 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Boundaries of Natural Reasoning: Interleaved Bonus from Formal-Logic Verification
Jan 30, 2026Large Language Models (LLMs) show remarkable capabilities, yet their stochastic next-token prediction creates logical inconsistencies and reward hacking that formal symbolic systems avoid. To bridge this gap, we introduce a formal logic verification-guided framework that dynamically interleaves formal symbolic verification with the natural language generation process, providing real-time feedback to detect and rectify errors as they occur. Distinguished from previous neuro-symbolic methods limited by passive post-hoc validation, our approach actively penalizes intermediate fallacies during the reasoning chain. We operationalize this framework via a novel two-stage training pipeline that synergizes formal logic verification-guided supervised fine-tuning and policy optimization. Extensive evaluation on six benchmarks spanning mathematical, logical, and general reasoning demonstrates that our 7B and 14B models outperform state-of-the-art baselines by average margins of 10.4% and 14.2%, respectively. These results validate that formal verification can serve as a scalable mechanism to significantly push the performance boundaries of advanced LLM reasoning.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Simple Denoising Diffusion Language Models
Oct 27, 2025Diffusion models have recently been extended to language generation through Masked Diffusion Language Models (MDLMs), which achieve performance competitive with strong autoregressive models. However, MDLMs tend to degrade in the few-step regime and cannot directly adopt existing few-step distillation methods designed for continuous diffusion models, as they lack the intrinsic property of mapping from noise to data. Recent Uniform-state Diffusion Models (USDMs), initialized from a uniform prior, alleviate some limitations but still suffer from complex loss formulations that hinder scalability. In this work, we propose a simplified denoising-based loss for USDMs that optimizes only noise-replaced tokens, stabilizing training and matching ELBO-level performance. Furthermore, by framing denoising as self-supervised learning, we introduce a simple modification to our denoising loss with contrastive-inspired negative gradients, which is practical and yield additional improvements in generation quality.
Leveraging LLM-Based Agents for Intelligent Supply Chain Planning
Sep 04, 2025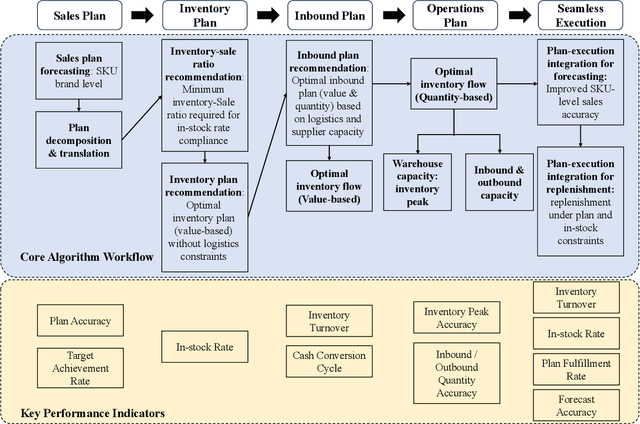
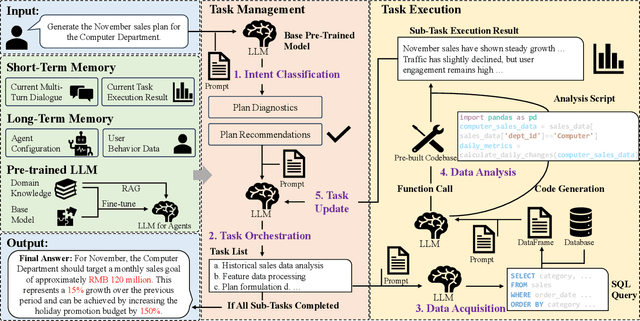
In supply chain management, planning is a critical concept. The movement of physical products across different categories, from suppliers to warehouse management, to sales, and logistics transporting them to customers, entails the involvement of many entities. It covers various aspects such as demand forecasting, inventory management, sales operations, and replenishment. How to collect relevant data from an e-commerce platform's perspective, formulate long-term plans, and dynamically adjust them based on environmental changes, while ensuring interpretability, efficiency, and reliability, is a practical and challenging