 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSPAT: AutoML based Model Selection and Parameter Tuning for Time Series Anomaly Detection
May 24, 2022
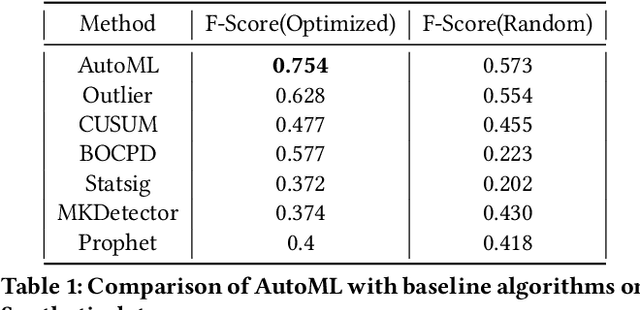
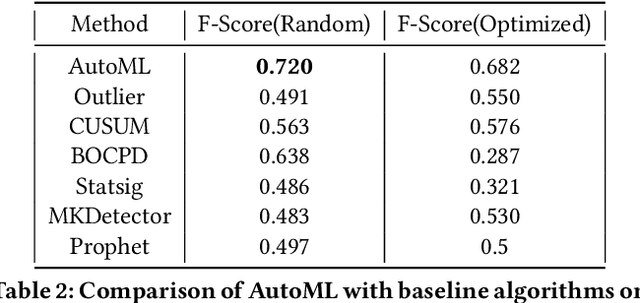
Organizations leverage anomaly and changepoint detection algorithms to detect changes in user behavior or service availability and performance. Many off-the-shelf detection algorithms, though effective, cannot readily be used in large organizations where thousands of users monitor millions of use cases and metrics with varied time series characteristics and anomaly patterns. The selection of algorithm and parameters needs to be precise for each use case: manual tuning does not scale, and automated tuning requires ground truth, which is rarely available. In this paper, we explore MOSPAT, an end-to-end automated machine learning based approach for model and parameter selection, combined with a generative model to produce labeled data. Our scalable end-to-end system allows individual users in large organizations to tailor time-series monitoring to their specific use case and data characteristics, without expert knowledge of anomaly detection algorithms or laborious manual labeling. Our extensive experiments on real and synthetic data demonstrate that this method consistently outperforms using any single algorithm.
Self-supervised learning for fast and scalable time series hyper-parameter tuning
Feb 10, 2021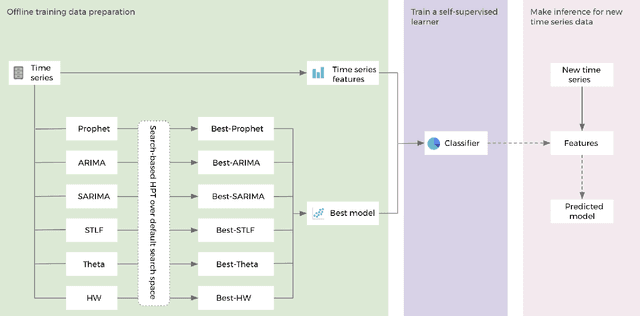

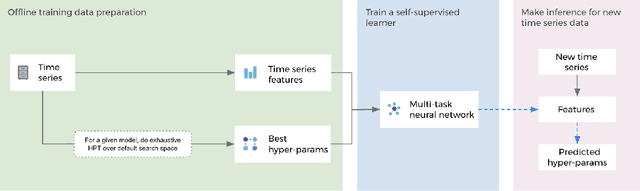
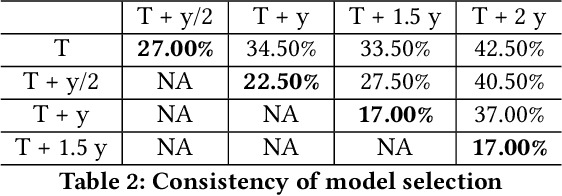
Hyper-parameters of time series models play an important role in time series analysis. Slight differences in hyper-parameters might lead to very different forecast results for a given model, and therefore, selecting good hyper-parameter values is indispensable. Most of the existing generic hyper-parameter tuning methods, such as Grid Search, Random Search, Bayesian Optimal Search, are based on one key component - search, and thus they are computationally expensive and cannot be applied to fast and scalable time-series hyper-parameter tuning (HPT). We propose a self-supervised learning framework for HPT (SSL-HPT), which uses time series features as inputs and produces optimal hyper-parameters. SSL-HPT algorithm is 6-20x faster at getting hyper-parameters compared to other search based algorithms while producing comparable accurate forecasting results in various applications.
