 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-in-One Tuning and Structural Pruning for Domain-Specific LLMs
Dec 19, 2024



Existing pruning techniques for large language models (LLMs) targeting domain-specific applications typically follow a two-stage process: pruning the pretrained general-purpose LLMs and then fine-tuning the pruned LLMs on specific domains. However, the pruning decisions, derived from the pretrained weights, remain unchanged during fine-tuning, even if the weights have been updated. Therefore, such a combination of the pruning decisions and the finetuned weights may be suboptimal, leading to non-negligible performance degradation. To address these limitations, we propose ATP: All-in-One Tuning and Structural Pruning, a unified one-stage structural pruning and fine-tuning approach that dynamically identifies the current optimal substructure throughout the fine-tuning phase via a trainable pruning decision generator. Moreover, given the limited available data for domain-specific applications, Low-Rank Adaptation (LoRA) becomes a common technique to fine-tune the LLMs. In ATP, we introduce LoRA-aware forward and sparsity regularization to ensure that the substructures corresponding to the learned pruning decisions can be directly removed after the ATP process. ATP outperforms the state-of-the-art two-stage pruning methods on tasks in the legal and healthcare domains. More specifically, ATP recovers up to 88% and 91% performance of the dense model when pruning 40% parameters of LLaMA2-7B and LLaMA3-8B models, respectively.
DLF: Disentangled-Language-Focused Multimodal Sentiment Analysis
Dec 16, 2024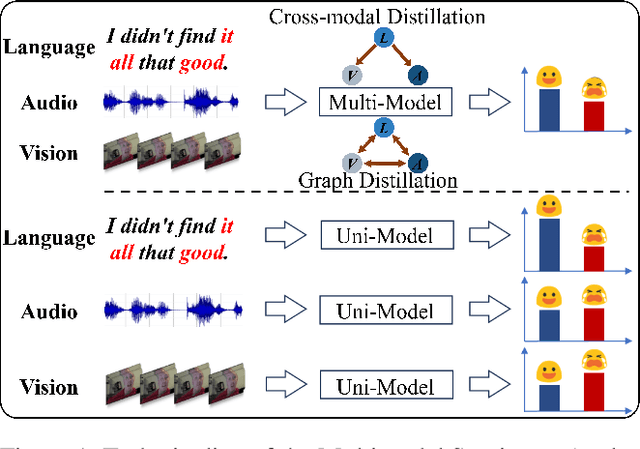
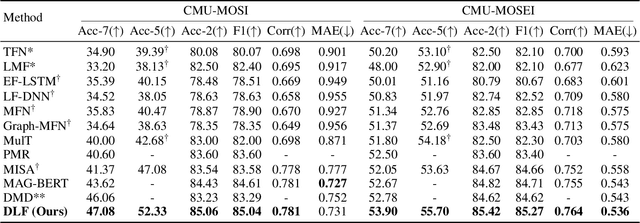
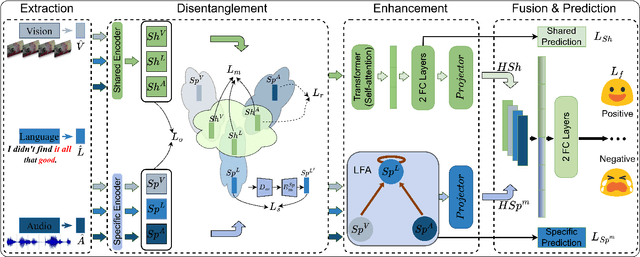
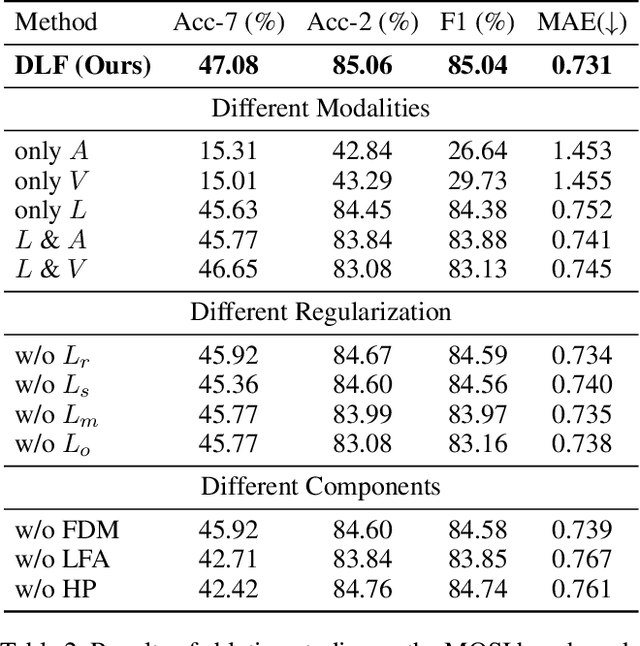
Multimodal Sentiment Analysis (MSA) leverages heterogeneous modalities, such as language, vision, and audio, to enhance the understanding of human sentiment. While existing models often focus on extracting shared information across modalities or directly fusing heterogeneous modalities, such approaches can introduce redundancy and conflicts due to equal treatment of all modalities and the mutual transfer of information between modality pairs. To address these issues, we propose a Disentangled-Language-Focused (DLF) multimodal representation learning framework, which incorporates a feature disentanglement module to separate modality-shared and modality-specific information. To further reduce redundancy and enhance language-targeted features, four geometric measures are introduced to refine the disentanglement process. A Language-Focused Attractor (LFA) is further developed to strengthen language representation by leveraging complementary modality-specific information through a language-guided cross-attention mechanism. The framework also employs hierarchical predictions to improve overall accuracy. Extensive experiments on two popular MSA datasets, CMU-MOSI and CMU-MOSEI, demonstrate the significant performance gains achieved by the proposed DLF framework. Comprehensive ablation studies further validate the effectiveness of the feature disentanglement module, language-focused attractor, and hierarchical predictions. Our code is available at https://github.com/pwang322/DLF.
A Self-guided Multimodal Approach to Enhancing Graph Representation Learning for Alzheimer's Diseases
Dec 09, 2024



