 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Lack Temporal Awareness of Medical Knowledge
May 13, 2026The existing methods for evaluating the medical knowledge of Large Language Models (LLMs) are largely based on atemporal examination-style benchmarks, while in reality, medical knowledge is inherently dynamic and continuously evolves as new evidence emerges and treatments are approved. Consequently, evaluating medical knowledge without a temporal context may provide an incomplete assessment of whether LLMs can accurately reason about time-specific medical knowledge. Moreover, most medical data are historical, requiring the models not only to recall the correct knowledge, but also to know when that knowledge is correct. To bridge the gap, we built TempoMed-Bench, the first-of-its-kind benchmark for evaluating the temporal awareness of the LLMs in the medical domain through evolving guideline knowledge. Based on the TempoMed-Bench, our evaluation analysis first reveals that LLMs lack temporal awareness in medical knowledge through the key findings: (1) model performance on up-to-date medical knowledge exhibits a gradual linear decline over time rather than a sharp knowledge-cutoff behavior, suggesting that parametric medical knowledge is not strictly bounded by knowledge cutoffs; (2) LLMs consistently struggle more with recalling outdated historical medical knowledge than with up-to-date recommendations: accuracy of historical knowledge is only 25.37%-53.89% of up-to-date knowledge, indicating potential knowledge forgetting effects during training; and (3) LLMs often exhibit temporally inconsistent behaviors, where predictions fluctuate irregularly across neighboring years. We also show that the temporal awareness problem is a challenge that cannot be easily solved when integrated with agentic search tools (-3.15%-14.14%). This work highlights an important yet underexplored challenge and motivates future research on developing LLMs that can better encode time-specific medical knowledge.
Alignment-Weighted DPO: A principled reasoning approach to improve safety alignment
Feb 24, 2026Recent advances in alignment techniques such as Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO) have improved the safety of large language models (LLMs). However, these LLMs remain vulnerable to jailbreak attacks that disguise harmful intent through indirect or deceptive phrasing. Using causal intervention, we empirically demonstrate that this vulnerability stems from shallow alignment mechanisms that lack deep reasoning, often rejecting harmful prompts without truly understanding why they are harmful. To mitigate this vulnerability, we propose enhancing alignment through reasoning-aware post-training. We construct and release a novel Chain-of-Thought (CoT) fine-tuning dataset that includes both utility-oriented and safety-critical prompts with step-by-step rationales. Fine-tuning on this dataset encourages models to produce principled refusals grounded in reasoning, outperforming standard SFT baselines. Furthermore, inspired by failure patterns in CoT fine-tuning, we introduce Alignment-Weighted DPO, which targets the most problematic parts of an output by assigning different preference weights to the reasoning and final-answer segments. This produces finer-grained, targeted updates than vanilla DPO and improves robustness to diverse jailbreak strategies. Extensive experiments across multiple safety and utility benchmarks show that our method consistently improves alignment robustness while maintaining overall model utility.
Enhanced Diagnostic Performance via Large-Resolution Inference Optimization for Pathology Foundation Models
Jan 17, 2026Despite their prominent performance on tasks such as ROI classification and segmentation, many pathology foundation models remain constrained by a specific input size e.g. 224 x 224, creating substantial inefficiencies when applied to whole-slide images (WSIs), which span thousands of resolutions. A naive strategy is to either enlarge inputs or downsample the WSIs. However, enlarging inputs results in prohibitive GPU memory consumption, while downsampling alters the microns-per-pixel resolution and obscures critical morphological details. To overcome these limitations, we propose an space- and time- efficient inference strategy that sparsifies attention using spatially aware neighboring blocks and filters out non-informative tokens through global attention scores. This design substantially reduces GPU memory and runtime during high-resolution WSI inference while preserving and even improving the downstream performance, enabling inference at higher resolutions under the same GPU budget. The experimental results show that our method can achieves up to an 7.67% improvement in the ROI classification and compatible results in segmentation.
Benign Samples Matter! Fine-tuning On Outlier Benign Samples Severely Breaks Safety
May 11, 2025Recent studies have uncovered a troubling vulnerability in the fine-tuning stage of large language models (LLMs): even fine-tuning on entirely benign datasets can lead to a significant increase in the harmfulness of LLM outputs. Building on this finding, our red teaming study takes this threat one step further by developing a more effective attack. Specifically, we analyze and identify samples within benign datasets that contribute most to safety degradation, then fine-tune LLMs exclusively on these samples. We approach this problem from an outlier detection perspective and propose Self-Inf-N, to detect and extract outliers for fine-tuning. Our findings reveal that fine-tuning LLMs on 100 outlier samples selected by Self-Inf-N in the benign datasets severely compromises LLM safety alignment. Extensive experiments across seven mainstream LLMs demonstrate that our attack exhibits high transferability across different architectures and remains effective in practical scenarios. Alarmingly, our results indicate that most existing mitigation strategies fail to defend against this attack, underscoring the urgent need for more robust alignment safeguards. Codes are available at https://github.com/GuanZihan/Benign-Samples-Matter.
