 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePVF (Parameter Vulnerability Factor): A Quantitative Metric Measuring AI Vulnerability and Resilience Against Parameter Corruptions
May 02, 2024



Reliability of AI systems is a fundamental concern for the successful deployment and widespread adoption of AI technologies. Unfortunately, the escalating complexity and heterogeneity of AI hardware systems make them inevitably and increasingly susceptible to hardware faults (e.g., bit flips) that can potentially corrupt model parameters. Given this challenge, this paper aims to answer a critical question: How likely is a parameter corruption to result in an incorrect model output? To systematically answer this question, we propose a novel quantitative metric, Parameter Vulnerability Factor (PVF), inspired by architectural vulnerability factor (AVF) in computer architecture community, aiming to standardize the quantification of AI model resilience/vulnerability against parameter corruptions. We define a model parameter's PVF as the probability that a corruption in that particular model parameter will result in an incorrect output. Similar to AVF, this statistical concept can be derived from statistically extensive and meaningful fault injection (FI) experiments. In this paper, we present several use cases on applying PVF to three types of tasks/models during inference -- recommendation (DLRM), vision classification (CNN), and text classification (BERT). PVF can provide pivotal insights to AI hardware designers in balancing the tradeoff between fault protection and performance/efficiency such as mapping vulnerable AI parameter components to well-protected hardware modules. PVF metric is applicable to any AI model and has a potential to help unify and standardize AI vulnerability/resilience evaluation practice.
Approximate Computing Survey, Part II: Application-Specific & Architectural Approximation Techniques and Applications
Jul 20, 2023
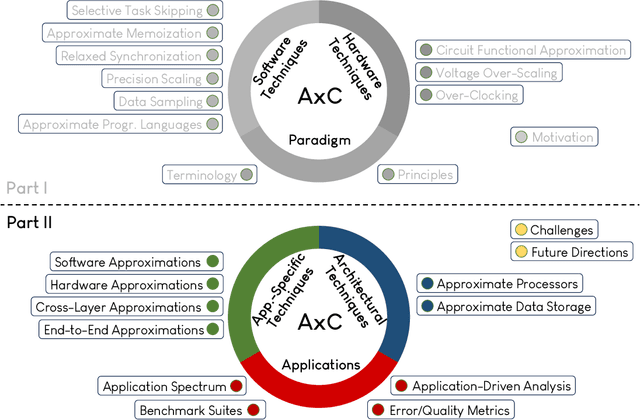
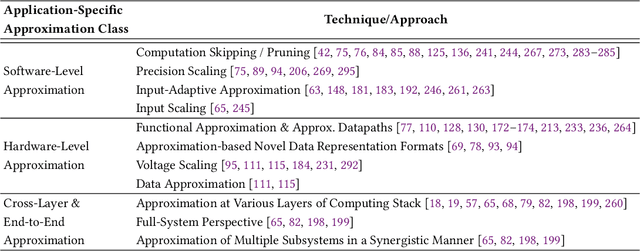
The challenging deployment of compute-intensive applications from domains such Artificial Intelligence (AI) and Digital Signal Processing (DSP), forces the community of computing systems to explore new design approaches. Approximate Computing appears as an emerging solution, allowing to tune the quality of results in the design of a system in order to improve the energy efficiency and/or performance. This radical paradigm shift has attracted interest from both academia and industry, resulting in significant research on approximation techniques and methodologies at different design layers (from system down to integrated circuits). Motivated by the wide appeal of Approximate Computing over the last 10 years, we conduct a two-part survey to cover key aspects (e.g., terminology and applications) and review the state-of-the art approximation techniques from all layers of the traditional computing stack. In Part II of our survey, we classify and present the technical details of application-specific and architectural approximation techniques, which both target the design of resource-efficient processors/accelerators & systems. Moreover, we present a detailed analysis of the application spectrum of Approximate Computing and discuss open challenges and future directions.
