 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Multimodal Moxin Models with Moxin-VLM and Moxin-VLA
Dec 22, 2025Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Moxin 7B is introduced as a fully open-source LLM developed in accordance with the Model Openness Framework, which moves beyond the simple sharing of model weights to embrace complete transparency in training, datasets, and implementation detail, thus fostering a more inclusive and collaborative research environment that can sustain a healthy open-source ecosystem. To further equip Moxin with various capabilities in different tasks, we develop three variants based on Moxin, including Moxin-VLM, Moxin-VLA, and Moxin-Chinese, which target the vision-language, vision-language-action, and Chinese capabilities, respectively. Experiments show that our models achieve superior performance in various evaluations. We adopt open-source framework and open data for the training. We release our models, along with the available data and code to derive these models.
Perturbation-efficient Zeroth-order Optimization for Hardware-friendly On-device Training
Apr 28, 2025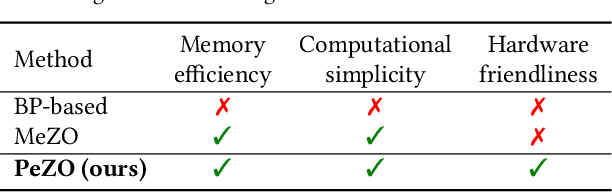
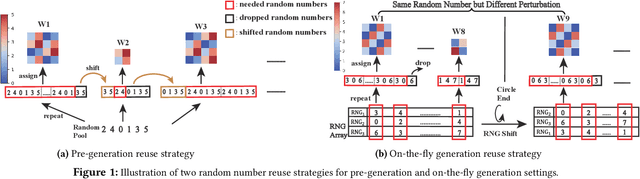
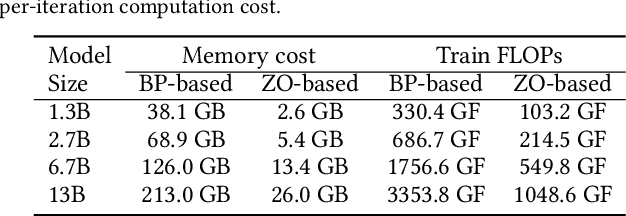
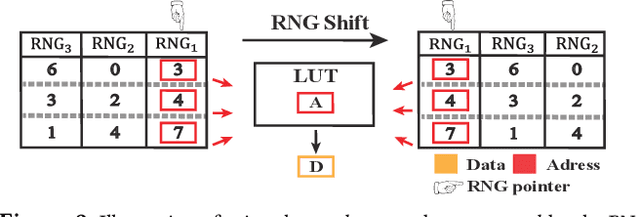
Zeroth-order (ZO) optimization is an emerging deep neural network (DNN) training paradigm that offers computational simplicity and memory savings. However, this seemingly promising approach faces a significant and long-ignored challenge. ZO requires generating a substantial number of Gaussian random numbers, which poses significant difficulties and even makes it infeasible for hardware platforms, such as FPGAs and ASICs. In this paper, we identify this critical issue, which arises from the mismatch between algorithm and hardware designers. To address this issue, we proposed PeZO, a perturbation-efficient ZO framework. Specifically, we design random number reuse strategies to significantly reduce the demand for random number generation and introduce a hardware-friendly adaptive scaling method to replace the costly Gaussian distribution with a uniform distribution. Our experiments show that PeZO reduces the required LUTs and FFs for random number generation by 48.6\% and 12.7\%, and saves at maximum 86\% power consumption, all without compromising training performance, making ZO optimization feasible for on-device training. To the best of our knowledge, we are the first to explore the potential of on-device ZO optimization, providing valuable insights for future research.
