 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Performance Bounds Prediction in Quantum Computing with Unstable Noise
Jul 22, 2025Quantum computing has significantly advanced in recent years, boasting devices with hundreds of quantum bits (qubits), hinting at its potential quantum advantage over classical computing. Yet, noise in quantum devices poses significant barriers to realizing this supremacy. Understanding noise's impact is crucial for reproducibility and application reuse; moreover, the next-generation quantum-centric supercomputing essentially requires efficient and accurate noise characterization to support system management (e.g., job scheduling), where ensuring correct functional performance (i.e., fidelity) of jobs on available quantum devices can even be higher-priority than traditional objectives. However, noise fluctuates over time, even on the same quantum device, which makes predicting the computational bounds for on-the-fly noise is vital. Noisy quantum simulation can offer insights but faces efficiency and scalability issues. In this work, we propose a data-driven workflow, namely QuBound, to predict computational performance bounds. It decomposes historical performance traces to isolate noise sources and devises a novel encoder to embed circuit and noise information processed by a Long Short-Term Memory (LSTM) network. For evaluation, we compare QuBound with a state-of-the-art learning-based predictor, which only generates a single performance value instead of a bound. Experimental results show that the result of the existing approach falls outside of performance bounds, while all predictions from our QuBound with the assistance of performance decomposition better fit the bounds. Moreover, QuBound can efficiently produce practical bounds for various circuits with over 106 speedup over simulation; in addition, the range from QuBound is over 10x narrower than the state-of-the-art analytical approach.
All-in-One Tuning and Structural Pruning for Domain-Specific LLMs
Dec 19, 2024



Existing pruning techniques for large language models (LLMs) targeting domain-specific applications typically follow a two-stage process: pruning the pretrained general-purpose LLMs and then fine-tuning the pruned LLMs on specific domains. However, the pruning decisions, derived from the pretrained weights, remain unchanged during fine-tuning, even if the weights have been updated. Therefore, such a combination of the pruning decisions and the finetuned weights may be suboptimal, leading to non-negligible performance degradation. To address these limitations, we propose ATP: All-in-One Tuning and Structural Pruning, a unified one-stage structural pruning and fine-tuning approach that dynamically identifies the current optimal substructure throughout the fine-tuning phase via a trainable pruning decision generator. Moreover, given the limited available data for domain-specific applications, Low-Rank Adaptation (LoRA) becomes a common technique to fine-tune the LLMs. In ATP, we introduce LoRA-aware forward and sparsity regularization to ensure that the substructures corresponding to the learned pruning decisions can be directly removed after the ATP process. ATP outperforms the state-of-the-art two-stage pruning methods on tasks in the legal and healthcare domains. More specifically, ATP recovers up to 88% and 91% performance of the dense model when pruning 40% parameters of LLaMA2-7B and LLaMA3-8B models, respectively.
A Self-guided Multimodal Approach to Enhancing Graph Representation Learning for Alzheimer's Diseases
Dec 09, 2024



Graph neural networks (GNNs) are powerful machine learning models designed to handle irregularly structured data. However, their generic design often proves inadequate for analyzing brain connectomes in Alzheimer's Disease (AD), highlighting the need to incorporate domain knowledge for optimal performance. Infusing AD-related knowledge into GNNs is a complicated task. Existing methods typically rely on collaboration between computer scientists and domain experts, which can be both time-intensive and resource-demanding. To address these limitations, this paper presents a novel self-guided, knowledge-infused multimodal GNN that autonomously incorporates domain knowledge into the model development process. Our approach conceptualizes domain knowledge as natural language and introduces a specialized multimodal GNN capable of leveraging this uncurated knowledge to guide the learning process of the GNN, such that it can improve the model performance and strengthen the interpretability of the predictions. To evaluate our framework, we curated a comprehensive dataset of recent peer-reviewed papers on AD and integrated it with multiple real-world AD datasets. Experimental results demonstrate the ability of our method to extract relevant domain knowledge, provide graph-based explanations for AD diagnosis, and improve the overall performance of the GNN. This approach provides a more scalable and efficient alternative to inject domain knowledge for AD compared with the manual design from the domain expert, advancing both prediction accuracy and interpretability in AD diagnosis.
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting
Sep 20, 2024



