 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Vision-Language Pre-training by Cluster Masking
Paper and Code

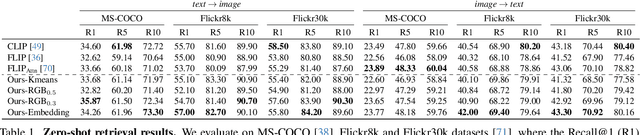


We propose a simple strategy for masking image patches during visual-language contrastive learning that improves the quality of the learned representations and the training speed. During each iteration of training, we randomly mask clusters of visually similar image patches, as measured by their raw pixel intensities. This provides an extra learning signal, beyond the contrastive training itself, since it forces a model to predict words for masked visual structures solely from context. It also speeds up training by reducing the amount of data used in each image. We evaluate the effectiveness of our model by pre-training on a number of benchmarks, finding that it outperforms other masking strategies, such as FLIP, on the quality of the learned representation.