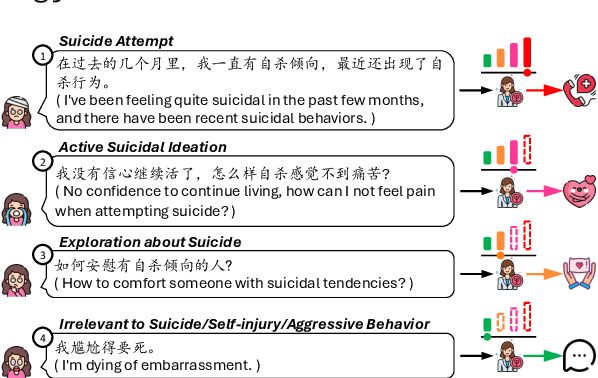
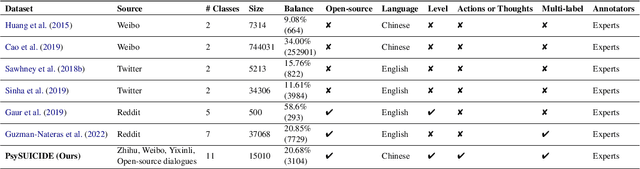
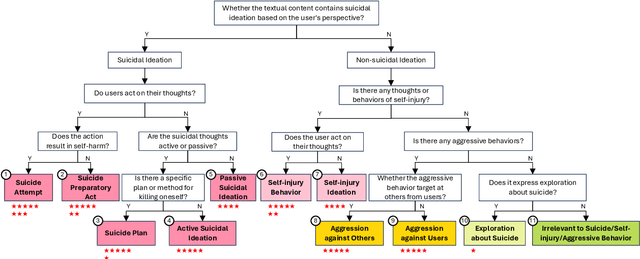
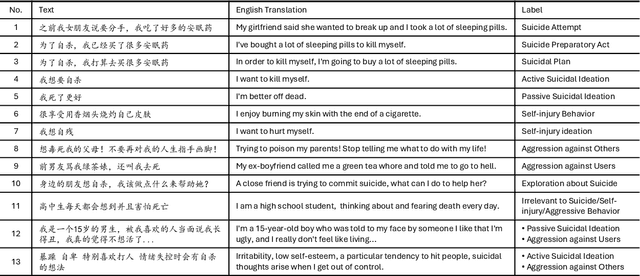
As awareness of mental health issues grows, online counseling support services are becoming increasingly prevalent worldwide. Detecting whether users express suicidal ideation in text-based counseling services is crucial for identifying and prioritizing at-risk individuals. However, the lack of domain-specific systems to facilitate fine-grained suicide detection and corresponding risk assessment in online counseling poses a significant challenge for automated crisis intervention aimed at suicide prevention. In this paper, we propose PsyGUARD, an automated system for detecting suicide ideation and assessing risk in psychological counseling. To achieve this, we first develop a detailed taxonomy for detecting suicide ideation based on foundational theories. We then curate a large-scale, high-quality dataset called PsySUICIDE for suicide detection. To evaluate the capabilities of automated systems in fine-grained suicide detection, we establish a range of baselines. Subsequently, to assist automated services in providing safe, helpful, and tailored responses for further assessment, we propose to build a suite of risk assessment frameworks. Our study not only provides an insightful analysis of the effectiveness of automated risk assessment systems based on fine-grained suicide detection but also highlights their potential to improve mental health services on online counseling platforms. Code, data, and models are available at https://github.com/qiuhuachuan/PsyGUARD.
Interactive Agents: Simulating Counselor-Client Psychological Counseling via Role-Playing LLM-to-LLM Interactions
Aug 28, 2024Virtual counselors powered by large language models (LLMs) aim to create interactive support systems that effectively assist clients struggling with mental health challenges. To replicate counselor-client conversations, researchers have built an online mental health platform that allows professional counselors to provide clients with text-based counseling services for about an hour per session. Notwithstanding its effectiveness, challenges exist as human annotation is time-consuming, cost-intensive, privacy-protected, and not scalable. To address this issue and investigate the applicability of LLMs in psychological counseling conversation simulation, we propose a framework that employs two LLMs via role-playing for simulating counselor-client interactions. Our framework involves two LLMs, one acting as a client equipped with a specific and real-life user profile and the other playing the role of an experienced counselor, generating professional responses using integrative therapy techniques. We implement both the counselor and the client by zero-shot prompting the GPT-4 model. In order to assess the effectiveness of LLMs in simulating counselor-client interactions and understand the disparities between LLM- and human-generated conversations, we evaluate the synthetic data from various perspectives. We begin by assessing the client's performance through automatic evaluations. Next, we analyze and compare the disparities between dialogues generated by the LLM and those generated by professional counselors. Furthermore, we conduct extensive experiments to thoroughly examine the performance of our LLM-based counselor trained with synthetic interactive dialogues by benchmarking against state-of-the-art models for mental health.
Facilitating Pornographic Text Detection for Open-Domain Dialogue Systems via Knowledge Distillation of Large Language Models
Mar 20, 2024