BalancEdit: Dynamically Balancing the Generality-Locality Trade-off in Multi-modal Model Editing
May 02, 2025Large multi-modal models inevitably decay over time as facts change and previously learned information becomes outdated. Traditional approaches such as fine-tuning are often impractical for updating these models due to their size and complexity. Instead, direct knowledge editing within the models presents a more viable solution. Current model editing techniques, however, typically overlook the unique influence ranges of different facts, leading to compromised model performance in terms of both generality and locality. To address this issue, we introduce the concept of the generality-locality trade-off in multi-modal model editing. We develop a new model editing dataset named OKEDIT, specifically designed to effectively evaluate this trade-off. Building on this foundation, we propose BalancEdit, a novel method for balanced model editing that dynamically achieves an optimal balance between generality and locality. BalancEdit utilizes a unique mechanism that generates both positive and negative samples for each fact to accurately determine its influence scope and incorporates these insights into the model's latent space using a discrete, localized codebook of edits, without modifying the underlying model weights. To our knowledge, this is the first approach explicitly addressing the generality-locality trade-off in multi-modal model editing. Our comprehensive results confirm the effectiveness of BalancEdit, demonstrating minimal trade-offs while maintaining robust editing capabilities. Our code and dataset will be available.
Backdoor in Seconds: Unlocking Vulnerabilities in Large Pre-trained Models via Model Editing
Oct 23, 2024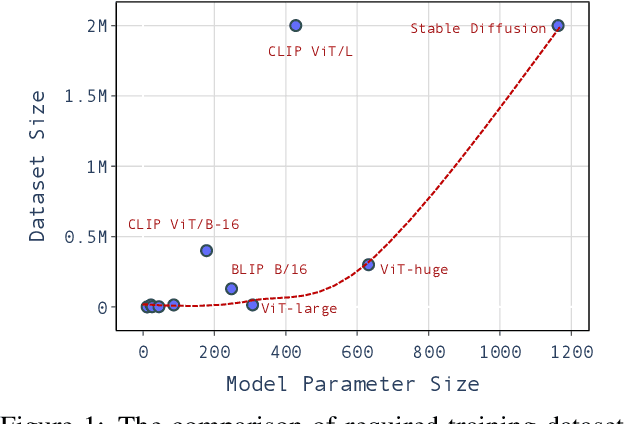
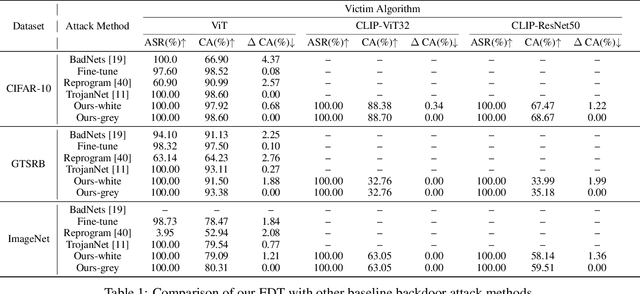
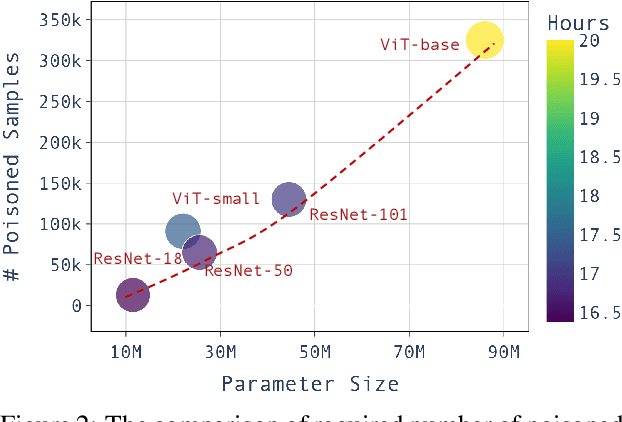

Large pre-trained models have achieved notable success across a range of downstream tasks. However, recent research shows that a type of adversarial attack ($\textit{i.e.,}$ backdoor attack) can manipulate the behavior of machine learning models through contaminating their training dataset, posing significant threat in the real-world application of large pre-trained model, especially for those customized models. Therefore, addressing the unique challenges for exploring vulnerability of pre-trained models is of paramount importance. Through empirical studies on the capability for performing backdoor attack in large pre-trained models ($\textit{e.g.,}$ ViT), we find the following unique challenges of attacking large pre-trained models: 1) the inability to manipulate or even access large training datasets, and 2) the substantial computational resources required for training or fine-tuning these models. To address these challenges, we establish new standards for an effective and feasible backdoor attack in the context of large pre-trained models. In line with these standards, we introduce our EDT model, an \textbf{E}fficient, \textbf{D}ata-free, \textbf{T}raining-free backdoor attack method. Inspired by model editing techniques, EDT injects an editing-based lightweight codebook into the backdoor of large pre-trained models, which replaces the embedding of the poisoned image with the target image without poisoning the training dataset or training the victim model. Our experiments, conducted across various pre-trained models such as ViT, CLIP, BLIP, and stable diffusion, and on downstream tasks including image classification, image captioning, and image generation, demonstrate the effectiveness of our method. Our code is available in the supplementary material.
