 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
ALTER: All-in-One Layer Pruning and Temporal Expert Routing for Efficient Diffusion Generation
May 27, 2025Diffusion models have demonstrated exceptional capabilities in generating high-fidelity images. However, their iterative denoising process results in significant computational overhead during inference, limiting their practical deployment in resource-constrained environments. Existing acceleration methods often adopt uniform strategies that fail to capture the temporal variations during diffusion generation, while the commonly adopted sequential pruning-then-fine-tuning strategy suffers from sub-optimality due to the misalignment between pruning decisions made on pretrained weights and the model's final parameters. To address these limitations, we introduce ALTER: All-in-One Layer Pruning and Temporal Expert Routing, a unified framework that transforms diffusion models into a mixture of efficient temporal experts. ALTER achieves a single-stage optimization that unifies layer pruning, expert routing, and model fine-tuning by employing a trainable hypernetwork, which dynamically generates layer pruning decisions and manages timestep routing to specialized, pruned expert sub-networks throughout the ongoing fine-tuning of the UNet. This unified co-optimization strategy enables significant efficiency gains while preserving high generative quality. Specifically, ALTER achieves same-level visual fidelity to the original 50-step Stable Diffusion v2.1 model while utilizing only 25.9% of its total MACs with just 20 inference steps and delivering a 3.64x speedup through 35% sparsity.
Towards deployment-centric multimodal AI beyond vision and language
Apr 04, 2025Multimodal artificial intelligence (AI) integrates diverse types of data via machine learning to improve understanding, prediction, and decision-making across disciplines such as healthcare, science, and engineering. However, most multimodal AI advances focus on models for vision and language data, while their deployability remains a key challenge. We advocate a deployment-centric workflow that incorporates deployment constraints early to reduce the likelihood of undeployable solutions, complementing data-centric and model-centric approaches. We also emphasise deeper integration across multiple levels of multimodality and multidisciplinary collaboration to significantly broaden the research scope beyond vision and language. To facilitate this approach, we identify common multimodal-AI-specific challenges shared across disciplines and examine three real-world use cases: pandemic response, self-driving car design, and climate change adaptation, drawing expertise from healthcare, social science, engineering, science, sustainability, and finance. By fostering multidisciplinary dialogue and open research practices, our community can accelerate deployment-centric development for broad societal impact.
HDCompression: Hybrid-Diffusion Image Compression for Ultra-Low Bitrates
Feb 11, 2025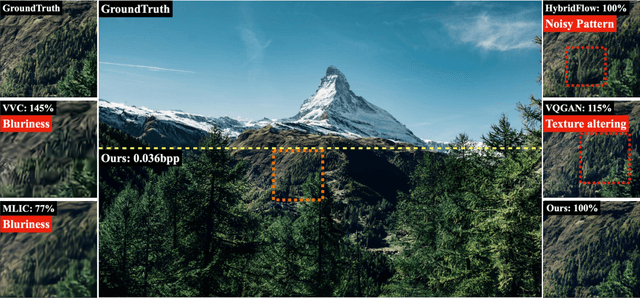
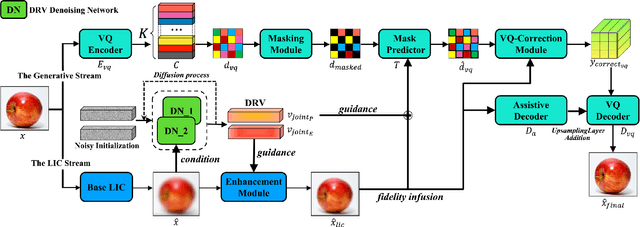
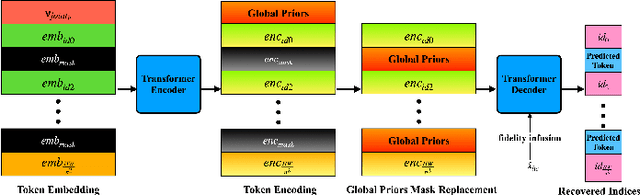
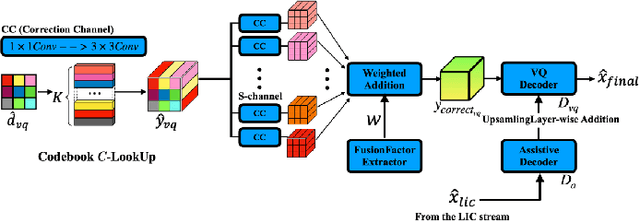
Image compression under ultra-low bitrates remains challenging for both conventional learned image compression (LIC) and generative vector-quantized (VQ) modeling. Conventional LIC suffers from severe artifacts due to heavy quantization, while generative VQ modeling gives poor fidelity due to the mismatch between learned generative priors and specific inputs. In this work, we propose Hybrid-Diffusion Image Compression (HDCompression), a dual-stream framework that utilizes both generative VQ-modeling and diffusion models, as well as conventional LIC, to achieve both high fidelity and high perceptual quality. Different from previous hybrid methods that directly use pre-trained LIC models to generate low-quality fidelity-preserving information from heavily quantized latent, we use diffusion models to extract high-quality complimentary fidelity information from the ground-truth input, which can enhance the system performance in several aspects: improving indices map prediction, enhancing the fidelity-preserving output of the LIC stream, and refining conditioned image reconstruction with VQ-latent correction. In addition, our diffusion model is based on a dense representative vector (DRV), which is lightweight with very simple sampling schedulers. Extensive experiments demonstrate that our HDCompression outperforms the previous conventional LIC, generative VQ-modeling, and hybrid frameworks in both quantitative metrics and qualitative visualization, providing balanced robust compression performance at ultra-low bitrates.
All-in-One Tuning and Structural Pruning for Domain-Specific LLMs
Dec 19, 2024