Pornographic content occurring in human-machine interaction dialogues can cause severe side effects for users in open-domain dialogue systems. However, research on detecting pornographic language within human-machine interaction dialogues is an important subject that is rarely studied. To advance in this direction, we introduce CensorChat, a dialogue monitoring dataset aimed at detecting whether the dialogue session contains pornographic content. To this end, we collect real-life human-machine interaction dialogues in the wild and break them down into single utterances and single-turn dialogues, with the last utterance spoken by the chatbot. We propose utilizing knowledge distillation of large language models to annotate the dataset. Specifically, first, the raw dataset is annotated by four open-source large language models, with the majority vote determining the label. Second, we use ChatGPT to update the empty label from the first step. Third, to ensure the quality of the validation and test sets, we utilize GPT-4 for label calibration. If the current label does not match the one generated by GPT-4, we employ a self-criticism strategy to verify its correctness. Finally, to facilitate the detection of pornographic text, we develop a series of text classifiers using a pseudo-labeled dataset. Detailed data analysis demonstrates that leveraging knowledge distillation techniques with large language models provides a practical and cost-efficient method for developing pornographic text detectors.
Unveiling the Secrets of Engaging Conversations: Factors that Keep Users Hooked on Role-Playing Dialog Agents
Feb 18, 2024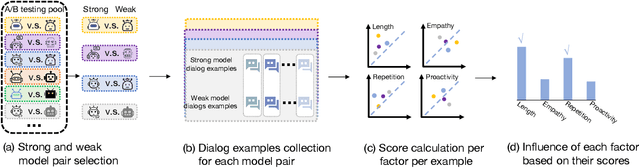



With the growing humanlike nature of dialog agents, people are now engaging in extended conversations that can stretch from brief moments to substantial periods of time. Understanding the factors that contribute to sustaining these interactions is crucial, yet existing studies primarily focusing on short-term simulations that rarely explore such prolonged and real conversations. In this paper, we investigate the factors influencing retention rates in real interactions with roleplaying models. By analyzing a large dataset of interactions between real users and thousands of characters, we systematically examine multiple factors and assess their impact on user retention rate. Surprisingly, we find that the degree to which the bot embodies the roles it plays has limited influence on retention rates, while the length of each turn it speaks significantly affects retention rates. This study sheds light on the critical aspects of user engagement with role-playing models and provides valuable insights for future improvements in the development of large language models for role-playing purposes.
PsyChat: A Client-Centric Dialogue System for Mental Health Support
Dec 07, 2023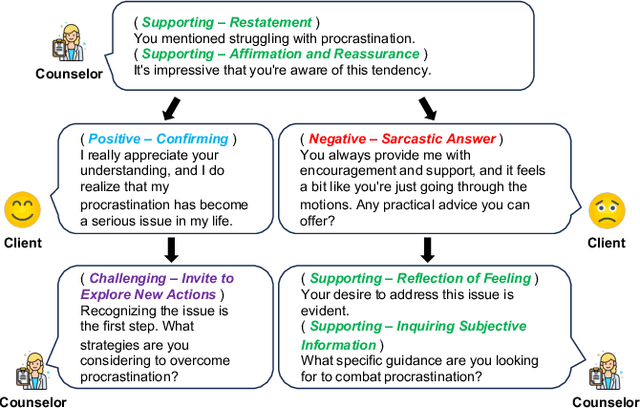
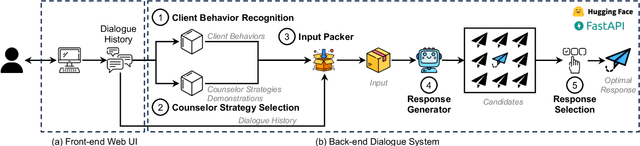
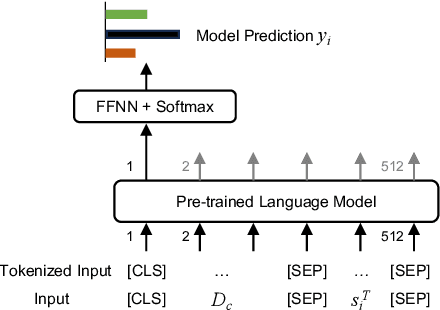

