 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGI: Structured 2D Gaussians for Efficient and Compact Large Image Representation
Mar 10, 20262D Gaussian Splatting has emerged as a novel image representation technique that can support efficient rendering on low-end devices. However, scaling to high-resolution images requires optimizing and storing millions of unstructured Gaussian primitives independently, leading to slow convergence and redundant parameters. To address this, we propose Structured Gaussian Image (SGI), a compact and efficient framework for representing high-resolution images. SGI decomposes a complex image into multi-scale local spaces defined by a set of seeds. Each seed corresponds to a spatially coherent region and, together with lightweight multi-layer perceptrons (MLPs), generates structured implicit 2D neural Gaussians. This seed-based formulation imposes structural regularity on otherwise unstructured Gaussian primitives, which facilitates entropy-based compression at the seed level to reduce the total storage. However, optimizing seed parameters directly on high-resolution images is a challenging and non-trivial task. Therefore, we designed a multi-scale fitting strategy that refines the seed representation in a coarse-to-fine manner, substantially accelerating convergence. Quantitative and qualitative evaluations demonstrate that SGI achieves up to 7.5x compression over prior non-quantized 2D Gaussian methods and 1.6x over quantized ones, while also delivering 1.6x and 6.5x faster optimization, respectively, without degrading, and often improving, image fidelity. Code is available at https://github.com/zx-pan/SGI.
H-CNN-ViT: A Hierarchical Gated Attention Multi-Branch Model for Bladder Cancer Recurrence Prediction
Nov 19, 2025Bladder cancer is one of the most prevalent malignancies worldwide, with a recurrence rate of up to 78%, necessitating accurate post-operative monitoring for effective patient management. Multi-sequence contrast-enhanced MRI is commonly used for recurrence detection; however, interpreting these scans remains challenging, even for experienced radiologists, due to post-surgical alterations such as scarring, swelling, and tissue remodeling. AI-assisted diagnostic tools have shown promise in improving bladder cancer recurrence prediction, yet progress in this field is hindered by the lack of dedicated multi-sequence MRI datasets for recurrence assessment study. In this work, we first introduce a curated multi-sequence, multi-modal MRI dataset specifically designed for bladder cancer recurrence prediction, establishing a valuable benchmark for future research. We then propose H-CNN-ViT, a new Hierarchical Gated Attention Multi-Branch model that enables selective weighting of features from the global (ViT) and local (CNN) paths based on contextual demands, achieving a balanced and targeted feature fusion. Our multi-branch architecture processes each modality independently, ensuring that the unique properties of each imaging channel are optimally captured and integrated. Evaluated on our dataset, H-CNN-ViT achieves an AUC of 78.6%, surpassing state-of-the-art models. Our model is publicly available at https://github.com/XLIAaron/H-CNN-ViT.
Rethinking Medical Anomaly Detection in Brain MRI: An Image Quality Assessment Perspective
Aug 15, 2024



Reconstruction-based methods, particularly those leveraging autoencoders, have been widely adopted to perform anomaly detection in brain MRI. While most existing works try to improve detection accuracy by proposing new model structures or algorithms, we tackle the problem through image quality assessment, an underexplored perspective in the field. We propose a fusion quality loss function that combines Structural Similarity Index Measure loss with l1 loss, offering a more comprehensive evaluation of reconstruction quality. Additionally, we introduce a data pre-processing strategy that enhances the average intensity ratio (AIR) between normal and abnormal regions, further improving the distinction of anomalies. By fusing the aforementioned two methods, we devise the image quality assessment (IQA) approach. The proposed IQA approach achieves significant improvements (>10%) in terms of Dice coefficient (DICE) and Area Under the Precision-Recall Curve (AUPRC) on the BraTS21 (T2, FLAIR) and MSULB datasets when compared with state-of-the-art methods. These results highlight the importance of invoking the comprehensive image quality assessment in medical anomaly detection and provide a new perspective for future research in this field.
Empirical Guidelines for Deploying LLMs onto Resource-constrained Edge Devices
Jun 06, 2024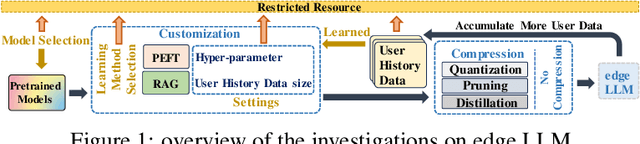
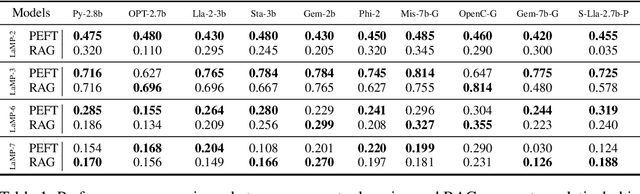
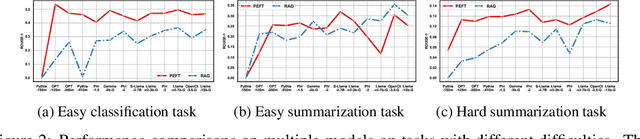

