 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Sharpening Becomes Collapse: Sampling Bias and Semantic Coupling in RL with Verifiable Rewards
Jan 26, 2026Reinforcement Learning with Verifiable Rewards (RLVR) is a central paradigm for turning large language models (LLMs) into reliable problem solvers, especially in logic-heavy domains. Despite its empirical success, it remains unclear whether RLVR elicits novel capabilities or merely sharpens the distribution over existing knowledge. We study this by formalizing over-sharpening, a phenomenon where the policy collapses onto limited modes, suppressing valid alternatives. At a high level, we discover finite-batch updates intrinsically bias learning toward sampled modes, triggering a collapse that propagates globally via semantic coupling. To mitigate this, we propose inverse-success advantage calibration to prioritize difficult queries and distribution-level calibration to diversify sampling via a memory network. Empirical evaluations validate that our strategies can effectively improve generalization.
MentraSuite: Post-Training Large Language Models for Mental Health Reasoning and Assessment
Dec 16, 2025Mental health disorders affect hundreds of millions globally, and the Web now serves as a primary medium for accessing support, information, and assessment. Large language models (LLMs) offer scalable and accessible assistance, yet their deployment in mental-health settings remains risky when their reasoning is incomplete, inconsistent, or ungrounded. Existing psychological LLMs emphasize emotional understanding or knowledge recall but overlook the step-wise, clinically aligned reasoning required for appraisal, diagnosis, intervention planning, abstraction, and verification. To address these issues, we introduce MentraSuite, a unified framework for advancing reliable mental-health reasoning. We propose MentraBench, a comprehensive benchmark spanning five core reasoning aspects, six tasks, and 13 datasets, evaluating both task performance and reasoning quality across five dimensions: conciseness, coherence, hallucination avoidance, task understanding, and internal consistency. We further present Mindora, a post-trained model optimized through a hybrid SFT-RL framework with an inconsistency-detection reward to enforce faithful and coherent reasoning. To support training, we construct high-quality trajectories using a novel reasoning trajectory generation strategy, that strategically filters difficult samples and applies a structured, consistency-oriented rewriting process to produce concise, readable, and well-balanced trajectories. Across 20 evaluated LLMs, Mindora achieves the highest average performance on MentraBench and shows remarkable performances in reasoning reliability, demonstrating its effectiveness for complex mental-health scenarios.
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Aug 20, 2024
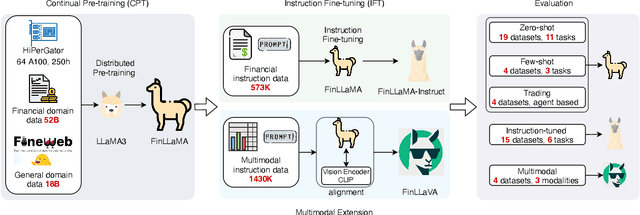
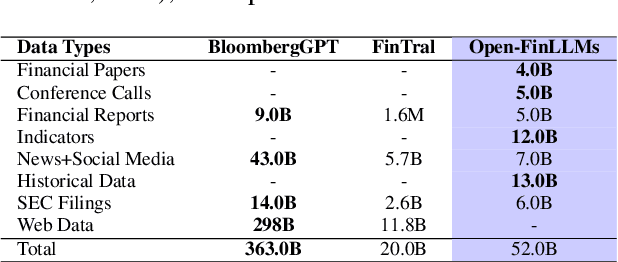
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce \textit{Open-FinLLMs}, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA's superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
HealMe: Harnessing Cognitive Reframing in Large Language Models for Psychotherapy
Feb 26, 2024



Large Language Models (LLMs) can play a vital role in psychotherapy by adeptly handling the crucial task of cognitive reframing and overcoming challenges such as shame, distrust, therapist skill variability, and resource scarcity. Previous LLMs in cognitive reframing mainly converted negative emotions to positive ones, but these approaches have limited efficacy, often not promoting clients' self-discovery of alternative perspectives. In this paper, we unveil the Helping and Empowering through Adaptive Language in Mental Enhancement (HealMe) model. This novel cognitive reframing therapy method effectively addresses deep-rooted negative thoughts and fosters rational, balanced perspectives. Diverging from traditional LLM methods, HealMe employs empathetic dialogue based on psychotherapeutic frameworks. It systematically guides clients through distinguishing circumstances from feelings, brainstorming alternative viewpoints, and developing empathetic, actionable suggestions. Moreover, we adopt the first comprehensive and expertly crafted psychological evaluation metrics, specifically designed to rigorously assess the performance of cognitive reframing, in both AI-simulated dialogues and real-world therapeutic conversations. Experimental results show that our model outperforms others in terms of empathy, guidance, and logical coherence, demonstrating its effectiveness and potential positive impact on psychotherapy.
