 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Really Improves Mathematical Reasoning: Structured Reasoning Signals Beyond Pure Code
May 19, 2026Code has become a standard component of modern foundation language model (LM) training, yet its role beyond programming remains unclear. We revisit the claim that code improves reasoning through controlled pretraining experiments on a 10T-token corpus with fine-grained domain separation. Our findings are threefold. First, when code is restricted to standalone executable programs and Code-NL data are controlled for, code substantially improves programming ability but does not act as a general reasoning enhancer; instead, it competes with knowledge-intensive tasks, especially complex mathematical reasoning. Second, the reasoning gains often attributed to code are better explained by cross-domain structured reasoning traces, such as code-text and math-text mixtures, rather than by executable code alone. Third, increasing the density of structured math-domain samples within a fixed math budget yields substantial gains on difficult mathematical reasoning while largely preserving programming performance, suggesting that cognitive scaffolds offer a targeted way to mitigate cross-domain trade-offs. Finally, routing analyses show that data-composition effects are reflected in expert-activation patterns, providing mechanism-level evidence for competitive and synergistic interactions across domains. Our results clarify which data characteristics transfer across capability dimensions and point to more precise data-centric optimization strategies.
DiffScore: Text Evaluation Beyond Autoregressive Likelihood
May 12, 2026Autoregressive language models are widely used for text evaluation, however, their left-to-right factorization introduces positional bias, i.e., early tokens are scored with only leftward context, conflating architectural asymmetry with true text quality. We propose masked reconstruction as an alternative paradigm, where every token is scored using full bidirectional context. We introduce DiffScore, an evaluation framework built on Masked Large Diffusion Language Models. By measuring text recoverability across continuous masking rates, DiffScore eliminates positional bias and naturally establishes an evaluation hierarchy from local fluency to global coherence. We further provide diagnostic tools unavailable to autoregressive frameworks: multi-timestep quality profiles that decompose scores across masking rates, and bidirectional PMI decomposition that disentangles fluency from faithfulness. Experiments across ten benchmarks show that DiffScore consistently outperforms autoregressive baselines in both zero-shot and fine-tuned settings. The code is released at: https://github.com/wenlai-lavine/DiffScore.
On Representation Redundancy in Large-Scale Instruction Tuning Data Selection
Feb 14, 2026Data quality is a crucial factor in large language models training. While prior work has shown that models trained on smaller, high-quality datasets can outperform those trained on much larger but noisy or low-quality corpora, systematic methods for industrial-scale data selection in instruction tuning remain underexplored. In this work, we study instruction-tuning data selection through the lens of semantic representation similarity and identify a key limitation of state-of-the-art LLM encoders: they produce highly redundant semantic embeddings. To mitigate this redundancy, we propose Compressed Representation Data Selection (CRDS), a novel framework with two variants. CRDS-R applies Rademacher random projection followed by concatenation of transformer hidden-layer representations, while CRDS-W employs whitening-based dimensionality reduction to improve representational quality. Experimental results demonstrate that both variants substantially enhance data quality and consistently outperform state-of-the-art representation-based selection methods. Notably, CRDS-W achieves strong performance using only 3.5% of the data, surpassing the full-data baseline by an average of 0.71% across four datasets. Our code is available at https://github.com/tdano1/CRDS.
UniGeM: Unifying Data Mixing and Selection via Geometric Exploration and Mining
Feb 03, 2026The scaling of Large Language Models (LLMs) is increasingly limited by data quality. Most methods handle data mixing and sample selection separately, which can break the structure in code corpora. We introduce \textbf{UniGeM}, a framework that unifies mixing and selection by treating data curation as a \textit{manifold approximation} problem without training proxy models or relying on external reference datasets. UniGeM operates hierarchically: \textbf{Macro-Exploration} learns mixing weights with stability-based clustering; \textbf{Micro-Mining} filters high-quality instances by their geometric distribution to ensure logical consistency. Validated by training 8B and 16B MoE models on 100B tokens, UniGeM achieves \textbf{2.0$\times$ data efficiency} over a random baseline and further improves overall performance compared to SOTA methods in reasoning-heavy evaluations and multilingual generalization.