Fully Open Source Moxin-7B Technical Report
Dec 08, 2024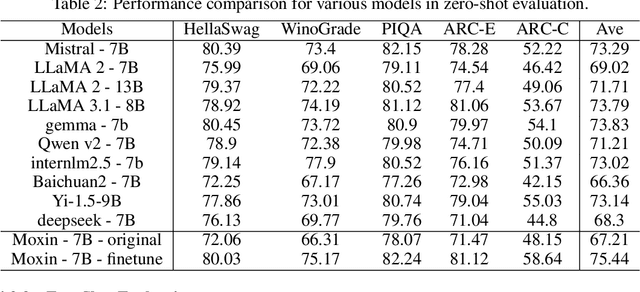
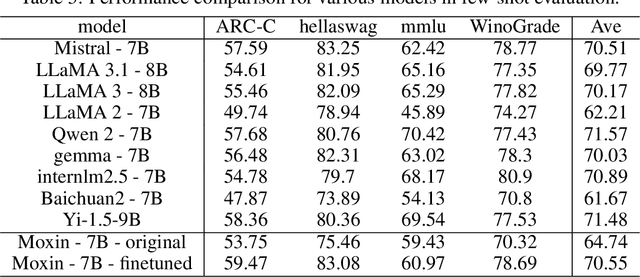


Recently, Large Language Models (LLMs) have undergone a significant transformation, marked by a rapid rise in both their popularity and capabilities. Leading this evolution are proprietary LLMs like GPT-4 and GPT-o1, which have captured widespread attention in the AI community due to their remarkable performance and versatility. Simultaneously, open-source LLMs, such as LLaMA and Mistral, have made great contributions to the ever-increasing popularity of LLMs due to the ease to customize and deploy the models across diverse applications. Although open-source LLMs present unprecedented opportunities for innovation and research, the commercialization of LLMs has raised concerns about transparency, reproducibility, and safety. Many open-source LLMs fail to meet fundamental transparency requirements by withholding essential components like training code and data, and some use restrictive licenses whilst claiming to be "open-source," which may hinder further innovations on LLMs. To mitigate this issue, we introduce Moxin 7B, a fully open-source LLM developed in accordance with the Model Openness Framework (MOF), a ranked classification system that evaluates AI models based on model completeness and openness, adhering to principles of open science, open source, open data, and open access. Our model achieves the highest MOF classification level of "open science" through the comprehensive release of pre-training code and configurations, training and fine-tuning datasets, and intermediate and final checkpoints. Experiments show that our model achieves superior performance in zero-shot evaluation compared with popular 7B models and performs competitively in few-shot evaluation.
Digital Avatars: Framework Development and Their Evaluation
Aug 07, 2024


We present a novel prompting strategy for artificial intelligence driven digital avatars. To better quantify how our prompting strategy affects anthropomorphic features like humor, authenticity, and favorability we present Crowd Vote - an adaptation of Crowd Score that allows for judges to elect a large language model (LLM) candidate over competitors answering the same or similar prompts. To visualize the responses of our LLM, and the effectiveness of our prompting strategy we propose an end-to-end framework for creating high-fidelity artificial intelligence (AI) driven digital avatars. This pipeline effectively captures an individual's essence for interaction and our streaming algorithm delivers a high-quality digital avatar with real-time audio-video streaming from server to mobile device. Both our visualization tool, and our Crowd Vote metrics demonstrate our AI driven digital avatars have state-of-the-art humor, authenticity, and favorability outperforming all competitors and baselines. In the case of our Donald Trump and Joe Biden avatars, their authenticity and favorability are rated higher than even their real-world equivalents.
* This work was presented during the IJCAI 2024 conference proceedings for demonstrations
ILMPQ : An Intra-Layer Multi-Precision Deep Neural Network Quantization framework for FPGA
Oct 30, 2021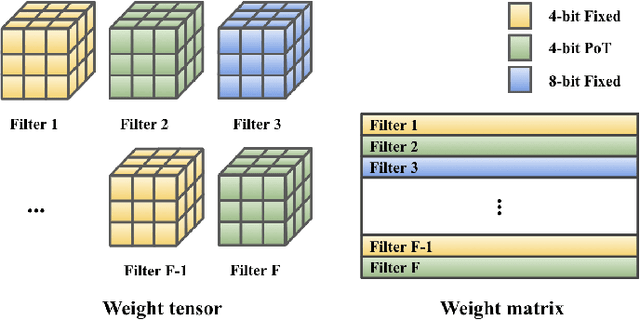
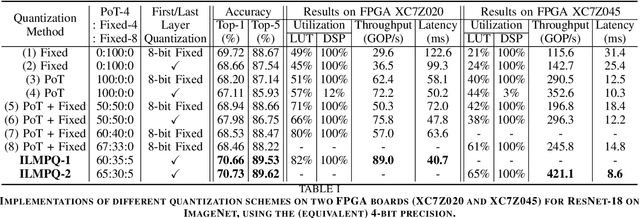
This work targets the commonly used FPGA (field-programmable gate array) devices as the hardware platform for DNN edge computing. We focus on DNN quantization as the main model compression technique. The novelty of this work is: We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach. Our proposed ILMPQ DNN quantization framework achieves 70.73 Top1 accuracy in ResNet-18 on the ImageNet dataset. We also validate the proposed MSP framework on two FPGA devices i.e., Xilinx XC7Z020 and XC7Z045. We achieve 3.65x speedup in end-to-end inference time on the ImageNet, compared with the fixed-point quantization method.
