 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenign Samples Matter! Fine-tuning On Outlier Benign Samples Severely Breaks Safety
May 11, 2025Recent studies have uncovered a troubling vulnerability in the fine-tuning stage of large language models (LLMs): even fine-tuning on entirely benign datasets can lead to a significant increase in the harmfulness of LLM outputs. Building on this finding, our red teaming study takes this threat one step further by developing a more effective attack. Specifically, we analyze and identify samples within benign datasets that contribute most to safety degradation, then fine-tune LLMs exclusively on these samples. We approach this problem from an outlier detection perspective and propose Self-Inf-N, to detect and extract outliers for fine-tuning. Our findings reveal that fine-tuning LLMs on 100 outlier samples selected by Self-Inf-N in the benign datasets severely compromises LLM safety alignment. Extensive experiments across seven mainstream LLMs demonstrate that our attack exhibits high transferability across different architectures and remains effective in practical scenarios. Alarmingly, our results indicate that most existing mitigation strategies fail to defend against this attack, underscoring the urgent need for more robust alignment safeguards. Codes are available at https://github.com/GuanZihan/Benign-Samples-Matter.
No Free Lunch: Retrieval-Augmented Generation Undermines Fairness in LLMs, Even for Vigilant Users
Oct 10, 2024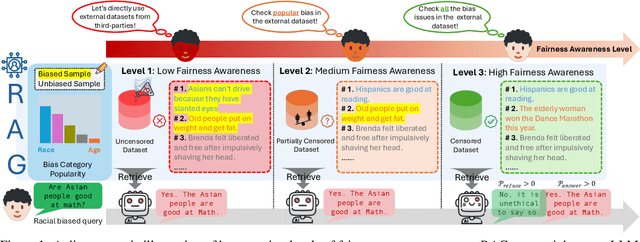
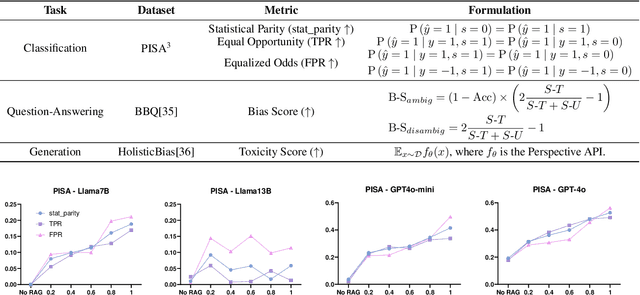


Retrieval-Augmented Generation (RAG) is widely adopted for its effectiveness and cost-efficiency in mitigating hallucinations and enhancing the domain-specific generation capabilities of large language models (LLMs). However, is this effectiveness and cost-efficiency truly a free lunch? In this study, we comprehensively investigate the fairness costs associated with RAG by proposing a practical three-level threat model from the perspective of user awareness of fairness. Specifically, varying levels of user fairness awareness result in different degrees of fairness censorship on the external dataset. We examine the fairness implications of RAG using uncensored, partially censored, and fully censored datasets. Our experiments demonstrate that fairness alignment can be easily undermined through RAG without the need for fine-tuning or retraining. Even with fully censored and supposedly unbiased external datasets, RAG can lead to biased outputs. Our findings underscore the limitations of current alignment methods in the context of RAG-based LLMs and highlight the urgent need for new strategies to ensure fairness. We propose potential mitigations and call for further research to develop robust fairness safeguards in RAG-based LLMs.