Ring-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
SHARP: Synthesizing High-quality Aligned Reasoning Problems for Large Reasoning Models Reinforcement Learning
May 21, 2025Training large reasoning models (LRMs) with reinforcement learning in STEM domains is hindered by the scarcity of high-quality, diverse, and verifiable problem sets. Existing synthesis methods, such as Chain-of-Thought prompting, often generate oversimplified or uncheckable data, limiting model advancement on complex tasks. To address these challenges, we introduce SHARP, a unified approach to Synthesizing High-quality Aligned Reasoning Problems for LRMs reinforcement learning with verifiable rewards (RLVR). SHARP encompasses a strategic set of self-alignment principles -- targeting graduate and Olympiad-level difficulty, rigorous logical consistency, and unambiguous, verifiable answers -- and a structured three-phase framework (Alignment, Instantiation, Inference) that ensures thematic diversity and fine-grained control over problem generation. We implement SHARP by leveraging a state-of-the-art LRM to infer and verify challenging STEM questions, then employ a reinforcement learning loop to refine the model's reasoning through verifiable reward signals. Experiments on benchmarks such as GPQA demonstrate that SHARP-augmented training substantially outperforms existing methods, markedly improving complex reasoning accuracy and pushing LRM performance closer to expert-level proficiency. Our contributions include the SHARP strategy, framework design, end-to-end implementation, and experimental evaluation of its effectiveness in elevating LRM reasoning capabilities.
MASS: Mathematical Data Selection via Skill Graphs for Pretraining Large Language Models
Mar 19, 2025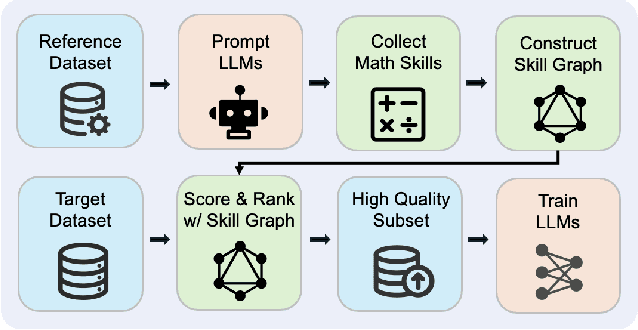

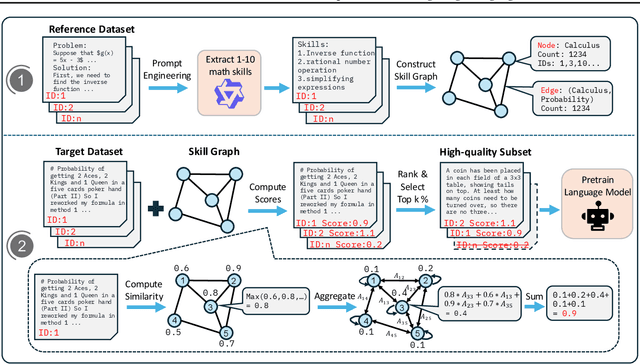