problem. In recent years, the development of AI technologies, especially the rapid progress of large language models, has provided new tools to address real-world issues. In this work, we construct a Supply Chain Planning Agent (SCPA) framework that can understand domain knowledge, comprehend the operator's needs, decompose tasks, leverage or create new tools, and return evidence-based planning reports. We deploy this framework in JD.com's real-world scenario, demonstrating the feasibility of LLM-agent applications in the supply chain. It effectively reduced labor and improved accuracy, stock availability, and other key metrics.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
Text-RGBT Person Retrieval: Multilevel Global-Local Cross-Modal Alignment and A High-quality Benchmark
Mar 11, 2025The performance of traditional text-image person retrieval task is easily affected by lighting variations due to imaging limitations of visible spectrum sensors. In this work, we design a novel task called text-RGBT person retrieval that integrates complementary benefits from thermal and visible modalities for robust person retrieval in challenging environments. Aligning text and multi-modal visual representations is the key issue in text-RGBT person retrieval, but the heterogeneity between visible and thermal modalities may interfere with the alignment of visual and text modalities. To handle this problem, we propose a Multi-level Global-local cross-modal Alignment Network (MGANet), which sufficiently mines the relationships between modality-specific and modality-collaborative visual with the text, for text-RGBT person retrieval. To promote the research and development of this field, we create a high-quality text-RGBT person retrieval dataset, RGBT-PEDES. RGBT-PEDES contains 1,822 identities from different age groups and genders with 4,723 pairs of calibrated RGB and thermal images, and covers high-diverse scenes from both daytime and nighttime with a various of challenges such as occlusion, weak alignment and adverse lighting conditions. Additionally, we carefully annotate 7,987 fine-grained textual descriptions for all RGBT person image pairs. Extensive experiments on RGBT-PEDES demonstrate that our method outperforms existing text-image person retrieval methods. The code and dataset will be released upon the acceptance.
On a Connection Between Imitation Learning and RLHF
Mar 07, 2025This work studies the alignment of large language models with preference data from an imitation learning perspective. We establish a close theoretical connection between reinforcement learning from human feedback RLHF and imitation learning (IL), revealing that RLHF implicitly performs imitation learning on the preference data distribution. Building on this connection, we propose DIL, a principled framework that directly optimizes the imitation learning objective. DIL provides a unified imitation learning perspective on alignment, encompassing existing alignment algorithms as special cases while naturally introducing new variants. By bridging IL and RLHF, DIL offers new insights into alignment with RLHF. Extensive experiments demonstrate that DIL outperforms existing methods on various challenging benchmarks.
