 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVF (Parameter Vulnerability Factor): A Quantitative Metric Measuring AI Vulnerability and Resilience Against Parameter Corruptions
May 02, 2024



Reliability of AI systems is a fundamental concern for the successful deployment and widespread adoption of AI technologies. Unfortunately, the escalating complexity and heterogeneity of AI hardware systems make them inevitably and increasingly susceptible to hardware faults (e.g., bit flips) that can potentially corrupt model parameters. Given this challenge, this paper aims to answer a critical question: How likely is a parameter corruption to result in an incorrect model output? To systematically answer this question, we propose a novel quantitative metric, Parameter Vulnerability Factor (PVF), inspired by architectural vulnerability factor (AVF) in computer architecture community, aiming to standardize the quantification of AI model resilience/vulnerability against parameter corruptions. We define a model parameter's PVF as the probability that a corruption in that particular model parameter will result in an incorrect output. Similar to AVF, this statistical concept can be derived from statistically extensive and meaningful fault injection (FI) experiments. In this paper, we present several use cases on applying PVF to three types of tasks/models during inference -- recommendation (DLRM), vision classification (CNN), and text classification (BERT). PVF can provide pivotal insights to AI hardware designers in balancing the tradeoff between fault protection and performance/efficiency such as mapping vulnerable AI parameter components to well-protected hardware modules. PVF metric is applicable to any AI model and has a potential to help unify and standardize AI vulnerability/resilience evaluation practice.
Evaluating and Enhancing Robustness of Deep Recommendation Systems Against Hardware Errors
Jul 17, 2023



Deep recommendation systems (DRS) heavily depend on specialized HPC hardware and accelerators to optimize energy, efficiency, and recommendation quality. Despite the growing number of hardware errors observed in large-scale fleet systems where DRS are deployed, the robustness of DRS has been largely overlooked. This paper presents the first systematic study of DRS robustness against hardware errors. We develop Terrorch, a user-friendly, efficient and flexible error injection framework on top of the widely-used PyTorch. We evaluate a wide range of models and datasets and observe that the DRS robustness against hardware errors is influenced by various factors from model parameters to input characteristics. We also explore 3 error mitigation methods including algorithm based fault tolerance (ABFT), activation clipping and selective bit protection (SBP). We find that applying activation clipping can recover up to 30% of the degraded AUC-ROC score, making it a promising mitigation method.
Assessing and Analyzing the Resilience of Graph Neural Networks Against Hardware Faults
Dec 07, 2022