RMSMP: A Novel Deep Neural Network Quantization Framework with Row-wise Mixed Schemes and Multiple Precisions
Oct 30, 2021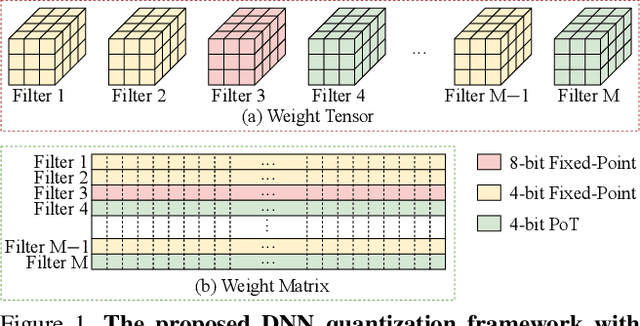



This work proposes a novel Deep Neural Network (DNN) quantization framework, namely RMSMP, with a Row-wise Mixed-Scheme and Multi-Precision approach. Specifically, this is the first effort to assign mixed quantization schemes and multiple precisions within layers -- among rows of the DNN weight matrix, for simplified operations in hardware inference, while preserving accuracy. Furthermore, this paper makes a different observation from the prior work that the quantization error does not necessarily exhibit the layer-wise sensitivity, and actually can be mitigated as long as a certain portion of the weights in every layer are in higher precisions. This observation enables layer-wise uniformality in the hardware implementation towards guaranteed inference acceleration, while still enjoying row-wise flexibility of mixed schemes and multiple precisions to boost accuracy. The candidates of schemes and precisions are derived practically and effectively with a highly hardware-informative strategy to reduce the problem search space. With the offline determined ratio of different quantization schemes and precisions for all the layers, the RMSMP quantization algorithm uses the Hessian and variance-based method to effectively assign schemes and precisions for each row. The proposed RMSMP is tested for the image classification and natural language processing (BERT) applications and achieves the best accuracy performance among state-of-the-arts under the same equivalent precisions. The RMSMP is implemented on FPGA devices, achieving 3.65x speedup in the end-to-end inference time for ResNet-18 on ImageNet, compared with the 4-bit Fixed-point baseline.
Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework
Dec 12, 2020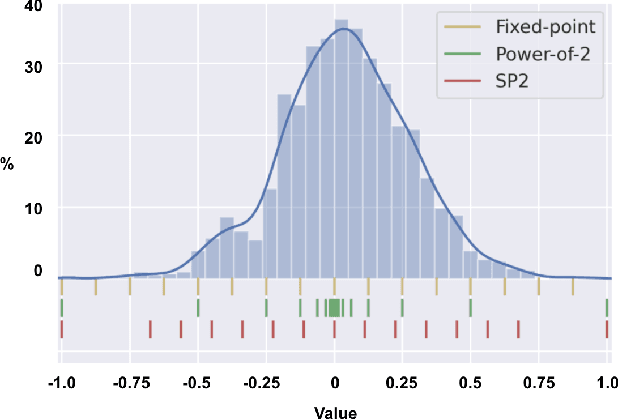
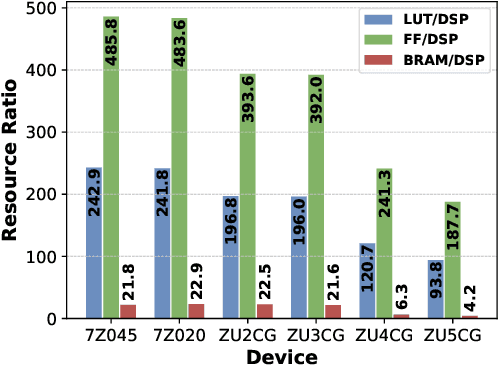
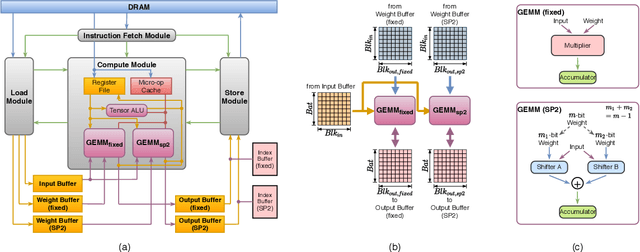
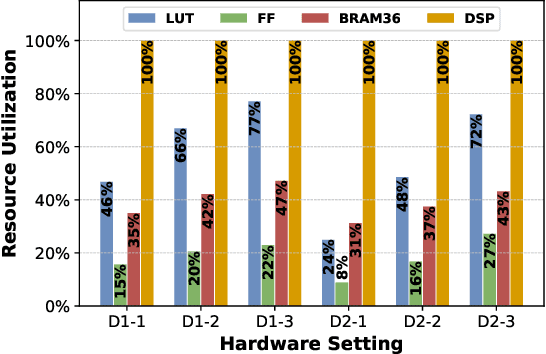