Graph neural networks (GNNs) are powerful machine learning models designed to handle irregularly structured data. However, their generic design often proves inadequate for analyzing brain connectomes in Alzheimer's Disease (AD), highlighting the need to incorporate domain knowledge for optimal performance. Infusing AD-related knowledge into GNNs is a complicated task. Existing methods typically rely on collaboration between computer scientists and domain experts, which can be both time-intensive and resource-demanding. To address these limitations, this paper presents a novel self-guided, knowledge-infused multimodal GNN that autonomously incorporates domain knowledge into the model development process. Our approach conceptualizes domain knowledge as natural language and introduces a specialized multimodal GNN capable of leveraging this uncurated knowledge to guide the learning process of the GNN, such that it can improve the model performance and strengthen the interpretability of the predictions. To evaluate our framework, we curated a comprehensive dataset of recent peer-reviewed papers on AD and integrated it with multiple real-world AD datasets. Experimental results demonstrate the ability of our method to extract relevant domain knowledge, provide graph-based explanations for AD diagnosis, and improve the overall performance of the GNN. This approach provides a more scalable and efficient alternative to inject domain knowledge for AD compared with the manual design from the domain expert, advancing both prediction accuracy and interpretability in AD diagnosis.
Unlocking Memorization in Large Language Models with Dynamic Soft Prompting
Sep 20, 2024



Pretrained large language models (LLMs) have revolutionized natural language processing (NLP) tasks such as summarization, question answering, and translation. However, LLMs pose significant security risks due to their tendency to memorize training data, leading to potential privacy breaches and copyright infringement. Accurate measurement of this memorization is essential to evaluate and mitigate these potential risks. However, previous attempts to characterize memorization are constrained by either using prefixes only or by prepending a constant soft prompt to the prefixes, which cannot react to changes in input. To address this challenge, we propose a novel method for estimating LLM memorization using dynamic, prefix-dependent soft prompts. Our approach involves training a transformer-based generator to produce soft prompts that adapt to changes in input, thereby enabling more accurate extraction of memorized data. Our method not only addresses the limitations of previous methods but also demonstrates superior performance in diverse experimental settings compared to state-of-the-art techniques. In particular, our method can achieve the maximum relative improvement of 112.75% and 32.26% over the vanilla baseline in terms of discoverable memorization rate for the text generation task and code generation task respectively.
Contrastive Learning with Synthetic Positives
Aug 30, 2024Contrastive learning with the nearest neighbor has proved to be one of the most efficient self-supervised learning (SSL) techniques by utilizing the similarity of multiple instances within the same class. However, its efficacy is constrained as the nearest neighbor algorithm primarily identifies ``easy'' positive pairs, where the representations are already closely located in the embedding space. In this paper, we introduce a novel approach called Contrastive Learning with Synthetic Positives (CLSP) that utilizes synthetic images, generated by an unconditional diffusion model, as the additional positives to help the model learn from diverse positives. Through feature interpolation in the diffusion model sampling process, we generate images with distinct backgrounds yet similar semantic content to the anchor image. These images are considered ``hard'' positives for the anchor image, and when included as supplementary positives in the contrastive loss, they contribute to a performance improvement of over 2\% and 1\% in linear evaluation compared to the previous NNCLR and All4One methods across multiple benchmark datasets such as CIFAR10, achieving state-of-the-art methods. On transfer learning benchmarks, CLSP outperforms existing SSL frameworks on 6 out of 8 downstream datasets. We believe CLSP establishes a valuable baseline for future SSL studies incorporating synthetic data in the training process.