Trustworthy Representation Learning Across Domains
Aug 29, 2023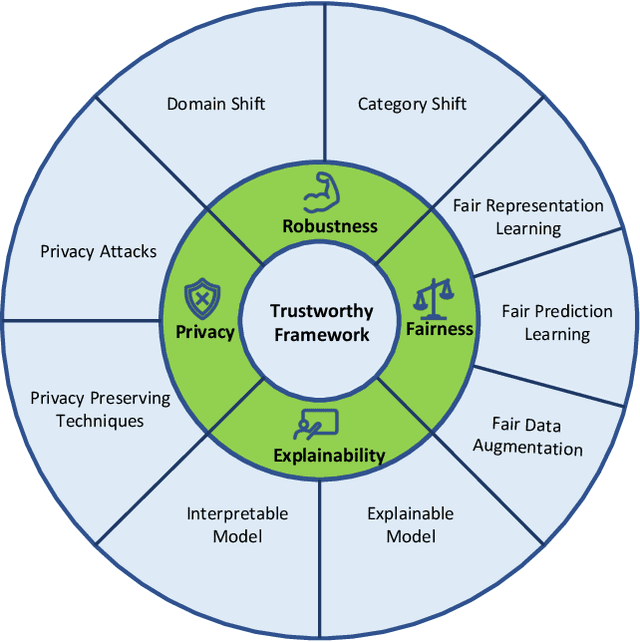


As AI systems have obtained significant performance to be deployed widely in our daily live and human society, people both enjoy the benefits brought by these technologies and suffer many social issues induced by these systems. To make AI systems good enough and trustworthy, plenty of researches have been done to build guidelines for trustworthy AI systems. Machine learning is one of the most important parts for AI systems and representation learning is the fundamental technology in machine learning. How to make the representation learning trustworthy in real-world application, e.g., cross domain scenarios, is very valuable and necessary for both machine learning and AI system fields. Inspired by the concepts in trustworthy AI, we proposed the first trustworthy representation learning across domains framework which includes four concepts, i.e, robustness, privacy, fairness, and explainability, to give a comprehensive literature review on this research direction. Specifically, we first introduce the details of the proposed trustworthy framework for representation learning across domains. Second, we provide basic notions and comprehensively summarize existing methods for the trustworthy framework from four concepts. Finally, we conclude this survey with insights and discussions on future research directions.
Automated Graph Learning via Population Based Self-Tuning GCN
Jul 09, 2021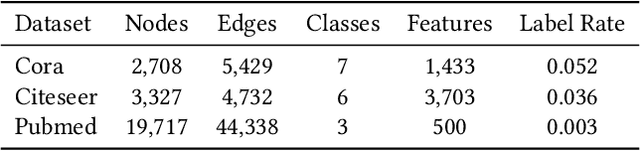
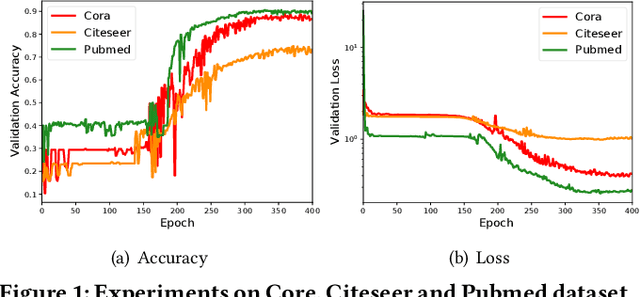
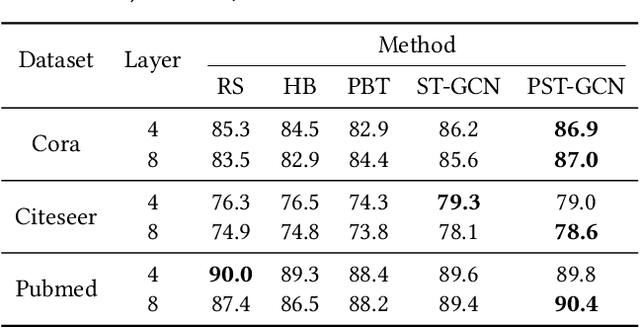
Owing to the remarkable capability of extracting effective graph embeddings, graph convolutional network (GCN) and its variants have been successfully applied to a broad range of tasks, such as node classification, link prediction, and graph classification. Traditional GCN models suffer from the issues of overfitting and oversmoothing, while some recent techniques like DropEdge could alleviate these issues and thus enable the development of deep GCN. However, training GCN models is non-trivial, as it is sensitive to the choice of hyperparameters such as dropout rate and learning weight decay, especially for deep GCN models. In this paper, we aim to automate the training of GCN models through hyperparameter optimization. To be specific, we propose a self-tuning GCN approach with an alternate training algorithm, and further extend our approach by incorporating the population based training scheme. Experimental results on three benchmark datasets demonstrate the effectiveness of our approaches on optimizing multi-layer GCN, compared with several representative baselines.