Evaluating and Enhancing Robustness of Deep Recommendation Systems Against Hardware Errors
Jul 17, 2023



Deep recommendation systems (DRS) heavily depend on specialized HPC hardware and accelerators to optimize energy, efficiency, and recommendation quality. Despite the growing number of hardware errors observed in large-scale fleet systems where DRS are deployed, the robustness of DRS has been largely overlooked. This paper presents the first systematic study of DRS robustness against hardware errors. We develop Terrorch, a user-friendly, efficient and flexible error injection framework on top of the widely-used PyTorch. We evaluate a wide range of models and datasets and observe that the DRS robustness against hardware errors is influenced by various factors from model parameters to input characteristics. We also explore 3 error mitigation methods including algorithm based fault tolerance (ABFT), activation clipping and selective bit protection (SBP). We find that applying activation clipping can recover up to 30% of the degraded AUC-ROC score, making it a promising mitigation method.
Assessing and Analyzing the Resilience of Graph Neural Networks Against Hardware Faults
Dec 07, 2022



Graph neural networks (GNNs) have recently emerged as a promising learning paradigm in learning graph-structured data and have demonstrated wide success across various domains such as recommendation systems, social networks, and electronic design automation (EDA). Like other deep learning (DL) methods, GNNs are being deployed in sophisticated modern hardware systems, as well as dedicated accelerators. However, despite the popularity of GNNs and the recent efforts of bringing GNNs to hardware, the fault tolerance and resilience of GNNs has generally been overlooked. Inspired by the inherent algorithmic resilience of DL methods, this paper conducts, for the first time, a large-scale and empirical study of GNN resilience, aiming to understand the relationship between hardware faults and GNN accuracy. By developing a customized fault injection tool on top of PyTorch, we perform extensive fault injection experiments to various GNN models and application datasets. We observe that the error resilience of GNN models varies by orders of magnitude with respect to different models and application datasets. Further, we explore a low-cost error mitigation mechanism for GNN to enhance its resilience. This GNN resilience study aims to open up new directions and opportunities for future GNN accelerator design and architectural optimization.
NasHD: Efficient ViT Architecture Performance Ranking using Hyperdimensional Computing
Sep 23, 2022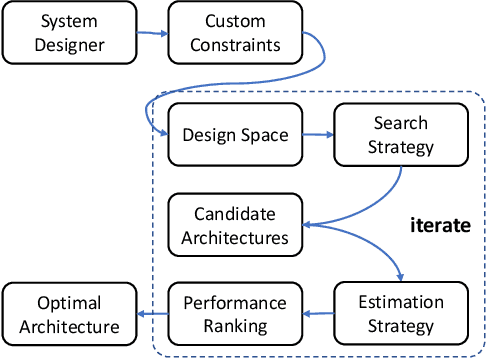