The FinBen: An Holistic Financial Benchmark for Large Language Models
Feb 20, 2024



LLMs have transformed NLP and shown promise in various fields, yet their potential in finance is underexplored due to a lack of thorough evaluations and the complexity of financial tasks. This along with the rapid development of LLMs, highlights the urgent need for a systematic financial evaluation benchmark for LLMs. In this paper, we introduce FinBen, the first comprehensive open-sourced evaluation benchmark, specifically designed to thoroughly assess the capabilities of LLMs in the financial domain. FinBen encompasses 35 datasets across 23 financial tasks, organized into three spectrums of difficulty inspired by the Cattell-Horn-Carroll theory, to evaluate LLMs' cognitive abilities in inductive reasoning, associative memory, quantitative reasoning, crystallized intelligence, and more. Our evaluation of 15 representative LLMs, including GPT-4, ChatGPT, and the latest Gemini, reveals insights into their strengths and limitations within the financial domain. The findings indicate that GPT-4 leads in quantification, extraction, numerical reasoning, and stock trading, while Gemini shines in generation and forecasting; however, both struggle with complex extraction and forecasting, showing a clear need for targeted enhancements. Instruction tuning boosts simple task performance but falls short in improving complex reasoning and forecasting abilities. FinBen seeks to continuously evaluate LLMs in finance, fostering AI development with regular updates of tasks and models.
Dólares or Dollars? Unraveling the Bilingual Prowess of Financial LLMs Between Spanish and English
Feb 12, 2024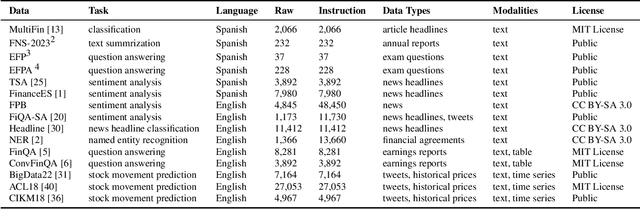
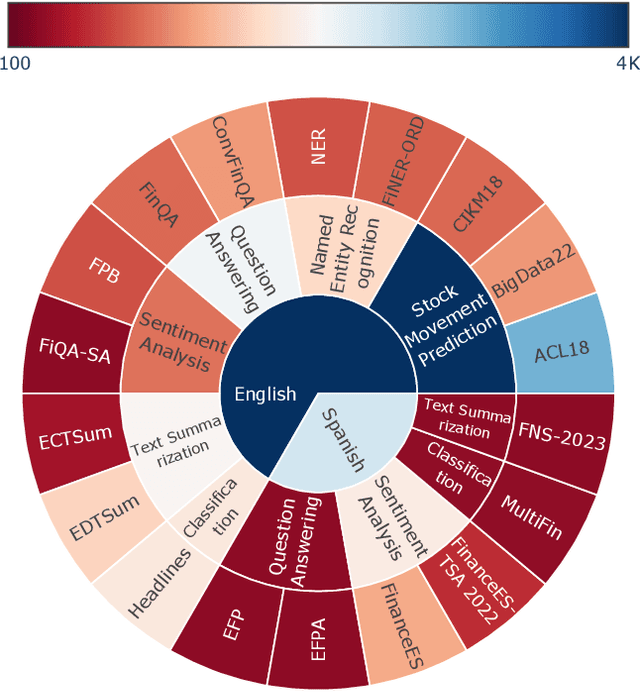
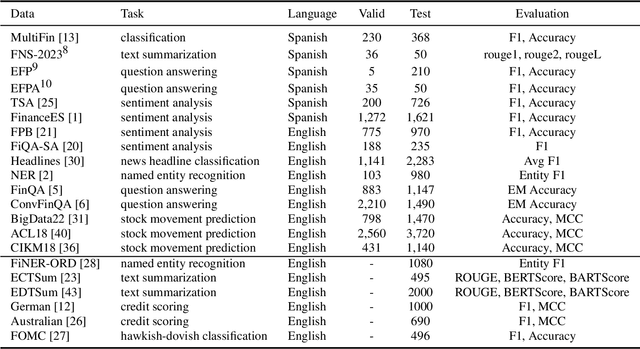
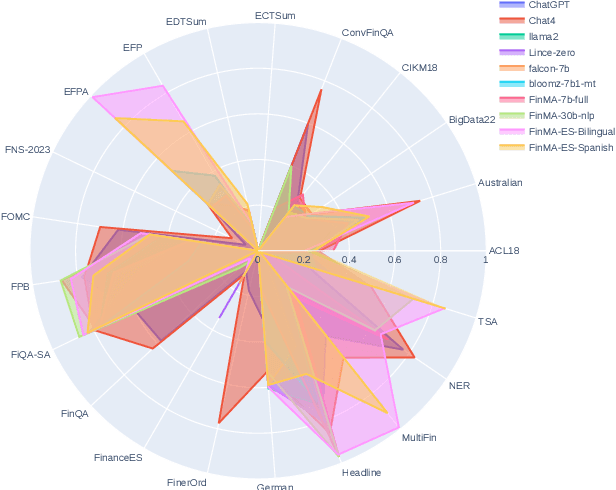