Pretrained large language models (LLMs) have revolutionized natural language processing (NLP) tasks such as summarization, question answering, and translation. However, LLMs pose significant security risks due to their tendency to memorize training data, leading to potential privacy breaches and copyright infringement. Accurate measurement of this memorization is essential to evaluate and mitigate these potential risks. However, previous attempts to characterize memorization are constrained by either using prefixes only or by prepending a constant soft prompt to the prefixes, which cannot react to changes in input. To address this challenge, we propose a novel method for estimating LLM memorization using dynamic, prefix-dependent soft prompts. Our approach involves training a transformer-based generator to produce soft prompts that adapt to changes in input, thereby enabling more accurate extraction of memorized data. Our method not only addresses the limitations of previous methods but also demonstrates superior performance in diverse experimental settings compared to state-of-the-art techniques. In particular, our method can achieve the maximum relative improvement of 112.75% and 32.26% over the vanilla baseline in terms of discoverable memorization rate for the text generation task and code generation task respectively.
Data-Algorithm-Architecture Co-Optimization for Fair Neural Networks on Skin Lesion Dataset
Jul 18, 2024As Artificial Intelligence (AI) increasingly integrates into our daily lives, fairness has emerged as a critical concern, particularly in medical AI, where datasets often reflect inherent biases due to social factors like the underrepresentation of marginalized communities and socioeconomic barriers to data collection. Traditional approaches to mitigating these biases have focused on data augmentation and the development of fairness-aware training algorithms. However, this paper argues that the architecture of neural networks, a core component of Machine Learning (ML), plays a crucial role in ensuring fairness. We demonstrate that addressing fairness effectively requires a holistic approach that simultaneously considers data, algorithms, and architecture. Utilizing Automated ML (AutoML) technology, specifically Neural Architecture Search (NAS), we introduce a novel framework, BiaslessNAS, designed to achieve fair outcomes in analyzing skin lesion datasets. BiaslessNAS incorporates fairness considerations at every stage of the NAS process, leading to the identification of neural networks that are not only more accurate but also significantly fairer. Our experiments show that BiaslessNAS achieves a 2.55% increase in accuracy and a 65.50% improvement in fairness compared to traditional NAS methods, underscoring the importance of integrating fairness into neural network architecture for better outcomes in medical AI applications.
APS-USCT: Ultrasound Computed Tomography on Sparse Data via AI-Physic Synergy
Jul 18, 2024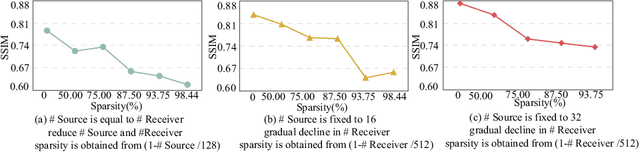
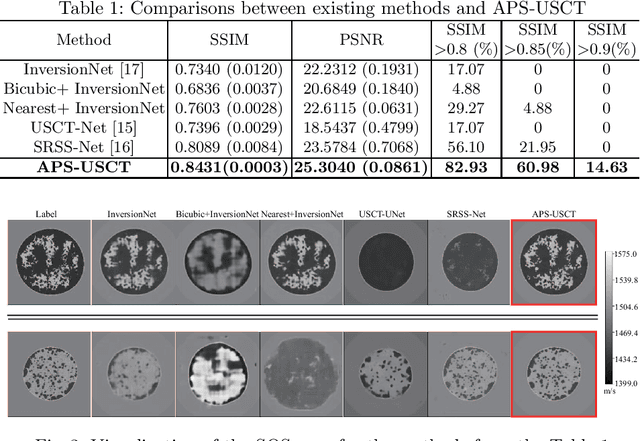
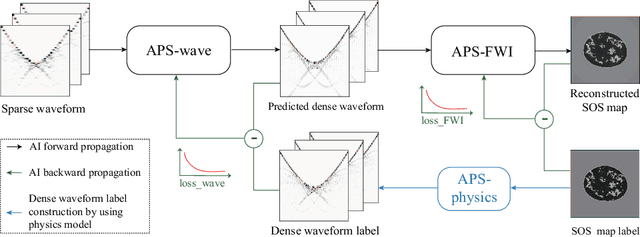