High-quality data plays a critical role in the pretraining and fine-tuning of large language models (LLMs), even determining their performance ceiling to some degree. Consequently, numerous data selection methods have been proposed to identify subsets of data that can effectively and efficiently enhance model performance. However, most of these methods focus on general data selection and tend to overlook the specific nuances of domain-related data. In this paper, we introduce MASS, a \textbf{MA}thematical data \textbf{S}election framework using the \textbf{S}kill graph for pretraining LLMs in the mathematical reasoning domain. By taking into account the unique characteristics of mathematics and reasoning, we construct a skill graph that captures the mathematical skills and their interrelations from a reference dataset. This skill graph guides us in assigning quality scores to the target dataset, enabling us to select the top-ranked subset which is further used to pretrain LLMs. Experimental results demonstrate the efficiency and effectiveness of MASS across different model sizes (1B and 7B) and pretraining datasets (web data and synthetic data). Specifically, in terms of efficiency, models trained on subsets selected by MASS can achieve similar performance to models trained on the original datasets, with a significant reduction in the number of trained tokens - ranging from 50\% to 70\% fewer tokens. In terms of effectiveness, when trained on the same amount of tokens, models trained on the data selected by MASS outperform those trained on the original datasets by 3.3\% to 5.9\%. These results underscore the potential of MASS to improve both the efficiency and effectiveness of pretraining LLMs.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025
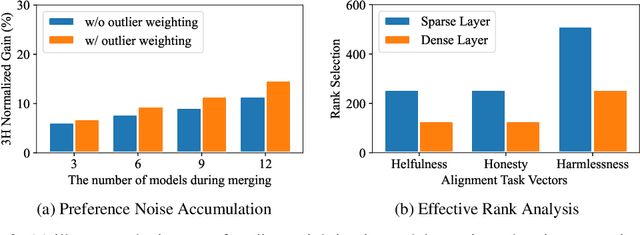

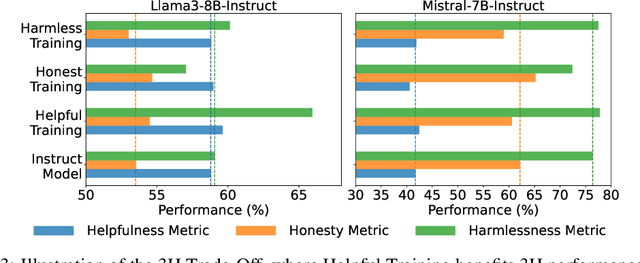
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
Combining Incomplete Observational and Randomized Data for Heterogeneous Treatment Effects