Deep Neural Networks (DNNs) have achieved extraordinary performance in various application domains. To support diverse DNN models, efficient implementations of DNN inference on edge-computing platforms, e.g., ASICs, FPGAs, and embedded systems, are extensively investigated. Due to the huge model size and computation amount, model compression is a critical step to deploy DNN models on edge devices. This paper focuses on weight quantization, a hardware-friendly model compression approach that is complementary to weight pruning. Unlike existing methods that use the same quantization scheme for all weights, we propose the first solution that applies different quantization schemes for different rows of the weight matrix. It is motivated by (1) the distribution of the weights in the different rows are not the same; and (2) the potential of achieving better utilization of heterogeneous FPGA hardware resources. To achieve that, we first propose a hardware-friendly quantization scheme named sum-of-power-of-2 (SP2) suitable for Gaussian-like weight distribution, in which the multiplication arithmetic can be replaced with logic shifter and adder, thereby enabling highly efficient implementations with the FPGA LUT resources. In contrast, the existing fixed-point quantization is suitable for Uniform-like weight distribution and can be implemented efficiently by DSP. Then to fully explore the resources, we propose an FPGA-centric mixed scheme quantization (MSQ) with an ensemble of the proposed SP2 and the fixed-point schemes. Combining the two schemes can maintain, or even increase accuracy due to better matching with weight distributions.
MSP: An FPGA-Specific Mixed-Scheme, Multi-Precision Deep Neural Network Quantization Framework
Sep 16, 2020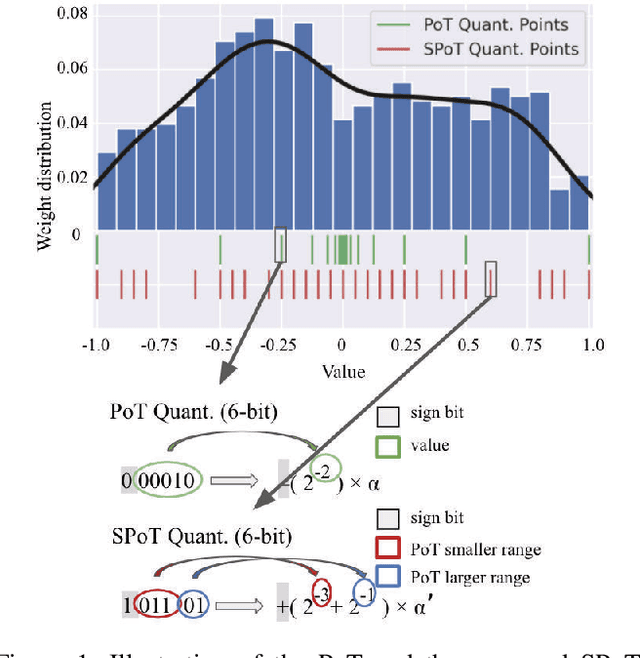
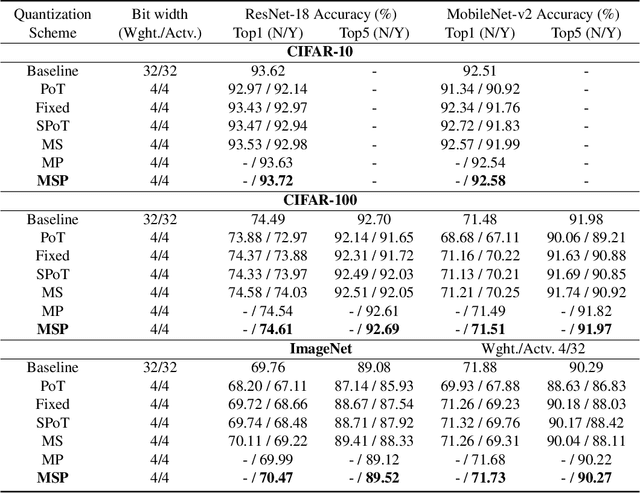