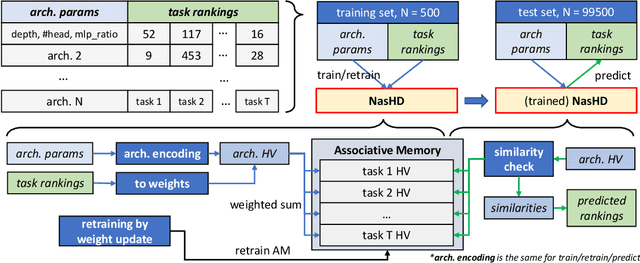
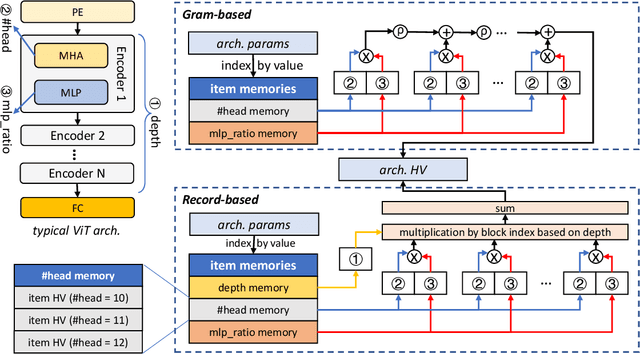
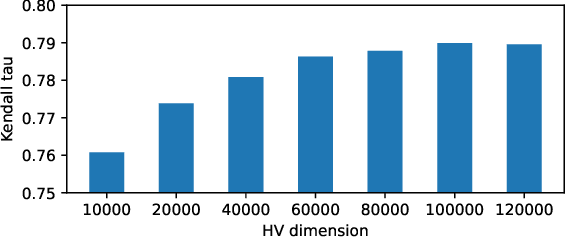
Neural Architecture Search (NAS) is an automated architecture engineering method for deep learning design automation, which serves as an alternative to the manual and error-prone process of model development, selection, evaluation and performance estimation. However, one major obstacle of NAS is the extremely demanding computation resource requirements and time-consuming iterations particularly when the dataset scales. In this paper, targeting at the emerging vision transformer (ViT), we present NasHD, a hyperdimensional computing based supervised learning model to rank the performance given the architectures and configurations. Different from other learning based methods, NasHD is faster thanks to the high parallel processing of HDC architecture. We also evaluated two HDC encoding schemes: Gram-based and Record-based of NasHD on their performance and efficiency. On the VIMER-UFO benchmark dataset of 8 applications from a diverse range of domains, NasHD Record can rank the performance of nearly 100K vision transformer models with about 1 minute while still achieving comparable results with sophisticated models.
Hyperdimensional Computing vs. Neural Networks: Comparing Architecture and Learning Process
Jul 24, 2022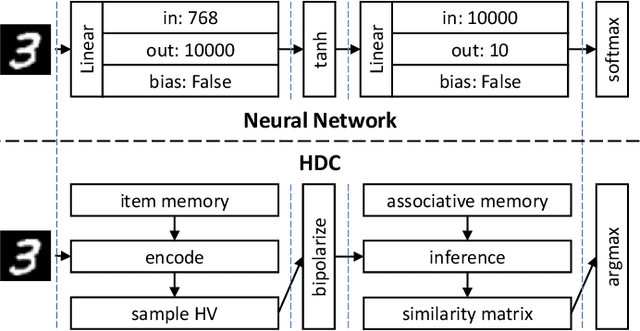
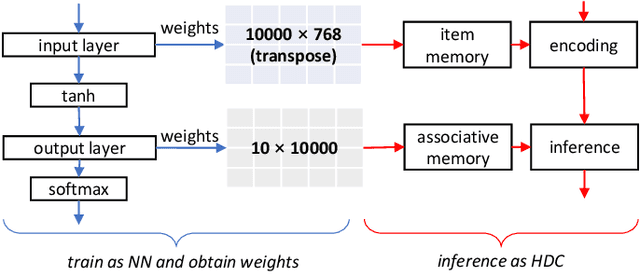
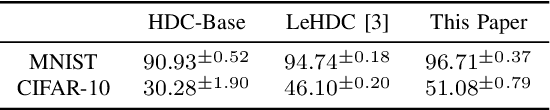
Hyperdimensional Computing (HDC) has obtained abundant attention as an emerging non von Neumann computing paradigm. Inspired by the way human brain functions, HDC leverages high dimensional patterns to perform learning tasks. Compared to neural networks, HDC has shown advantages such as energy efficiency and smaller model size, but sub-par learning capabilities in sophisticated applications. Recently, researchers have observed when combined with neural network components, HDC can achieve better performance than conventional HDC models. This motivates us to explore the deeper insights behind theoretical foundations of HDC, particularly the connection and differences with neural networks. In this paper, we make a comparative study between HDC and neural network to provide a different angle where HDC can be derived from an extremely compact neural network trained upfront. Experimental results show such neural network-derived HDC model can achieve up to 21% and 5% accuracy increase from conventional and learning-based HDC models respectively. This paper aims to provide more insights and shed lights on future directions for researches on this popular emerging learning scheme.