Oct 28, 2024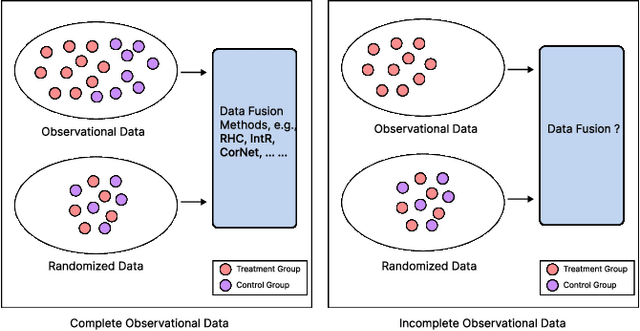
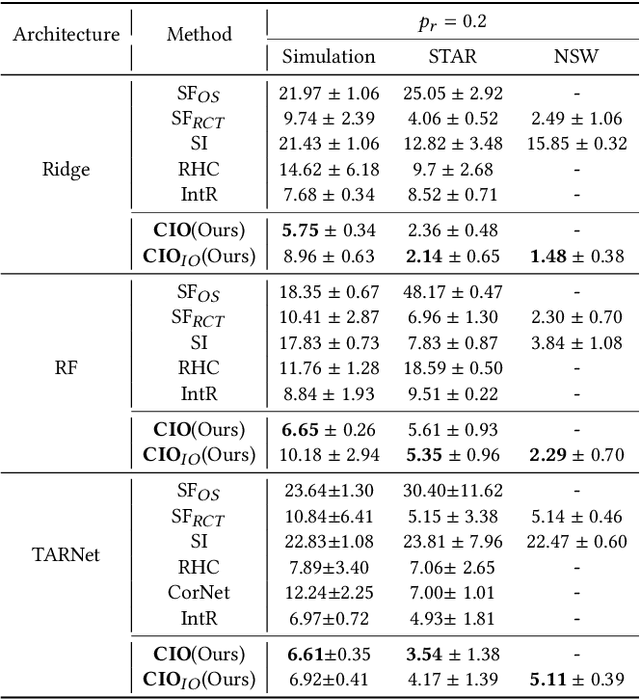
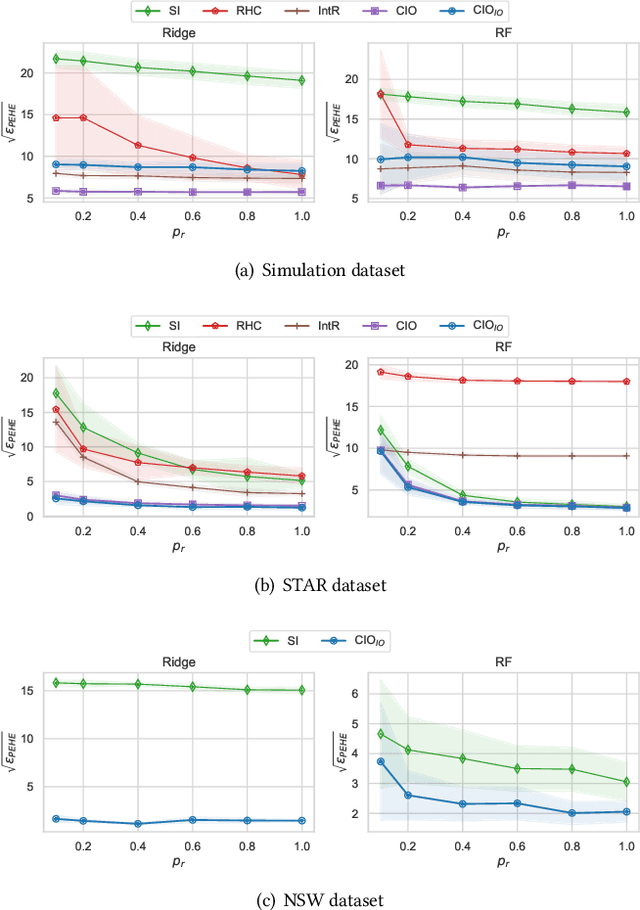
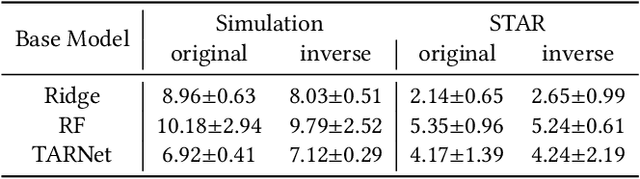
Data from observational studies (OSs) is widely available and readily obtainable yet frequently contains confounding biases. On the other hand, data derived from randomized controlled trials (RCTs) helps to reduce these biases; however, it is expensive to gather, resulting in a tiny size of randomized data. For this reason, effectively fusing observational data and randomized data to better estimate heterogeneous treatment effects (HTEs) has gained increasing attention. However, existing methods for integrating observational data with randomized data must require \textit{complete} observational data, meaning that both treated subjects and untreated subjects must be included in OSs. This prerequisite confines the applicability of such methods to very specific situations, given that including all subjects, whether treated or untreated, in observational studies is not consistently achievable. In our paper, we propose a resilient approach to \textbf{C}ombine \textbf{I}ncomplete \textbf{O}bservational data and randomized data for HTE estimation, which we abbreviate as \textbf{CIO}. The CIO is capable of estimating HTEs efficiently regardless of the completeness of the observational data, be it full or partial. Concretely, a confounding bias function is first derived using the pseudo-experimental group from OSs, in conjunction with the pseudo-control group from RCTs, via an effect estimation procedure. This function is subsequently utilized as a corrective residual to rectify the observed outcomes of observational data during the HTE estimation by combining the available observational data and the all randomized data. To validate our approach, we have conducted experiments on a synthetic dataset and two semi-synthetic datasets.