Despite Spanish's pivotal role in the global finance industry, a pronounced gap exists in Spanish financial natural language processing (NLP) and application studies compared to English, especially in the era of large language models (LLMs). To bridge this gap, we unveil Tois\'on de Oro, the first bilingual framework that establishes instruction datasets, finetuned LLMs, and evaluation benchmark for financial LLMs in Spanish joint with English. We construct a rigorously curated bilingual instruction dataset including over 144K Spanish and English samples from 15 datasets covering 7 tasks. Harnessing this, we introduce FinMA-ES, an LLM designed for bilingual financial applications. We evaluate our model and existing LLMs using FLARE-ES, the first comprehensive bilingual evaluation benchmark with 21 datasets covering 9 tasks. The FLARE-ES benchmark results reveal a significant multilingual performance gap and bias in existing LLMs. FinMA-ES models surpass SOTA LLMs such as GPT-4 in Spanish financial tasks, due to strategic instruction tuning and leveraging data from diverse linguistic resources, highlighting the positive impact of cross-linguistic transfer. All our datasets, models, and benchmarks have been released.
LAiW: A Chinese Legal Large Language Models Benchmark
Oct 09, 2023With the emergence of numerous legal LLMs, there is currently a lack of a comprehensive benchmark for evaluating their legal abilities. In this paper, we propose the first Chinese Legal LLMs benchmark based on legal capabilities. Through the collaborative efforts of legal and artificial intelligence experts, we divide the legal capabilities of LLMs into three levels: basic legal NLP capability, basic legal application capability, and complex legal application capability. We have completed the first phase of evaluation, which mainly focuses on the capability of basic legal NLP. The evaluation results show that although some legal LLMs have better performance than their backbones, there is still a gap compared to ChatGPT. Our benchmark can be found at URL.
