 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Self-supervised learning for fast and scalable time series hyper-parameter tuning
Feb 10, 2021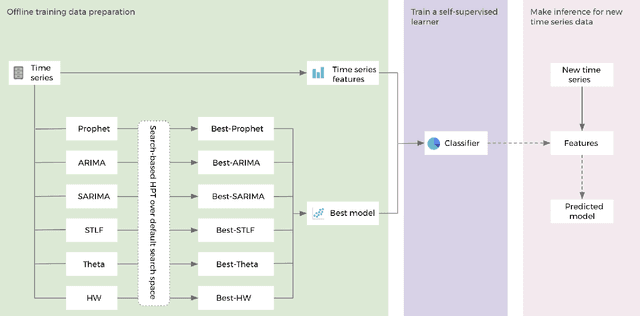

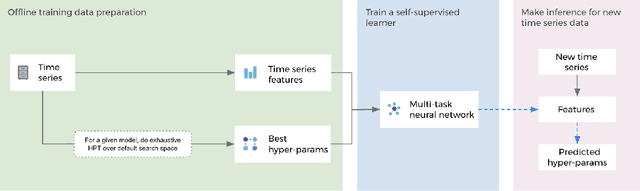
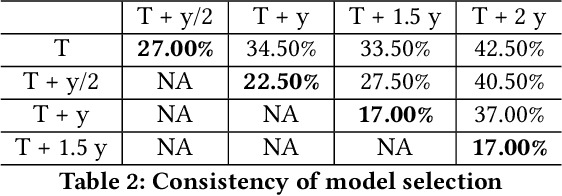
Hyper-parameters of time series models play an important role in time series analysis. Slight differences in hyper-parameters might lead to very different forecast results for a given model, and therefore, selecting good hyper-parameter values is indispensable. Most of the existing generic hyper-parameter tuning methods, such as Grid Search, Random Search, Bayesian Optimal Search, are based on one key component - search, and thus they are computationally expensive and cannot be applied to fast and scalable time-series hyper-parameter tuning (HPT). We propose a self-supervised learning framework for HPT (SSL-HPT), which uses time series features as inputs and produces optimal hyper-parameters. SSL-HPT algorithm is 6-20x faster at getting hyper-parameters compared to other search based algorithms while producing comparable accurate forecasting results in various applications.
Fast Dimensional Analysis for Root Cause Investigation in Large-Scale Service Environment
Nov 01, 2019
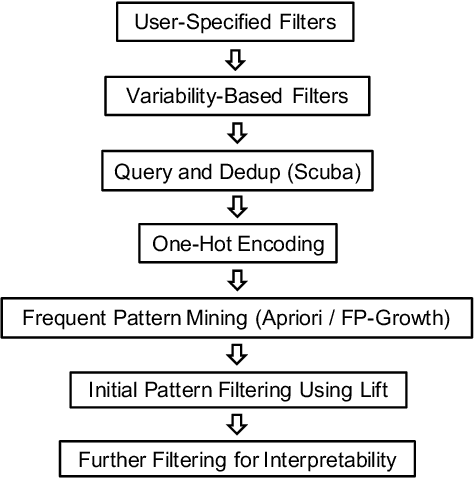
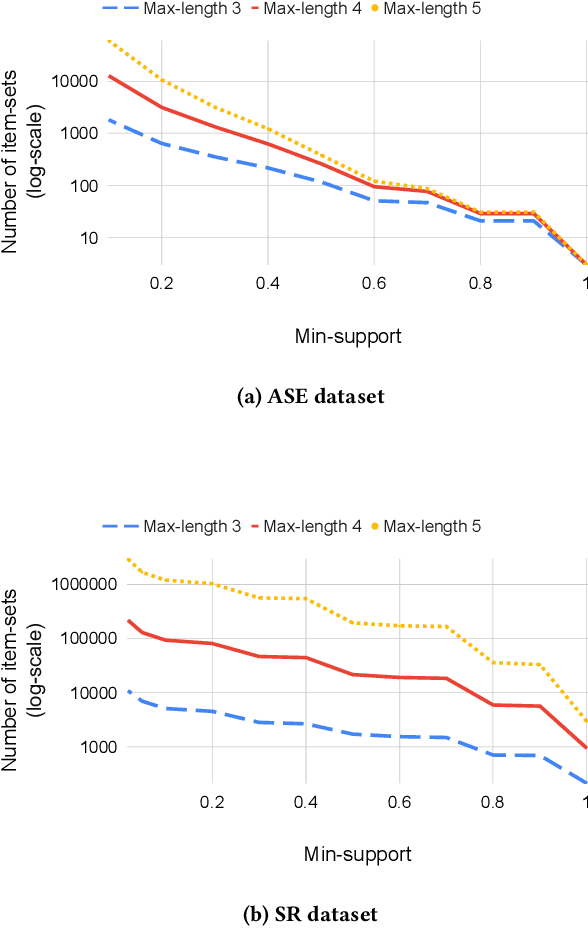
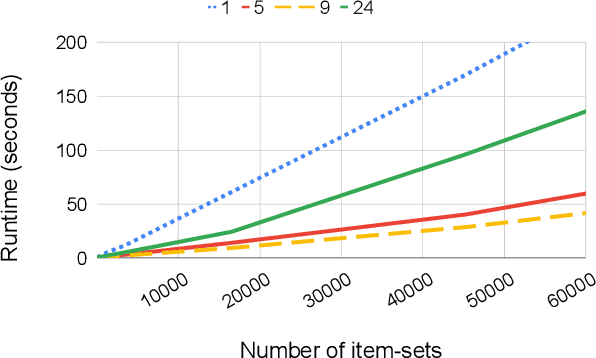
Root cause analysis in a large-scale production environment is challenging due to the complexity of services running across global data centers. Due to the distributed nature of a large-scale system, the various hardware, software, and tooling logs are often maintained separately, making it difficult to review the logs jointly for detecting issues. Another challenge in reviewing the logs for identifying issues is the scale - there could easily be millions of entities, each with hundreds of features. In this paper we present a fast dimensional analysis framework that automates the root cause analysis on structured logs with improved scalability. We first explore item-sets, i.e. a group of feature values, that could identify groups of samples with sufficient support for the target failures using the Apriori algorithm and a subsequent improvement, FP-Growth. These algorithms were designed for frequent item-set mining and association rule learning over transactional databases. After applying them on structured logs, we select the item-sets that are most unique to the target failures based on lift. With the use of a large-scale real-time database, we propose pre- and post-processing techniques and parallelism to further speed up the analysis. We have successfully rolled out this approach for root cause investigation purposes in a large-scale infrastructure. We also present the setup and results from multiple production use-cases in this paper.