 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
MetaAligner: Conditional Weak-to-Strong Correction for Generalizable Multi-Objective Alignment of Language Models
Mar 25, 2024
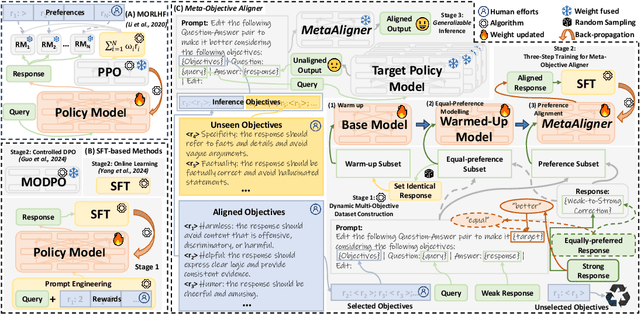


Recent advancements in large language models (LLMs) aim to tackle heterogeneous human expectations and values via multi-objective preference alignment. However, existing methods are parameter-adherent to the policy model, leading to two key limitations: (1) the high-cost repetition of their alignment algorithms for each new target model; (2) they cannot expand to unseen objectives due to their static alignment objectives. In this work, we propose Meta-Objective Aligner (MetaAligner), a model that performs conditional weak-to-strong correction for weak responses to approach strong responses. MetaAligner is the first policy-agnostic and generalizable method for multi-objective preference alignment, which enables plug-and-play alignment by decoupling parameter updates from the policy models and facilitates zero-shot preference alignment for unseen objectives via in-context learning. Experimental results show that MetaAligner achieves significant and balanced improvements in multi-objective alignments on 11 policy models with up to 63x more parameters, and outperforms previous alignment methods with down to 22.27x less computational resources. The model also accurately aligns with unseen objectives, marking the first step towards generalizable multi-objective preference alignment.
HealMe: Harnessing Cognitive Reframing in Large Language Models for Psychotherapy
Feb 26, 2024



Large Language Models (LLMs) can play a vital role in psychotherapy by adeptly handling the crucial task of cognitive reframing and overcoming challenges such as shame, distrust, therapist skill variability, and resource scarcity. Previous LLMs in cognitive reframing mainly converted negative emotions to positive ones, but these approaches have limited efficacy, often not promoting clients' self-discovery of alternative perspectives. In this paper, we unveil the Helping and Empowering through Adaptive Language in Mental Enhancement (HealMe) model. This novel cognitive reframing therapy method effectively addresses deep-rooted negative thoughts and fosters rational, balanced perspectives. Diverging from traditional LLM methods, HealMe employs empathetic dialogue based on psychotherapeutic frameworks. It systematically guides clients through distinguishing circumstances from feelings, brainstorming alternative viewpoints, and developing empathetic, actionable suggestions. Moreover, we adopt the first comprehensive and expertly crafted psychological evaluation metrics, specifically designed to rigorously assess the performance of cognitive reframing, in both AI-simulated dialogues and real-world therapeutic conversations. Experimental results show that our model outperforms others in terms of empathy, guidance, and logical coherence, demonstrating its effectiveness and potential positive impact on psychotherapy.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
MentalLLaMA: Interpretable Mental Health Analysis on Social Media with Large Language Models
Sep 24, 2023



With the development of web technology, social media texts are becoming a rich source for automatic mental health analysis. As traditional discriminative methods bear the problem of low interpretability, the recent large language models have been explored for interpretable mental health analysis on social media, which aims to provide detailed explanations along with predictions. The results show that ChatGPT can generate approaching-human explanations for its correct classifications. However, LLMs still achieve unsatisfactory classification performance in a zero-shot/few-shot manner. Domain-specific finetuning is an effective solution, but faces 2 challenges: 1) lack of high-quality training data. 2) no open-source LLMs for interpretable mental health analysis were released to lower the finetuning cost. To alleviate these problems, we build the first multi-task and multi-source interpretable mental health instruction (IMHI) dataset on social media, with 105K data samples. The raw social media data are collected from 10 existing sources covering 8 mental health analysis tasks. We use expert-written few-shot prompts and collected labels to prompt ChatGPT and obtain explanations from its responses. To ensure the reliability of the explanations, we perform strict automatic and human evaluations on the correctness, consistency, and quality of generated data. Based on the IMHI dataset and LLaMA2 foundation models, we train MentalLLaMA, the first open-source LLM series for interpretable mental health analysis with instruction-following capability. We also evaluate the performance of MentalLLaMA on the IMHI evaluation benchmark with 10 test sets, where their correctness for making predictions and the quality of explanations are examined. The results show that MentalLLaMA approaches state-of-the-art discriminative methods in correctness and generates high-quality explanations.