EnHDC: Ensemble Learning for Brain-Inspired Hyperdimensional Computing
Mar 25, 2022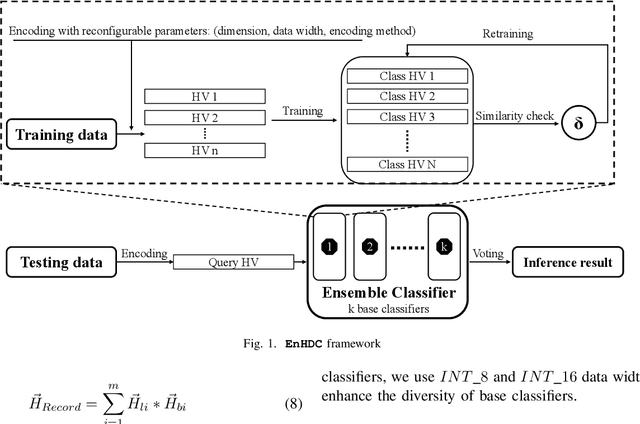
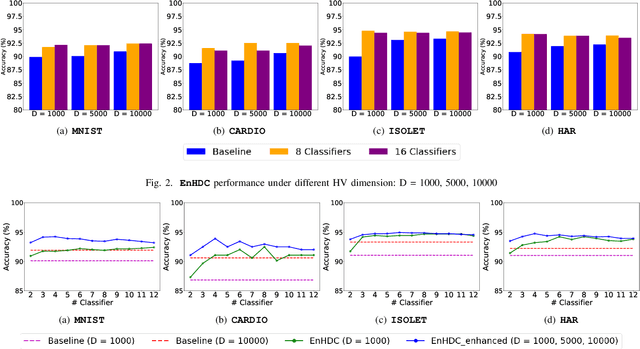
Ensemble learning is a classical learning method utilizing a group of weak learners to form a strong learner, which aims to increase the accuracy of the model. Recently, brain-inspired hyperdimensional computing (HDC) becomes an emerging computational paradigm that has achieved success in various domains such as human activity recognition, voice recognition, and bio-medical signal classification. HDC mimics the brain cognition and leverages high-dimensional vectors (e.g., 10000 dimensions) with fully distributed holographic representation and (pseudo-)randomness. This paper presents the first effort in exploring ensemble learning in the context of HDC and proposes the first ensemble HDC model referred to as EnHDC. EnHDC uses a majority voting-based mechanism to synergistically integrate the prediction outcomes of multiple base HDC classifiers. To enhance the diversity of base classifiers, we vary the encoding mechanisms, dimensions, and data width settings among base classifiers. By applying EnHDC on a wide range of applications, results show that the EnHDC can achieve on average 3.2\% accuracy improvement over a single HDC classifier. Further, we show that EnHDC with reduced dimensionality, e.g., 1000 dimensions, can achieve similar or even surpass the accuracy of baseline HDC with higher dimensionality, e.g., 10000 dimensions. This leads to a 20\% reduction of storage requirement of HDC model, which is key to enabling HDC on low-power computing platforms.
Automated Architecture Search for Brain-inspired Hyperdimensional Computing
Feb 11, 2022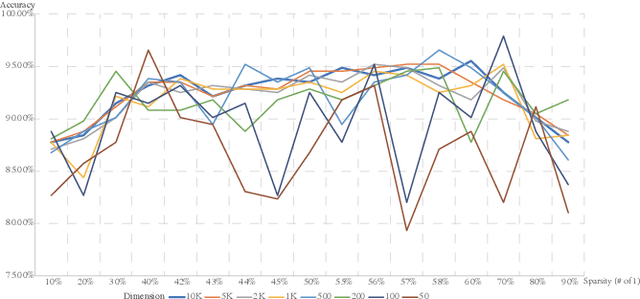
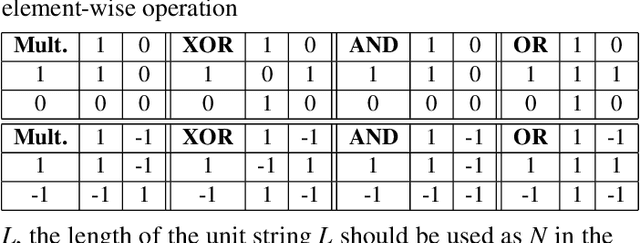
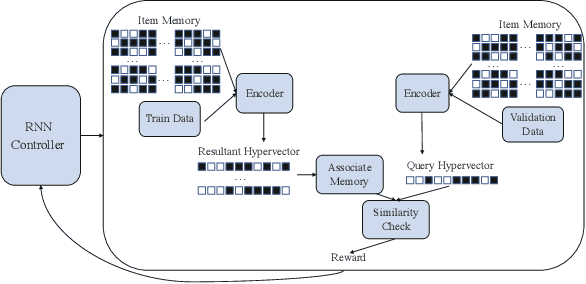
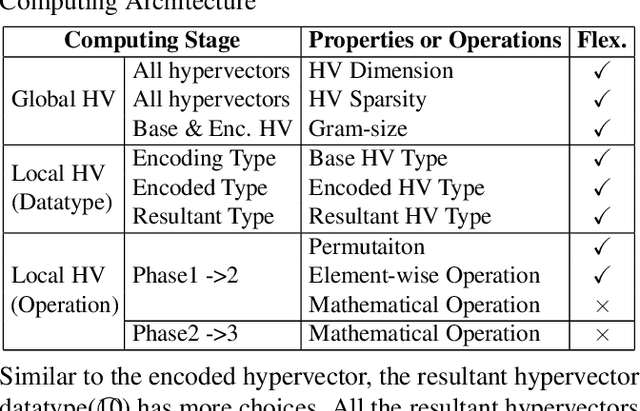
This paper represents the first effort to explore an automated architecture search for hyperdimensional computing (HDC), a type of brain-inspired neural network. Currently, HDC design is largely carried out in an application-specific ad-hoc manner, which significantly limits its application. Furthermore, the approach leads to inferior accuracy and efficiency, which suggests that HDC cannot perform