Rethinking Medical Anomaly Detection in Brain MRI: An Image Quality Assessment Perspective
Aug 15, 2024



Reconstruction-based methods, particularly those leveraging autoencoders, have been widely adopted to perform anomaly detection in brain MRI. While most existing works try to improve detection accuracy by proposing new model structures or algorithms, we tackle the problem through image quality assessment, an underexplored perspective in the field. We propose a fusion quality loss function that combines Structural Similarity Index Measure loss with l1 loss, offering a more comprehensive evaluation of reconstruction quality. Additionally, we introduce a data pre-processing strategy that enhances the average intensity ratio (AIR) between normal and abnormal regions, further improving the distinction of anomalies. By fusing the aforementioned two methods, we devise the image quality assessment (IQA) approach. The proposed IQA approach achieves significant improvements (>10%) in terms of Dice coefficient (DICE) and Area Under the Precision-Recall Curve (AUPRC) on the BraTS21 (T2, FLAIR) and MSULB datasets when compared with state-of-the-art methods. These results highlight the importance of invoking the comprehensive image quality assessment in medical anomaly detection and provide a new perspective for future research in this field.
Enhancing 3D Transformer Segmentation Model for Medical Image with Token-level Representation Learning
Aug 12, 2024In the field of medical images, although various works find Swin Transformer has promising effectiveness on pixelwise dense prediction, whether pre-training these models without using extra dataset can further boost the performance for the downstream semantic segmentation remains unexplored.Applications of previous representation learning methods are hindered by the limited number of 3D volumes and high computational cost. In addition, most of pretext tasks designed specifically for Transformer are not applicable to hierarchical structure of Swin Transformer. Thus, this work proposes a token-level representation learning loss that maximizes agreement between token embeddings from different augmented views individually instead of volume-level global features. Moreover, we identify a potential representation collapse exclusively caused by this new loss. To prevent collapse, we invent a simple "rotate-and-restore" mechanism, which rotates and flips one augmented view of input volume, and later restores the order of tokens in the feature maps. We also modify the contrastive loss to address the discrimination between tokens at the same position but from different volumes. We test our pre-training scheme on two public medical segmentation datasets, and the results on the downstream segmentation task show more improvement of our methods than other state-of-the-art pre-trainig methods.
EdgeOL: Efficient in-situ Online Learning on Edge Devices
Jan 30, 2024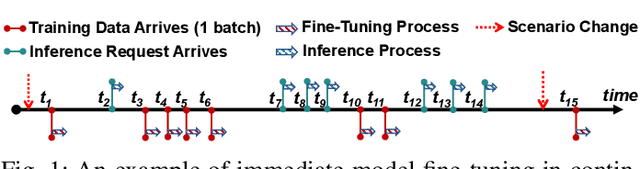
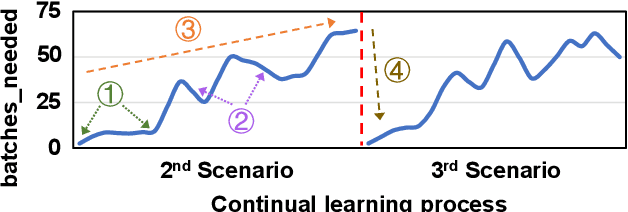
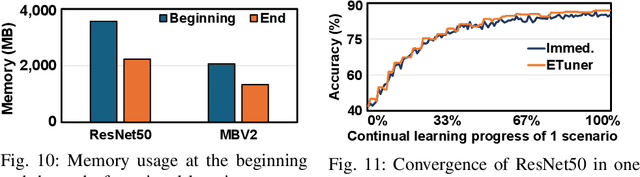
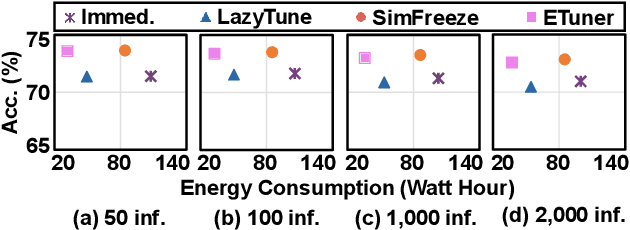
Emerging applications, such as robot-assisted eldercare and object recognition, generally employ deep learning neural networks (DNNs) models and naturally require: i) handling streaming-in inference requests and ii) adapting to possible deployment scenario changes. Online model fine-tuning is widely adopted to satisfy these needs. However, fine-tuning involves significant energy consumption, making it challenging to deploy on edge devices. In this paper, we propose EdgeOL, an edge online learning framework that optimizes inference accuracy, fine-tuning execution time, and energy efficiency through both inter-tuning and intra-tuning optimizations. Experimental results show that, on average, EdgeOL reduces overall fine-tuning execution time by 82%, energy consumption by 74%, and improves average inference accuracy by 1.70% over the immediate online learning strategy.