The scaling laws have become the de facto guidelines for designing large language models (LLMs), but they were studied under the assumption of unlimited computing resources for both training and inference. As LLMs are increasingly used as personalized intelligent assistants, their customization (i.e., learning through fine-tuning) and deployment onto resource-constrained edge devices will become more and more prevalent. An urging but open question is how a resource-constrained computing environment would affect the design choices for a personalized LLM. We study this problem empirically in this work. In particular, we consider the tradeoffs among a number of key design factors and their intertwined impacts on learning efficiency and accuracy. The factors include the learning methods for LLM customization, the amount of personalized data used for learning customization, the types and sizes of LLMs, the compression methods of LLMs, the amount of time afforded to learn, and the difficulty levels of the target use cases. Through extensive experimentation and benchmarking, we draw a number of surprisingly insightful guidelines for deploying LLMs onto resource-constrained devices. For example, an optimal choice between parameter learning and RAG may vary depending on the difficulty of the downstream task, the longer fine-tuning time does not necessarily help the model, and a compressed LLM may be a better choice than an uncompressed LLM to learn from limited personalized data.
Efficient Vision-Language Pre-training by Cluster Masking
May 14, 2024
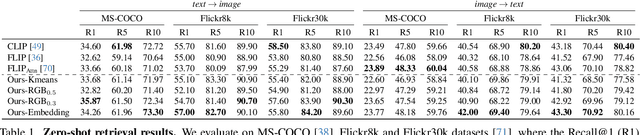


We propose a simple strategy for masking image patches during visual-language contrastive learning that improves the quality of the learned representations and the training speed. During each iteration of training, we randomly mask clusters of visually similar image patches, as measured by their raw pixel intensities. This provides an extra learning signal, beyond the contrastive training itself, since it forces a model to predict words for masked visual structures solely from context. It also speeds up training by reducing the amount of data used in each image. We evaluate the effectiveness of our model by pre-training on a number of benchmarks, finding that it outperforms other masking strategies, such as FLIP, on the quality of the learned representation.
Masked Diffusion as Self-supervised Representation Learner
Aug 27, 2023Denoising diffusion probabilistic models have recently demonstrated state-of-the-art generative performance and been used as strong pixel-level representation learners. This paper decomposes the interrelation between the generative capability and representation learning ability inherent in diffusion models. We present masked diffusion model (MDM), a scalable self-supervised representation learner that substitutes the conventional additive Gaussian noise of traditional diffusion with a masking mechanism. Our proposed approach convincingly surpasses prior benchmarks, demonstrating remarkable advancements in both medical and natural image semantic segmentation tasks, particularly within the context of few-shot scenario.
Discovering Intrinsic Reward with Contrastive Random Walk
Apr 23, 2022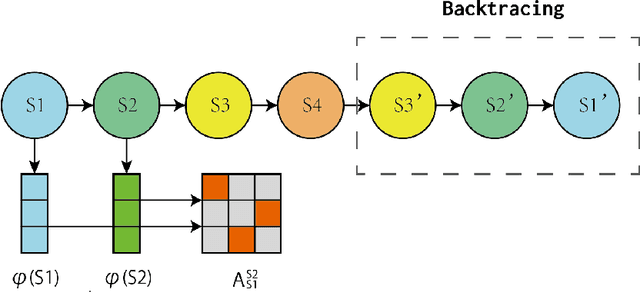

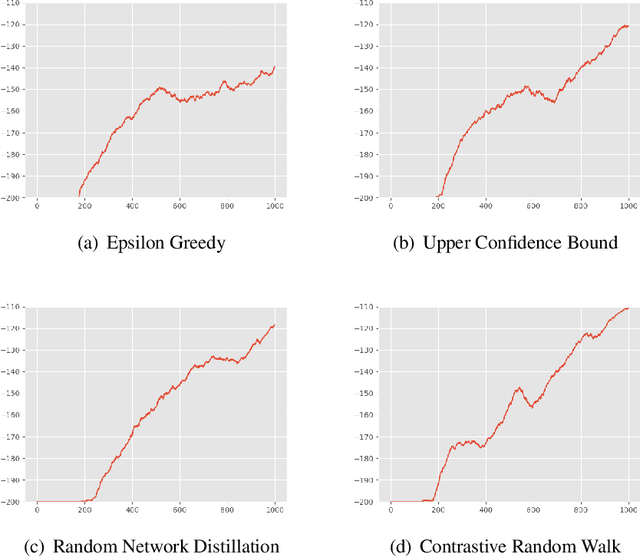
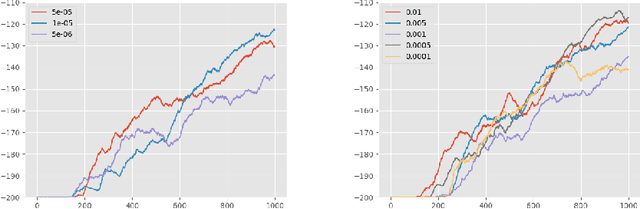
The aim of this paper is to demonstrate the efficacy of using Contrastive Random Walk as a curiosity method to achieve faster convergence to the optimal policy.Contrastive Random Walk defines the transition matrix of a random walk with the help of neural networks. It learns a meaningful state representation with a closed loop. The loss of Contrastive Random Walk serves as an intrinsic reward and is added to the environment reward. Our method works well in non-tabular sparse reward scenarios, in the sense that our method receives the highest reward within the same iterations compared to other methods. Meanwhile, Contrastive Random Walk is more robust. The performance doesn't change much with different random initialization of environments. We also find that adaptive restart and appropriate temperature are crucial to the performance of Contrastive Random Walk.