competitively against deep neural networks. Herein, we present a thorough study to formulate an HDC architecture search space. On top of the search space, we apply reinforcement-learning to automatically explore the HDC architectures. The searched HDC architectures show competitive performance on case studies involving a drug discovery dataset and a language recognition task. On the Clintox dataset, which tries to learn features from developed drugs that passed/failed clinical trials for toxicity reasons, the searched HDC architecture obtains the state-of-the-art ROC-AUC scores, which are 0.80% higher than the manually designed HDC and 9.75% higher than conventional neural networks. Similar results are achieved on the language recognition task, with 1.27% higher performance than conventional methods.
HDCoin: A Proof-of-Useful-Work Based Blockchain for Hyperdimensional Computing
Feb 07, 2022



Various blockchain systems and schemes have been proposed since Bitcoin was first introduced by Nakamoto Satoshi as a distributed ledger. However, blockchains usually face criticisms, particularly on environmental concerns as their ``proof-of-work'' based mining process usually consumes a considerable amount of energy which hardly makes any useful contributions to the real world. Therefore, the concept of ``proof-of-useful-work'' (PoUW) is proposed to connect blockchain with practical application domain problems so the computation power consumed in the mining process can be spent on useful activities, such as solving optimization problems or training machine learning models. This paper introduces HDCoin, a blockchain-based framework for an emerging machine learning scheme: the brain-inspired hyperdimensional computing (HDC). We formulate the model development of HDC as a problem that can be used in blockchain mining. Specifically, we define the PoUW under the HDC scenario and develop the entire mining process of HDCoin. During mining, miners are competing to obtain the highest test accuracy on a given dataset. The winner also has its model recorded in the blockchain and are available for the public as a trustworthy HDC model. In addition, we also quantitatively examine the performance of mining under different HDC configurations to illustrate the adaptive mining difficulty.