Empowering Many, Biasing a Few: Generalist Credit Scoring through Large Language Models
Oct 01, 2023



Credit and risk assessments are cornerstones of the financial landscape, impacting both individual futures and broader societal constructs. Existing credit scoring models often exhibit limitations stemming from knowledge myopia and task isolation. In response, we formulate three hypotheses and undertake an extensive case study to investigate LLMs' viability in credit assessment. Our empirical investigations unveil LLMs' ability to overcome the limitations inherent in conventional models. We introduce a novel benchmark curated for credit assessment purposes, fine-tune a specialized Credit and Risk Assessment Large Language Model (CALM), and rigorously examine the biases that LLMs may harbor. Our findings underscore LLMs' potential in revolutionizing credit assessment, showcasing their adaptability across diverse financial evaluations, and emphasizing the critical importance of impartial decision-making in the financial sector. Our datasets, models, and benchmarks are open-sourced for other researchers.
PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance
Jun 08, 2023
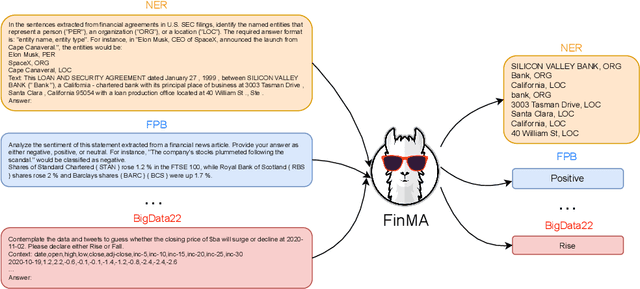
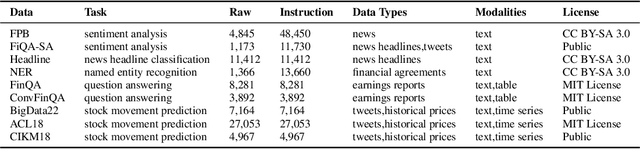

Although large language models (LLMs) has shown great performance on natural language processing (NLP) in the financial domain, there are no publicly available financial tailtored LLMs, instruction tuning datasets, and evaluation benchmarks, which is critical for continually pushing forward the open-source development of financial artificial intelligence (AI). This paper introduces PIXIU, a comprehensive framework including the first financial LLM based on fine-tuning LLaMA with instruction data, the first instruction data with 136K data samples to support the fine-tuning, and an evaluation benchmark with 5 tasks and 9 datasets. We first construct the large-scale multi-task instruction data considering a variety of financial tasks, financial document types, and financial data modalities. We then propose a financial LLM called FinMA by fine-tuning LLaMA with the constructed dataset to be able to follow instructions for various financial tasks. To support the evaluation of financial LLMs, we propose a standardized benchmark that covers a set of critical financial tasks, including five financial NLP tasks and one financial prediction task. With this benchmark, we conduct a detailed analysis of FinMA and several existing LLMs, uncovering their strengths and weaknesses in handling critical financial tasks. The model, datasets, benchmark, and experimental results are open-sourced to facilitate future research in financial AI.
The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges
Apr 28, 2023



Recently, large language models (LLMs) like ChatGPT have demonstrated remarkable performance across a variety of natural language processing tasks. However, their effectiveness in the financial domain, specifically in predicting stock market movements, remains to be explored. In this paper, we conduct an extensive zero-shot analysis of ChatGPT's capabilities in multimodal stock movement prediction, on three tweets and historical stock price datasets. Our findings indicate that ChatGPT is a "Wall Street Neophyte" with limited success in predicting stock movements, as it underperforms not only state-of-the-art methods but also traditional methods like linear regression using price features. Despite the potential of Chain-of-Thought prompting strategies and the inclusion of tweets, ChatGPT's performance remains subpar. Furthermore, we observe limitations in its explainability and stability, suggesting the need for more specialized training or fine-tuning. This research provides insights into ChatGPT's capabilities and serves as a foundation for future work aimed at improving financial market analysis and prediction by leveraging social media sentiment and historical stock data.