Achieve Fairness without Demographics for Dermatological Disease Diagnosis
Jan 16, 2024In medical image diagnosis, fairness has become increasingly crucial. Without bias mitigation, deploying unfair AI would harm the interests of the underprivileged population and potentially tear society apart. Recent research addresses prediction biases in deep learning models concerning demographic groups (e.g., gender, age, and race) by utilizing demographic (sensitive attribute) information during training. However, many sensitive attributes naturally exist in dermatological disease images. If the trained model only targets fairness for a specific attribute, it remains unfair for other attributes. Moreover, training a model that can accommodate multiple sensitive attributes is impractical due to privacy concerns. To overcome this, we propose a method enabling fair predictions for sensitive attributes during the testing phase without using such information during training. Inspired by prior work highlighting the impact of feature entanglement on fairness, we enhance the model features by capturing the features related to the sensitive and target attributes and regularizing the feature entanglement between corresponding classes. This ensures that the model can only classify based on the features related to the target attribute without relying on features associated with sensitive attributes, thereby improving fairness and accuracy. Additionally, we use disease masks from the Segment Anything Model (SAM) to enhance the quality of the learned feature. Experimental results demonstrate that the proposed method can improve fairness in classification compared to state-of-the-art methods in two dermatological disease datasets.
Additional Positive Enables Better Representation Learning for Medical Images
May 31, 2023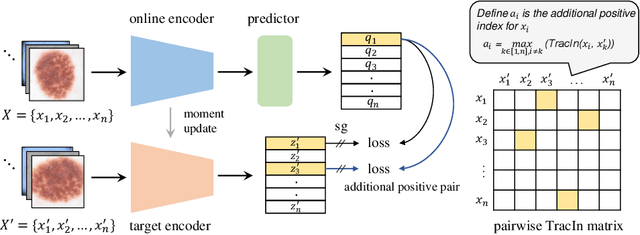
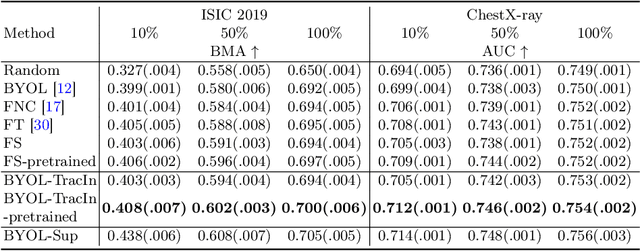
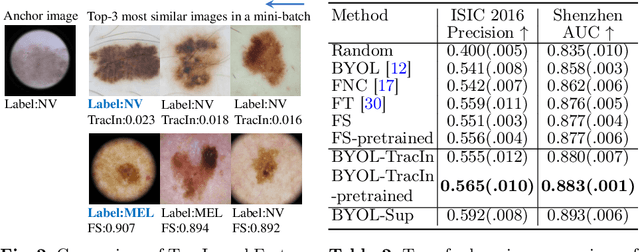
This paper presents a new way to identify additional positive pairs for BYOL, a state-of-the-art (SOTA) self-supervised learning framework, to improve its representation learning ability. Unlike conventional BYOL which relies on only one positive pair generated by two augmented views of the same image, we argue that information from different images with the same label can bring more diversity and variations to the target features, thus benefiting representation learning. To identify such pairs without any label, we investigate TracIn, an instance-based and computationally efficient influence function, for BYOL training. Specifically, TracIn is a gradient-based method that reveals the impact of a training sample on a test sample in supervised learning. We extend it to the self-supervised learning setting and propose an efficient batch-wise per-sample gradient computation method to estimate the pairwise TracIn to represent the similarity of samples in the mini-batch during training. For each image, we select the most similar sample from other images as the additional positive and pull their features together with BYOL loss. Experimental results on two public medical datasets (i.e., ISIC 2019 and ChestX-ray) demonstrate that the proposed method can improve the classification performance compared to other competitive baselines in both semi-supervised and transfer learning settings.