MoleHD: Automated Drug Discovery using Brain-Inspired Hyperdimensional Computing
Jun 05, 2021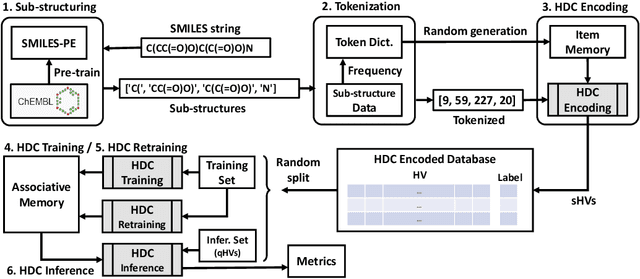
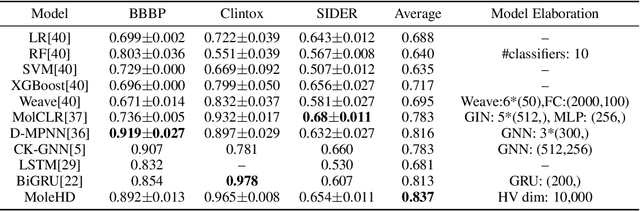
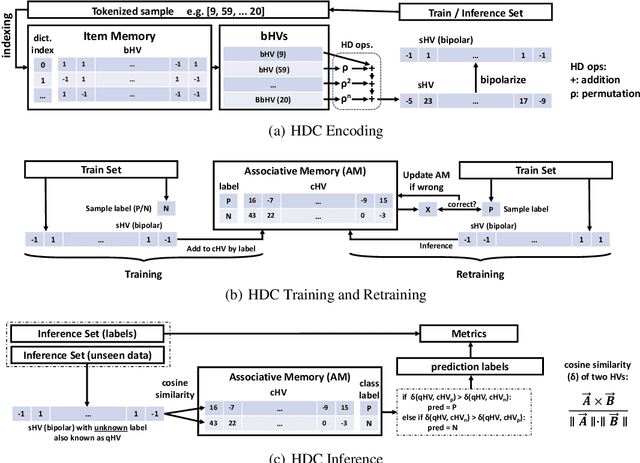
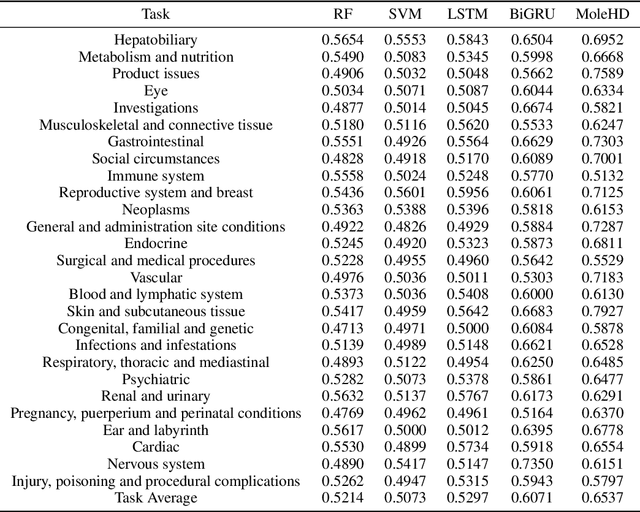
Modern drug discovery is often time-consuming, complex and cost-ineffective due to the large volume of molecular data and complicated molecular properties. Recently, machine learning algorithms have shown promising results in virtual screening of automated drug discovery by predicting molecular properties. While emerging learning methods such as graph neural networks and recurrent neural networks exhibit high accuracy, they are also notoriously computation-intensive and memory-intensive with operations such as feature embeddings or deep convolutions. In this paper, we propose a viable alternative to neural network classifiers. We present MoleHD, a method based on brain-inspired hyperdimensional computing (HDC) for molecular property prediction. We first transform the SMILES presentation of molecules into feature vectors by SMILE-PE tokenizers pretrained on the ChEMBL database. Then, we develop HDC encoders to project such features into high-dimensional vectors that are used for training and inference. We perform an extensive evaluation using 30 classification tasks from 3 widely-used molecule datasets and compare MoleHD with 10 baseline methods including 6 SOTA neural network classifiers. Results show that MoleHD is able to outperform all the baseline methods on average across 30 classification tasks with significantly reduced computing cost. To the best of our knowledge, we develop the first HDC-based method for drug discovery. The promising results presented in this paper can potentially lead to a novel path in drug discovery research.