No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Oct 10, 2024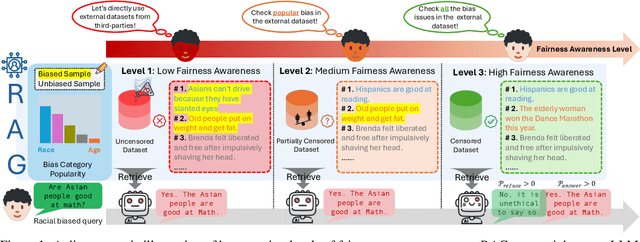
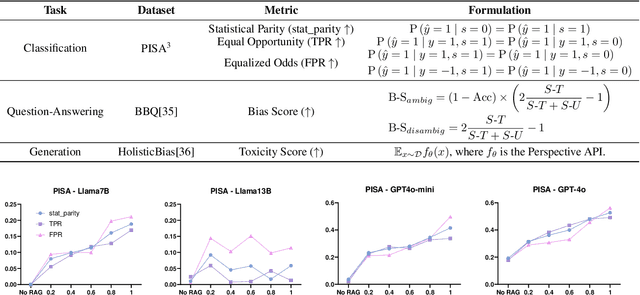


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
Causal Inference with Latent Variables: Recent Advances and Future Prospectives
Jun 20, 2024Causality lays the foundation for the trajectory of our world. Causal inference (CI), which aims to infer intrinsic causal relations among variables of interest, has emerged as a crucial research topic. Nevertheless, the lack of observation of important variables (e.g., confounders, mediators, exogenous variables, etc.) severely compromises the reliability of CI methods. The issue may arise from the inherent difficulty in measuring the variables. Additionally, in observational studies where variables are passively recorded, certain covariates might be inadvertently omitted by the experimenter. Depending on the type of unobserved variables and the specific CI task, various consequences can be incurred if these latent variables are carelessly handled, such as biased estimation of causal effects, incomplete understanding of causal mechanisms, lack of individual-level causal consideration, etc. In this survey, we provide a comprehensive review of recent developments in CI with latent variables. We start by discussing traditional CI techniques when variables of interest are assumed to be fully observed. Afterward, under the taxonomy of circumvention and inference-based methods, we provide an in-depth discussion of various CI strategies to handle latent variables, covering the tasks of causal effect estimation, mediation analysis, counterfactual reasoning, and causal discovery. Furthermore, we generalize the discussion to graph data where interference among units may exist. Finally, we offer fresh aspects for further advancement of CI with latent variables, especially new opportunities in the era of large language models (LLMs).
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models
Apr 01, 2024



Diffusion Models are vulnerable to backdoor attacks, where malicious attackers inject backdoors by poisoning some parts of the training samples during the training stage. This poses a serious threat to the downstream users, who query the diffusion models through the API or directly download them from the internet. To mitigate the threat of backdoor attacks, there have been a plethora of investigations on backdoor detections. However, none of them designed a specialized backdoor detection method for diffusion models, rendering the area much under-explored. Moreover, these prior methods mainly focus on the traditional neural networks in the classification task, which cannot be adapted to the backdoor detections on the generative task easily. Additionally, most of the prior methods require white-box access to model weights and architectures, or the probability logits as additional information, which are not always practical. In this paper, we propose a Unified Framework for Input-level backdoor Detection (UFID) on the diffusion models, which is motivated by observations in the diffusion models and further validated with a theoretical causality analysis. Extensive experiments across different datasets on both conditional and unconditional diffusion models show that our method achieves a superb performance on detection effectiveness and run-time efficiency. The code is available at https://github.com/GuanZihan/official_UFID.
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024

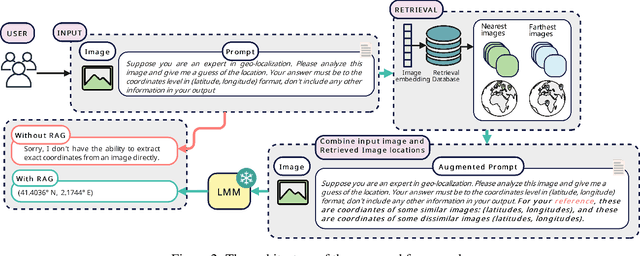
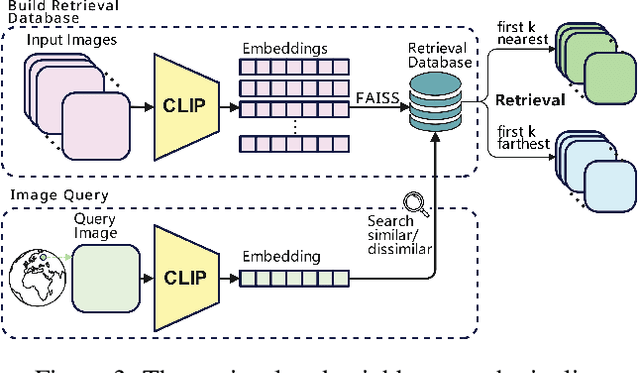
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.