 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEbisu: Benchmarking Large Language Models in Japanese Finance
Feb 01, 2026Japanese finance combines agglutinative, head-final linguistic structure, mixed writing systems, and high-context communication norms that rely on indirect expression and implicit commitment, posing a substantial challenge for LLMs. We introduce Ebisu, a benchmark for native Japanese financial language understanding, comprising two linguistically and culturally grounded, expert-annotated tasks: JF-ICR, which evaluates implicit commitment and refusal recognition in investor-facing Q&A, and JF-TE, which assesses hierarchical extraction and ranking of nested financial terminology from professional disclosures. We evaluate a diverse set of open-source and proprietary LLMs spanning general-purpose, Japanese-adapted, and financial models. Results show that even state-of-the-art systems struggle on both tasks. While increased model scale yields limited improvements, language- and domain-specific adaptation does not reliably improve performance, leaving substantial gaps unresolved. Ebisu provides a focused benchmark for advancing linguistically and culturally grounded financial NLP. All datasets and evaluation scripts are publicly released.
FinCriticalED: A Visual Benchmark for Financial Fact-Level OCR Evaluation
Nov 19, 2025We introduce FinCriticalED (Financial Critical Error Detection), a visual benchmark for evaluating OCR and vision language models on financial documents at the fact level. Financial documents contain visually dense and table heavy layouts where numerical and temporal information is tightly coupled with structure. In high stakes settings, small OCR mistakes such as sign inversion or shifted dates can lead to materially different interpretations, while traditional OCR metrics like ROUGE and edit distance capture only surface level text similarity. \ficriticaled provides 500 image-HTML pairs with expert annotated financial facts covering over seven hundred numerical and temporal facts. It introduces three key contributions. First, it establishes the first fact level evaluation benchmark for financial document understanding, shifting evaluation from lexical overlap to domain critical factual correctness. Second, all annotations are created and verified by financial experts with strict quality control over signs, magnitudes, and temporal expressions. Third, we develop an LLM-as-Judge evaluation pipeline that performs structured fact extraction and contextual verification for visually complex financial documents. We benchmark OCR systems, open source vision language models, and proprietary models on FinCriticalED. Results show that although the strongest proprietary models achieve the highest factual accuracy, substantial errors remain in visually intricate numerical and temporal contexts. Through quantitative evaluation and expert case studies, FinCriticalED provides a rigorous foundation for advancing visual factual precision in financial and other precision critical domains.
RKEFino1: A Regulation Knowledge-Enhanced Large Language Model
Jun 06, 2025Recent advances in large language models (LLMs) hold great promise for financial applications but introduce critical accuracy and compliance challenges in Digital Regulatory Reporting (DRR). To address these issues, we propose RKEFino1, a regulation knowledge-enhanced financial reasoning model built upon Fino1, fine-tuned with domain knowledge from XBRL, CDM, and MOF. We formulate two QA tasks-knowledge-based and mathematical reasoning-and introduce a novel Numerical NER task covering financial entities in both sentences and tables. Experimental results demonstrate the effectiveness and generalization capacity of RKEFino1 in compliance-critical financial tasks. We have released our model on Hugging Face.