Dialogue systems are increasingly integrated into mental health support to help clients facilitate exploration, gain insight, take action, and ultimately heal themselves. For a dialogue system to be practical and user-friendly, it should be client-centric, focusing on the client's behaviors. However, existing dialogue systems publicly available for mental health support often concentrate solely on the counselor's strategies rather than the behaviors expressed by clients. This can lead to the implementation of unreasonable or inappropriate counseling strategies and corresponding responses from the dialogue system. To address this issue, we propose PsyChat, a client-centric dialogue system that provides psychological support through online chat. The client-centric dialogue system comprises five modules: client behavior recognition, counselor strategy selection, input packer, response generator intentionally fine-tuned to produce responses, and response selection. Both automatic and human evaluations demonstrate the effectiveness and practicality of our proposed dialogue system for real-life mental health support. Furthermore, we employ our proposed dialogue system to simulate a real-world client-virtual-counselor interaction scenario. The system is capable of predicting the client's behaviors, selecting appropriate counselor strategies, and generating accurate and suitable responses, as demonstrated in the scenario.
PsyBench: a balanced and in-depth Psychological Chinese Evaluation Benchmark for Foundation Models
Nov 17, 2023As Large Language Models (LLMs) are becoming prevalent in various fields, there is an urgent need for improved NLP benchmarks that encompass all the necessary knowledge of individual discipline. Many contemporary benchmarks for foundational models emphasize a broad range of subjects but often fall short in presenting all the critical subjects and encompassing necessary professional knowledge of them. This shortfall has led to skewed results, given that LLMs exhibit varying performance across different subjects and knowledge areas. To address this issue, we present psybench, the first comprehensive Chinese evaluation suite that covers all the necessary knowledge required for graduate entrance exams. psybench offers a deep evaluation of a model's strengths and weaknesses in psychology through multiple-choice questions. Our findings show significant differences in performance across different sections of a subject, highlighting the risk of skewed results when the knowledge in test sets is not balanced. Notably, only the ChatGPT model reaches an average accuracy above $70\%$, indicating that there is still plenty of room for improvement. We expect that psybench will help to conduct thorough evaluations of base models' strengths and weaknesses and assist in practical application in the field of psychology.
Facilitating NSFW Text Detection in Open-Domain Dialogue Systems via Knowledge Distillation
Sep 19, 2023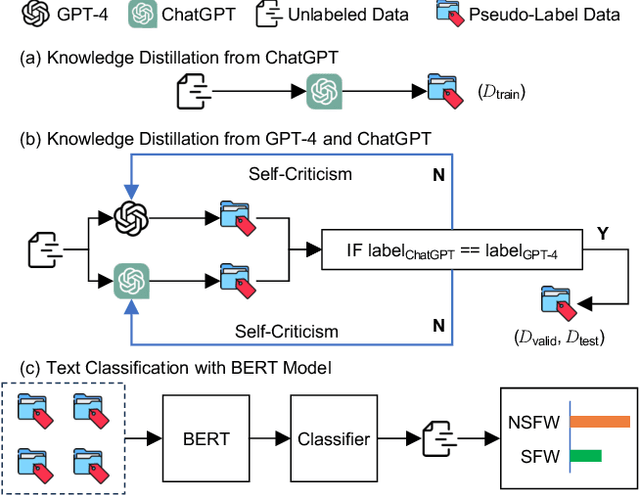



NSFW (Not Safe for Work) content, in the context of a dialogue, can have severe side effects on users in open-domain dialogue systems. However, research on detecting NSFW language, especially sexually explicit content, within a dialogue context has significantly lagged behind. To address this issue, we introduce CensorChat, a dialogue monitoring dataset aimed at NSFW dialogue detection. Leveraging knowledge distillation techniques involving GPT-4 and ChatGPT, this dataset offers a cost-effective means of constructing NSFW content detectors. The process entails collecting real-life human-machine interaction data and breaking it down into single utterances and single-turn dialogues, with the chatbot delivering the final utterance. ChatGPT is employed to annotate unlabeled data, serving as a training set. Rationale validation and test sets are constructed using ChatGPT and GPT-4 as annotators, with a self-criticism strategy for resolving discrepancies in labeling. A BERT model is fine-tuned as a text classifier on pseudo-labeled data, and its performance is assessed. The study emphasizes the importance of AI systems prioritizing user safety and well-being in digital conversations while respecting freedom of expression. The proposed approach not only advances NSFW content detection but also aligns with evolving user protection needs in AI-driven dialogues.
A Benchmark for Understanding Dialogue Safety in Mental Health Support
Jul 31, 2023



Dialogue safety remains a pervasive challenge in open-domain human-machine interaction. Existing approaches propose distinctive dialogue safety taxonomies and datasets for detecting explicitly harmful responses. However, these taxonomies may not be suitable for analyzing response safety in mental health support. In real-world interactions, a model response deemed acceptable in casual conversations might have a negligible positive impact on users seeking mental health support. To address these limitations, this paper aims to develop a theoretically and factually grounded taxonomy that prioritizes the positive impact on help-seekers. Additionally, we create a benchmark corpus with fine-grained labels for each dialogue session to facilitate further research. We analyze the dataset using popular language models, including BERT-base, RoBERTa-large, and ChatGPT, to detect and understand unsafe responses within the context of mental health support. Our study reveals that ChatGPT struggles to detect safety categories with detailed safety definitions in a zero- and few-shot paradigm, whereas the fine-tuned model proves to be more suitable. The developed dataset and findings serve as valuable benchmarks for advancing research on dialogue safety in mental health support, with significant implications for improving the design and deployment of conversation agents in real-world applications. We release our code and data here: https://github.com/qiuhuachuan/DialogueSafety.