SampleMix: A Sample-wise Pre-training Data Mixing Strategey by Coordinating Data Quality and Diversity
Mar 03, 2025Existing pretraining data mixing methods for large language models (LLMs) typically follow a domain-wise methodology, a top-down process that first determines domain weights and then performs uniform data sampling across each domain. However, these approaches neglect significant inter-domain overlaps and commonalities, failing to control the global diversity of the constructed training dataset. Further, uniform sampling within domains ignores fine-grained sample-specific features, potentially leading to suboptimal data distribution. To address these shortcomings, we propose a novel sample-wise data mixture approach based on a bottom-up paradigm. This method performs global cross-domain sampling by systematically evaluating the quality and diversity of each sample, thereby dynamically determining the optimal domain distribution. Comprehensive experiments across multiple downstream tasks and perplexity assessments demonstrate that SampleMix surpasses existing domain-based methods. Meanwhile, SampleMix requires 1.4x to 2.1x training steps to achieves the baselines' performance, highlighting the substantial potential of SampleMix to optimize pre-training data.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025
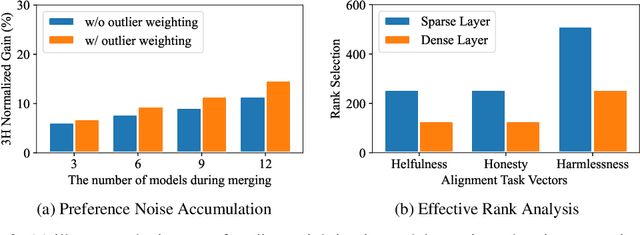

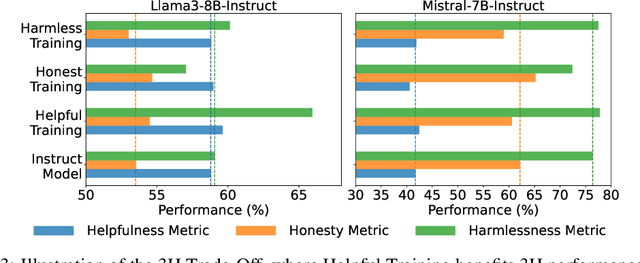
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Enhancing Financial Time-Series Forecasting with Retrieval-Augmented Large Language Models
Feb 11, 2025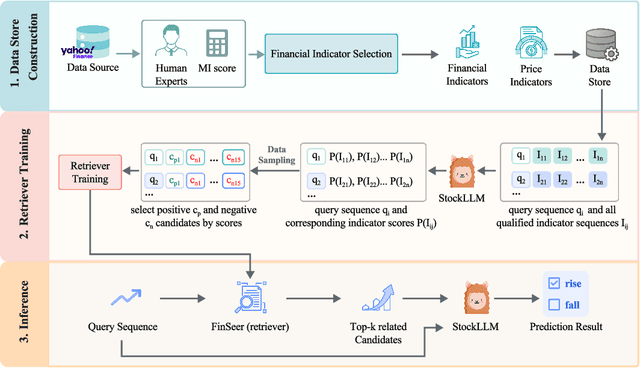

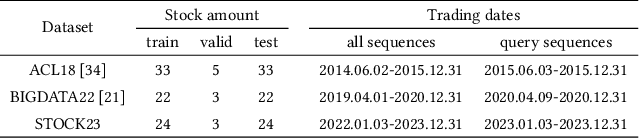
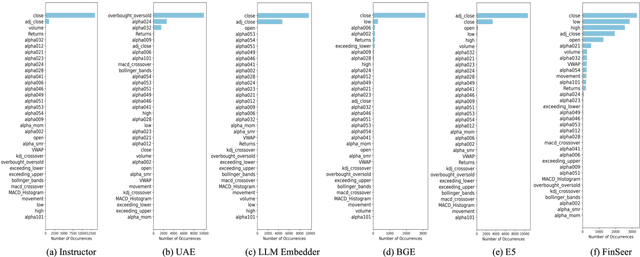
Stock movement prediction, a critical task in financial time-series forecasting, relies on identifying and retrieving key influencing factors from vast and complex datasets. However, traditional text-trained or numeric similarity-based retrieval methods often struggle to handle the intricacies of financial data. To address this, we propose the first retrieval-augmented generation (RAG) framework specifically designed for financial time-series forecasting. Our framework incorporates three key innovations: a fine-tuned 1B large language model (StockLLM) as its backbone, a novel candidate selection method enhanced by LLM feedback, and a training objective that maximizes the similarity between queries and historically significant sequences. These advancements enable our retriever, FinSeer, to uncover meaningful patterns while effectively minimizing noise in complex financial datasets. To support robust evaluation, we also construct new datasets that integrate financial indicators and historical stock prices. Experimental results demonstrate that our RAG framework outperforms both the baseline StockLLM and random retrieval methods, showcasing its effectiveness. FinSeer, as the retriever, achieves an 8% higher accuracy on the BIGDATA22 benchmark and retrieves more impactful sequences compared to existing retrieval methods. This work highlights the importance of tailored retrieval models in financial forecasting and provides a novel, scalable framework for future research in the field.