With the tremendous success of deep learning, there exists imminent need to deploy deep learning models onto edge devices. To tackle the limited computing and storage resources in edge devices, model compression techniques have been widely used to trim deep neural network (DNN) models for on-device inference execution. This paper targets the commonly used FPGA (field programmable gate array) devices as the hardware platforms for DNN edge computing. We focus on the DNN quantization as the main model compression technique, since DNN quantization has been of great importance for the implementations of DNN models on the hardware platforms. The novelty of this work comes in twofold: (i) We propose a mixed-scheme DNN quantization method that incorporates both the linear and non-linear number systems for quantization, with the aim to boost the utilization of the heterogeneous computing resources, i.e., LUTs (look up tables) and DSPs (digital signal processors) on an FPGA. Note that all the existing (single-scheme) quantization methods can only utilize one type of resources (either LUTs or DSPs for the MAC (multiply-accumulate) operations in deep learning computations. (ii) We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach.
Learning Tensor Latent Features
Oct 10, 2018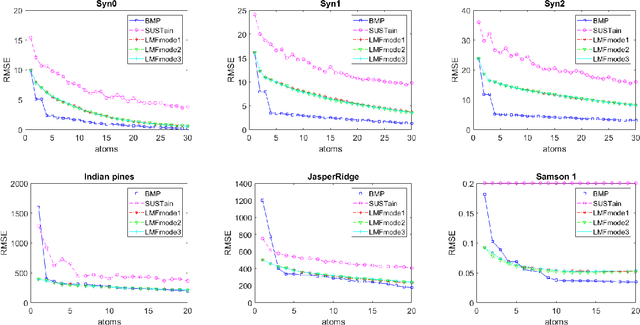
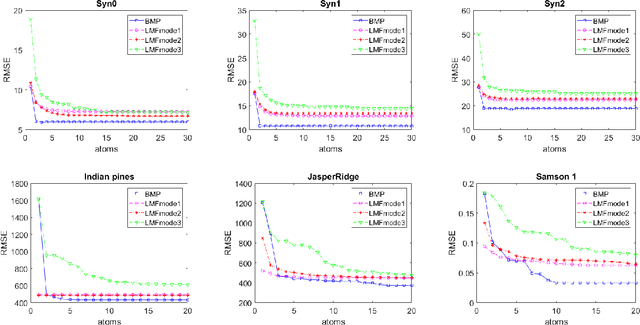
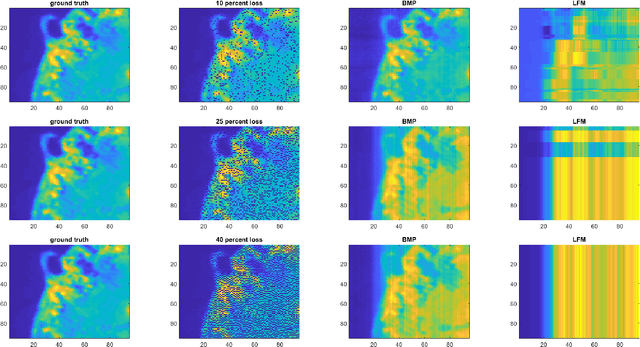
We study the problem of learning latent feature models (LFMs) for tensor data commonly observed in science and engineering such as hyperspectral imagery. However, the problem is challenging not only due to the non-convex formulation, the combinatorial nature of the constraints in LFMs, but also the high-order correlations in the data. In this work, we formulate a tensor latent feature learning problem by representing the data as a mixture of high-order latent features and binary codes, which are memory efficient and easy to interpret. To make the learning tractable, we propose a novel optimization procedure, Binary matching pursuit (BMP), that iteratively searches for binary bases via a MAXCUT-like boolean quadratic solver. Such a procedure is guaranteed to achieve an? suboptimal solution in O($1/\epsilon$) greedy steps, resulting in a trade-off between accuracy and sparsity. When evaluated on both synthetic and real datasets, our experiments show superior performance over baseline methods.