Ultrasound computed tomography (USCT) is a promising technique that achieves superior medical imaging reconstruction resolution by fully leveraging waveform information, outperforming conventional ultrasound methods. Despite its advantages, high-quality USCT reconstruction relies on extensive data acquisition by a large number of transducers, leading to increased costs, computational demands, extended patient scanning times, and manufacturing complexities. To mitigate these issues, we propose a new USCT method called APS-USCT, which facilitates imaging with sparse data, substantially reducing dependence on high-cost dense data acquisition. Our APS-USCT method consists of two primary components: APS-wave and APS-FWI. The APS-wave component, an encoder-decoder system, preprocesses the waveform data, converting sparse data into dense waveforms to augment sample density prior to reconstruction. The APS-FWI component, utilizing the InversionNet, directly reconstructs the speed of sound (SOS) from the ultrasound waveform data. We further improve the model's performance by incorporating Squeeze-and-Excitation (SE) Blocks and source encoding techniques. Testing our method on a breast cancer dataset yielded promising results. It demonstrated outstanding performance with an average Structural Similarity Index (SSIM) of 0.8431. Notably, over 82% of samples achieved an SSIM above 0.8, with nearly 61% exceeding 0.85, highlighting the significant potential of our approach in improving USCT image reconstruction by efficiently utilizing sparse data.
PristiQ: A Co-Design Framework for Preserving Data Security of Quantum Learning in the Cloud
Apr 20, 2024Benefiting from cloud computing, today's early-stage quantum computers can be remotely accessed via the cloud services, known as Quantum-as-a-Service (QaaS). However, it poses a high risk of data leakage in quantum machine learning (QML). To run a QML model with QaaS, users need to locally compile their quantum circuits including the subcircuit of data encoding first and then send the compiled circuit to the QaaS provider for execution. If the QaaS provider is untrustworthy, the subcircuit to encode the raw data can be easily stolen. Therefore, we propose a co-design framework for preserving the data security of QML with the QaaS paradigm, namely PristiQ. By introducing an encryption subcircuit with extra secure qubits associated with a user-defined security key, the security of data can be greatly enhanced. And an automatic search algorithm is proposed to optimize the model to maintain its performance on the encrypted quantum data. Experimental results on simulation and the actual IBM quantum computer both prove the ability of PristiQ to provide high security for the quantum data while maintaining the model performance in QML.
Edge-InversionNet: Enabling Efficient Inference of InversionNet on Edge Devices
Oct 18, 2023


Seismic full waveform inversion (FWI) is a widely used technique in geophysics for inferring subsurface structures from seismic data. And InversionNet is one of the most successful data-driven machine learning models that is applied to seismic FWI. However, the high computing costs to run InversionNet have made it challenging to be efficiently deployed on edge devices that are usually resource-constrained. Therefore, we propose to employ the structured pruning algorithm to get a lightweight version of InversionNet, which can make an efficient inference on edge devices. And we also made a prototype with Raspberry Pi to run the lightweight InversionNet. Experimental results show that the pruned InversionNet can achieve up to 98.2 % reduction in computing resources with moderate model performance degradation.
Muffin: A Framework Toward Multi-Dimension AI Fairness by Uniting Off-the-Shelf Models
Aug 26, 2023



Model fairness (a.k.a., bias) has become one of the most critical problems in a wide range of AI applications. An unfair model in autonomous driving may cause a traffic accident if corner cases (e.g., extreme weather) cannot be fairly regarded; or it will incur healthcare disparities if the AI model misdiagnoses a certain group of people (e.g., brown and black skin). In recent years, there have been emerging research works on addressing unfairness, and they mainly focus on a single unfair attribute, like skin tone; however, real-world data commonly have multiple attributes, among which unfairness can exist in more than one attribute, called 'multi-dimensional fairness'. In this paper, we first reveal a strong correlation between the different unfair attributes, i.e., optimizing fairness on one attribute will lead to the collapse of others. Then, we propose a novel Multi-Dimension Fairness framework, namely Muffin, which includes an automatic tool to unite off-the-shelf models to improve the fairness on multiple attributes simultaneously. Case studies on dermatology datasets with two unfair attributes show that the existing approach can achieve 21.05% fairness improvement on the first attribute while it makes the second attribute unfair by 1.85%. On the other hand, the proposed Muffin can unite multiple models to achieve simultaneously 26.32% and 20.37% fairness improvement on both attributes; meanwhile, it obtains 5.58% accuracy gain.
A Novel Spatial-Temporal Variational Quantum Circuit to Enable Deep Learning on NISQ Devices
Jul 19, 2023



Quantum computing presents a promising approach for machine learning with its capability for extremely parallel computation in high-dimension through superposition and entanglement. Despite its potential, existing quantum learning algorithms, such as Variational Quantum Circuits(VQCs), face challenges in handling more complex datasets, particularly those that are not linearly separable. What's more, it encounters the deployability issue, making the learning models suffer a drastic accuracy drop after deploying them to the actual quantum devices. To overcome these limitations, this paper proposes a novel spatial-temporal design, namely ST-VQC, to integrate non-linearity in quantum learning and improve the robustness of the learning model to noise. Specifically, ST-VQC can extract spatial features via a novel block-based encoding quantum sub-circuit coupled with a layer-wise computation quantum sub-circuit to enable temporal-wise deep learning. Additionally, a SWAP-Free physical circuit design is devised to improve robustness. These designs bring a number of hyperparameters. After a systematic analysis of the design space for each design component, an automated optimization framework is proposed to generate the ST-VQC quantum circuit. The proposed ST-VQC has been evaluated on two IBM quantum processors, ibm_cairo with 27 qubits and ibmq_lima with 7 qubits to assess its effectiveness. The results of the evaluation on the standard dataset for binary classification show that ST-VQC can achieve over 30% accuracy improvement compared with existing VQCs on actual quantum computers. Moreover, on a non-linear synthetic dataset, the ST-VQC outperforms a linear classifier by 27.9%, while the linear classifier using classical computing outperforms the existing VQC by 15.58%.