Plutus: Benchmarking Large Language Models in Low-Resource Greek Finance
Feb 26, 2025Despite Greece's pivotal role in the global economy, large language models (LLMs) remain underexplored for Greek financial context due to the linguistic complexity of Greek and the scarcity of domain-specific datasets. Previous efforts in multilingual financial natural language processing (NLP) have exposed considerable performance disparities, yet no dedicated Greek financial benchmarks or Greek-specific financial LLMs have been developed until now. To bridge this gap, we introduce Plutus-ben, the first Greek Financial Evaluation Benchmark, and Plutus-8B, the pioneering Greek Financial LLM, fine-tuned with Greek domain-specific data. Plutus-ben addresses five core financial NLP tasks in Greek: numeric and textual named entity recognition, question answering, abstractive summarization, and topic classification, thereby facilitating systematic and reproducible LLM assessments. To underpin these tasks, we present three novel, high-quality Greek financial datasets, thoroughly annotated by expert native Greek speakers, augmented by two existing resources. Our comprehensive evaluation of 22 LLMs on Plutus-ben reveals that Greek financial NLP remains challenging due to linguistic complexity, domain-specific terminology, and financial reasoning gaps. These findings underscore the limitations of cross-lingual transfer, the necessity for financial expertise in Greek-trained models, and the challenges of adapting financial LLMs to Greek text. We release Plutus-ben, Plutus-8B, and all associated datasets publicly to promote reproducible research and advance Greek financial NLP, fostering broader multilingual inclusivity in finance.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
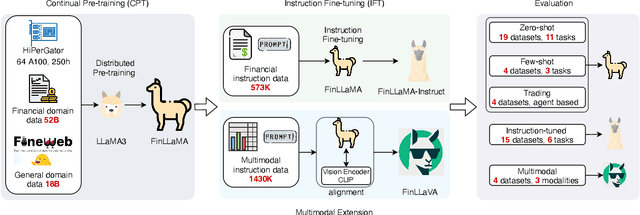
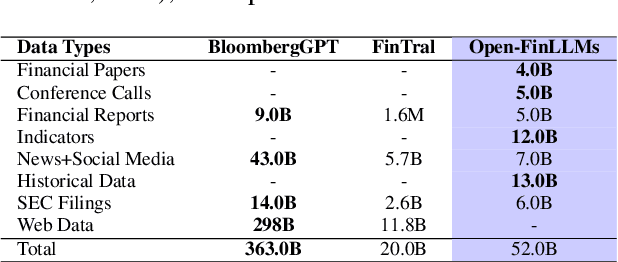
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English
Feb 12, 2024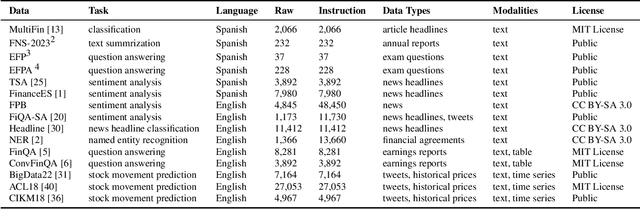
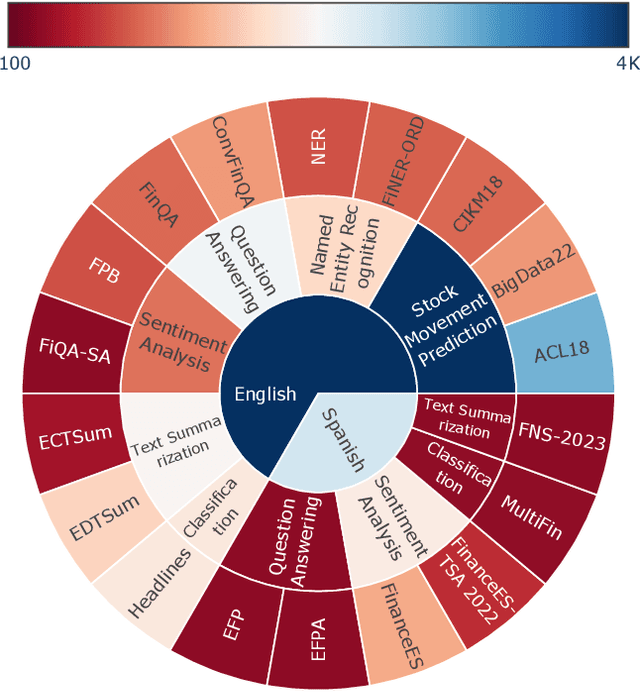
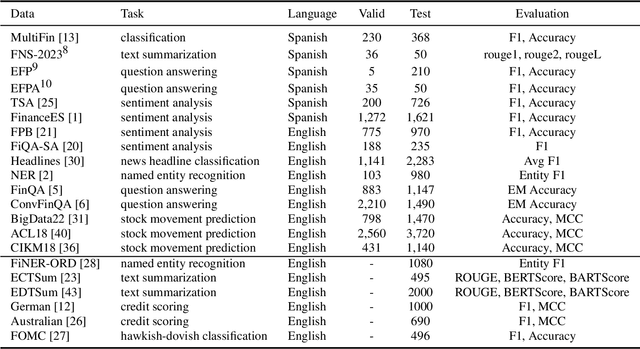
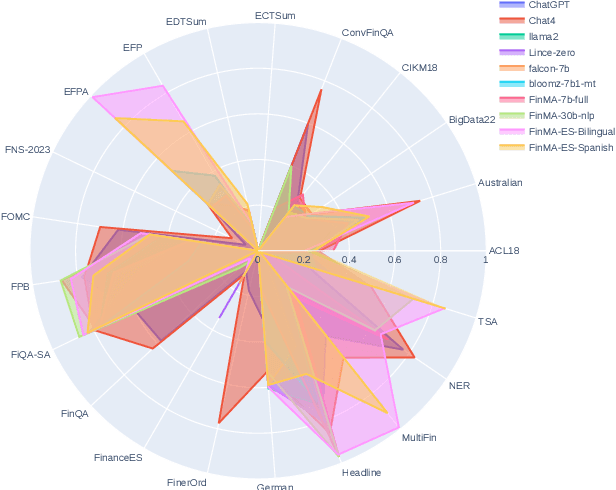
Despite Spanish's pivotal role in the global finance industry, a pronounced gap exists in Spanish financial natural language processing (NLP) and application studies compared to English, especially in the era of large language models (LLMs). To bridge this gap, we unveil Tois\'on de Oro, the first bilingual framework that establishes instruction datasets, finetuned LLMs, and evaluation benchmark for financial LLMs in Spanish joint with English. We construct a rigorously curated bilingual instruction dataset including over 144K Spanish and English samples from 15 datasets covering 7 tasks. Harnessing this, we introduce FinMA-ES, an LLM designed for bilingual financial applications. We evaluate our model and existing LLMs using FLARE-ES, the first comprehensive bilingual evaluation benchmark with 21 datasets covering 9 tasks. The FLARE-ES benchmark results reveal a significant multilingual performance gap and bias in existing LLMs. FinMA-ES models surpass SOTA LLMs such as GPT-4 in Spanish financial tasks, due to strategic instruction tuning and leveraging data from diverse linguistic resources, highlighting the positive impact of cross-linguistic transfer. All our datasets, models, and benchmarks have been released.