Existing pruning techniques for large language models (LLMs) targeting domain-specific applications typically follow a two-stage process: pruning the pretrained general-purpose LLMs and then fine-tuning the pruned LLMs on specific domains. However, the pruning decisions, derived from the pretrained weights, remain unchanged during fine-tuning, even if the weights have been updated. Therefore, such a combination of the pruning decisions and the finetuned weights may be suboptimal, leading to non-negligible performance degradation. To address these limitations, we propose ATP: All-in-One Tuning and Structural Pruning, a unified one-stage structural pruning and fine-tuning approach that dynamically identifies the current optimal substructure throughout the fine-tuning phase via a trainable pruning decision generator. Moreover, given the limited available data for domain-specific applications, Low-Rank Adaptation (LoRA) becomes a common technique to fine-tune the LLMs. In ATP, we introduce LoRA-aware forward and sparsity regularization to ensure that the substructures corresponding to the learned pruning decisions can be directly removed after the ATP process. ATP outperforms the state-of-the-art two-stage pruning methods on tasks in the legal and healthcare domains. More specifically, ATP recovers up to 88% and 91% performance of the dense model when pruning 40% parameters of LLaMA2-7B and LLaMA3-8B models, respectively.
Fully Open Source Moxin-7B Technical Report
Dec 08, 2024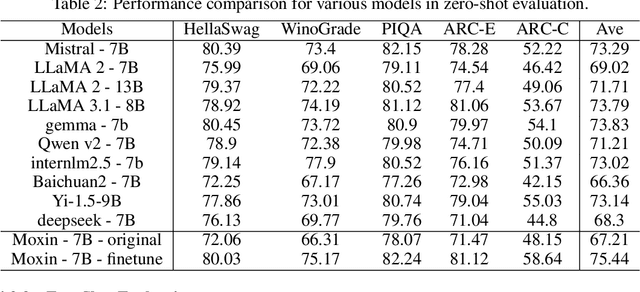
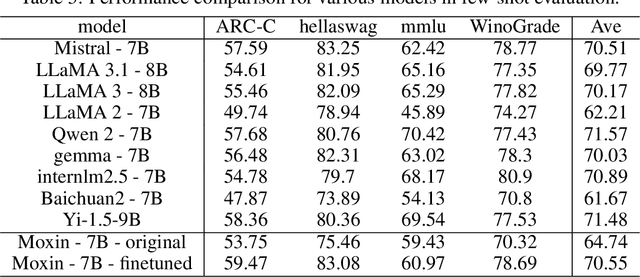


Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
Task Adaptive Feature Distribution Based Network for Few-shot Fine-grained Target Classification
Oct 13, 2024Metric-based few-shot fine-grained classification has shown promise due to its simplicity and efficiency. However, existing methods often overlook task-level special cases and struggle with accurate category description and irrelevant sample information. To tackle these, we propose TAFD-Net: a task adaptive feature distribution network. It features a task-adaptive component for embedding to capture task-level nuances, an asymmetric metric for calculating feature distribution similarities between query samples and support categories, and a contrastive measure strategy to boost performance. Extensive experiments have been conducted on three datasets and the experimental results show that our proposed algorithm outperforms recent incremental learning algorithms.
Digital Avatars: Framework Development and Their Evaluation
Aug 07, 2024


We present a novel prompting strategy for artificial intelligence driven digital avatars. To better quantify how our prompting strategy affects anthropomorphic features like humor, authenticity, and favorability we present Crowd Vote - an adaptation of Crowd Score that allows for judges to elect a large language model (LLM) candidate over competitors answering the same or similar prompts. To visualize the responses of our LLM, and the effectiveness of our prompting strategy we propose an end-to-end framework for creating high-fidelity artificial intelligence (AI) driven digital avatars. This pipeline effectively captures an individual's essence for interaction and our streaming algorithm delivers a high-quality digital avatar with real-time audio-video streaming from server to mobile device. Both our visualization tool, and our Crowd Vote metrics demonstrate our AI driven digital avatars have state-of-the-art humor, authenticity, and favorability outperforming all competitors and baselines. In the case of our Donald Trump and Joe Biden avatars, their authenticity and favorability are rated higher than even their real-world equivalents.
* This work was presented during the IJCAI 2024 conference proceedings for demonstrations
HybridFlow: Infusing Continuity into Masked Codebook for Extreme Low-Bitrate Image Compression
Apr 20, 2024

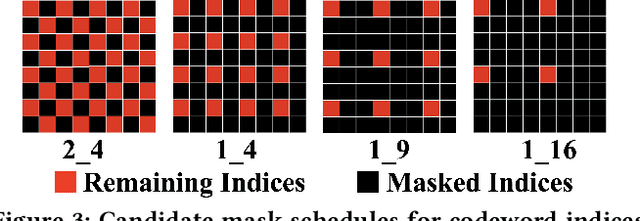

This paper investigates the challenging problem of learned image compression (LIC) with extreme low bitrates. Previous LIC methods based on transmitting quantized continuous features often yield blurry and noisy reconstruction due to the severe quantization loss. While previous LIC methods based on learned codebooks that discretize visual space usually give poor-fidelity reconstruction due to the insufficient representation power of limited codewords in capturing faithful details. We propose a novel dual-stream framework, HyrbidFlow, which combines the continuous-feature-based and codebook-based streams to achieve both high perceptual quality and high fidelity under extreme low bitrates. The codebook-based stream benefits from the high-quality learned codebook priors to provide high quality and clarity in reconstructed images. The continuous feature stream targets at maintaining fidelity details. To achieve the ultra low bitrate, a masked token-based transformer is further proposed, where we only transmit a masked portion of codeword indices and recover the missing indices through token generation guided by information from the continuous feature stream. We also develop a bridging correction network to merge the two streams in pixel decoding for final image reconstruction, where the continuous stream features rectify biases of the codebook-based pixel decoder to impose reconstructed fidelity details. Experimental results demonstrate superior performance across several datasets under extremely low bitrates, compared with existing single-stream codebook-based or continuous-feature-based LIC methods.