Co-embedding of Nodes and Edges with Graph Neural Networks
Oct 25, 2020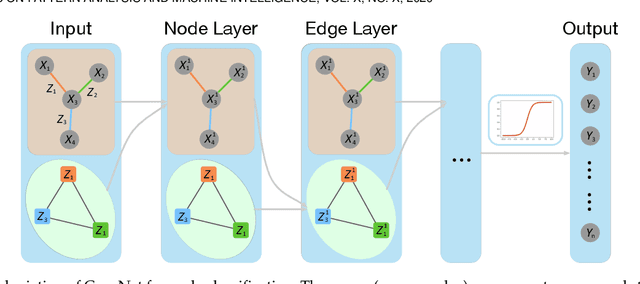
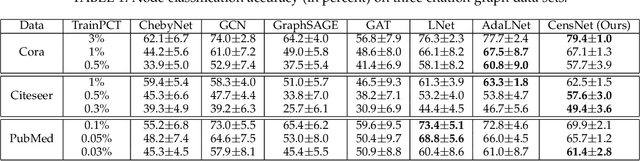
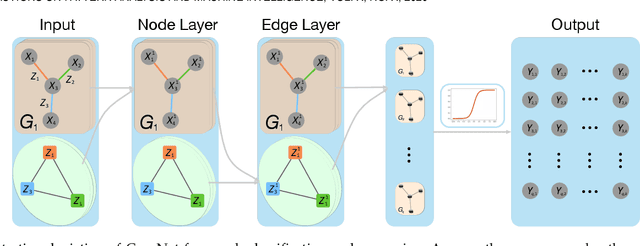
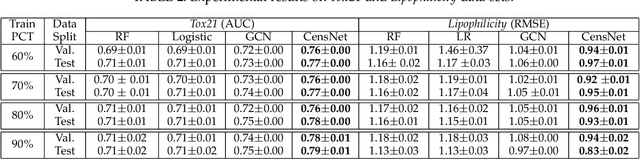
Graph, as an important data representation, is ubiquitous in many real world applications ranging from social network analysis to biology. How to correctly and effectively learn and extract information from graph is essential for a large number of machine learning tasks. Graph embedding is a way to transform and encode the data structure in high dimensional and non-Euclidean feature space to a low dimensional and structural space, which is easily exploited by other machine learning algorithms. We have witnessed a huge surge of such embedding methods, from statistical approaches to recent deep learning methods such as the graph convolutional networks (GCN). Deep learning approaches usually outperform the traditional methods in most graph learning benchmarks by building an end-to-end learning framework to optimize the loss function directly. However, most of the existing GCN methods can only perform convolution operations with node features, while ignoring the handy information in edge features, such as relations in knowledge graphs. To address this problem, we present CensNet, Convolution with Edge-Node Switching graph neural network, for learning tasks in graph-structured data with both node and edge features. CensNet is a general graph embedding framework, which embeds both nodes and edges to a latent feature space. By using line graph of the original undirected graph, the role of nodes and edges are switched, and two novel graph convolution operations are proposed for feature propagation. Experimental results on real-world academic citation networks and quantum chemistry graphs show that our approach achieves or matches the state-of-the-art performance in four graph learning tasks, including semi-supervised node classification, multi-task graph classification, graph regression, and link prediction.
Disentangling Features in 3D Face Shapes for Joint Face Reconstruction and Recognition
Mar 30, 2018
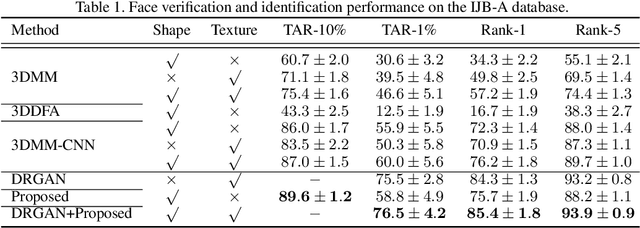


This paper proposes an encoder-decoder network to disentangle shape features during 3D face reconstruction from single 2D images, such that the tasks of reconstructing accurate 3D face shapes and learning discriminative shape features for face recognition can be accomplished simultaneously. Unlike existing 3D face reconstruction methods, our proposed method directly regresses dense 3D face shapes from single 2D images, and tackles identity and residual (i.e., non-identity) components in 3D face shapes explicitly and separately based on a composite 3D face shape model with latent representations. We devise a training process for the proposed network with a joint loss measuring both face identification error and 3D face shape reconstruction error. To construct training data we develop a method for fitting 3D morphable model (3DMM) to multiple 2D images of a subject. Comprehensive experiments have been done on MICC, BU3DFE, LFW and YTF databases. The results show that our method expands the capacity of 3DMM for capturing discriminative shape features and facial detail, and thus outperforms existing methods both in 3D face reconstruction accuracy and in face recognition accuracy.