Graph neural networks (GNNs) have recently emerged as a promising learning paradigm in learning graph-structured data and have demonstrated wide success across various domains such as recommendation systems, social networks, and electronic design automation (EDA). Like other deep learning (DL) methods, GNNs are being deployed in sophisticated modern hardware systems, as well as dedicated accelerators. However, despite the popularity of GNNs and the recent efforts of bringing GNNs to hardware, the fault tolerance and resilience of GNNs has generally been overlooked. Inspired by the inherent algorithmic resilience of DL methods, this paper conducts, for the first time, a large-scale and empirical study of GNN resilience, aiming to understand the relationship between hardware faults and GNN accuracy. By developing a customized fault injection tool on top of PyTorch, we perform extensive fault injection experiments to various GNN models and application datasets. We observe that the error resilience of GNN models varies by orders of magnitude with respect to different models and application datasets. Further, we explore a low-cost error mitigation mechanism for GNN to enhance its resilience. This GNN resilience study aims to open up new directions and opportunities for future GNN accelerator design and architectural optimization.
Fast Dimensional Analysis for Root Cause Investigation in Large-Scale Service Environment
Nov 01, 2019
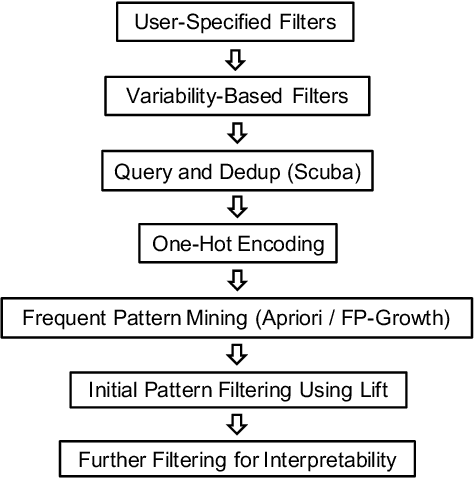
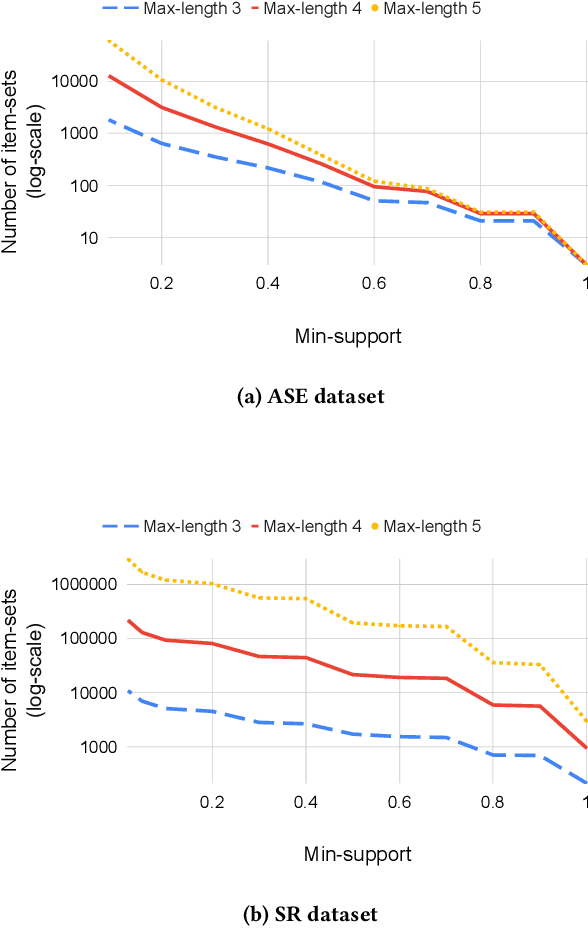
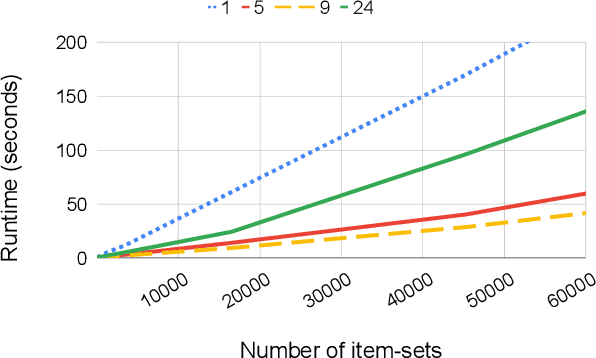
Root cause analysis in a large-scale production environment is challenging due to the complexity of services running across global data centers. Due to the distributed nature of a large-scale system, the various hardware, software, and tooling logs are often maintained separately, making it difficult to review the logs jointly for detecting issues. Another challenge in reviewing the logs for identifying issues is the scale - there could easily be millions of entities, each with hundreds of features. In this paper we present a fast dimensional analysis framework that automates the root cause analysis on structured logs with improved scalability. We first explore item-sets, i.e. a group of feature values, that could identify groups of samples with sufficient support for the target failures using the Apriori algorithm and a subsequent improvement, FP-Growth. These algorithms were designed for frequent item-set mining and association rule learning over transactional databases. After applying them on structured logs, we select the item-sets that are most unique to the target failures based on lift. With the use of a large-scale real-time database, we propose pre- and post-processing techniques and parallelism to further speed up the analysis. We have successfully rolled out this approach for root cause investigation purposes in a large-scale infrastructure. We also present the setup and results from multiple production use-cases in this paper.