Co-embedding of Nodes and Edges with Graph Neural Networks
Oct 25, 2020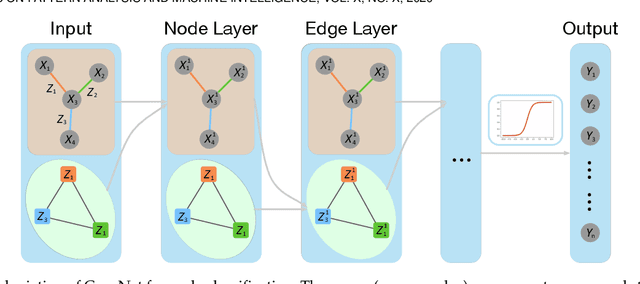
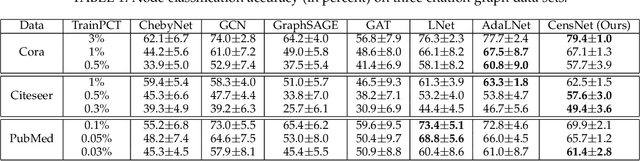
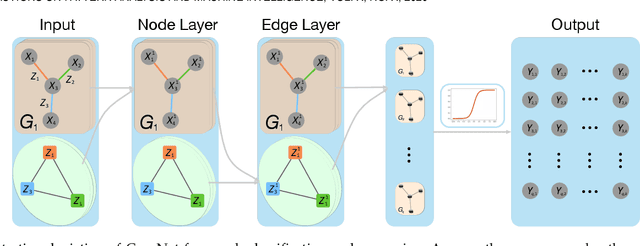
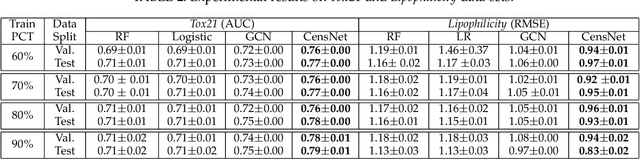
Graph, as an important data representation, is ubiquitous in many real world applications ranging from social network analysis to biology. How to correctly and effectively learn and extract information from graph is essential for a large number of machine learning tasks. Graph embedding is a way to transform and encode the data structure in high dimensional and non-Euclidean feature space to a low dimensional and structural space, which is easily exploited by other machine learning algorithms. We have witnessed a huge surge of such embedding methods, from statistical approaches to recent deep learning methods such as the graph convolutional networks (GCN). Deep learning approaches usually outperform the traditional methods in most graph learning benchmarks by building an end-to-end learning framework to optimize the loss function directly. However, most of the existing GCN methods can only perform convolution operations with node features, while ignoring the handy information in edge features, such as relations in knowledge graphs. To address this problem, we present CensNet, Convolution with Edge-Node Switching graph neural network, for learning tasks in graph-structured data with both node and edge features. CensNet is a general graph embedding framework, which embeds both nodes and edges to a latent feature space. By using line graph of the original undirected graph, the role of nodes and edges are switched, and two novel graph convolution operations are proposed for feature propagation. Experimental results on real-world academic citation networks and quantum chemistry graphs show that our approach achieves or matches the state-of-the-art performance in four graph learning tasks, including semi-supervised node classification, multi-task graph classification, graph regression, and link prediction.