 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCircular Reasoning: Understanding Self-Reinforcing Loops in Large Reasoning Models
Jan 09, 2026Despite the success of test-time scaling, Large Reasoning Models (LRMs) frequently encounter repetitive loops that lead to computational waste and inference failure. In this paper, we identify a distinct failure mode termed Circular Reasoning. Unlike traditional model degeneration, this phenomenon manifests as a self-reinforcing trap where generated content acts as a logical premise for its own recurrence, compelling the reiteration of preceding text. To systematically analyze this phenomenon, we introduce LoopBench, a dataset designed to capture two distinct loop typologies: numerical loops and statement loops. Mechanistically, we characterize circular reasoning as a state collapse exhibiting distinct boundaries, where semantic repetition precedes textual repetition. We reveal that reasoning impasses trigger the loop onset, which subsequently persists as an inescapable cycle driven by a self-reinforcing V-shaped attention mechanism. Guided by these findings, we employ the Cumulative Sum (CUSUM) algorithm to capture these precursors for early loop prediction. Experiments across diverse LRMs validate its accuracy and elucidate the stability of long-chain reasoning.
Masked Diffusion Captioning for Visual Feature Learning
Oct 30, 2025We learn visual features by captioning images with an image-conditioned masked diffusion language model, a formulation we call masked diffusion captioning (MDC). During training, text tokens in each image-caption pair are masked at a randomly chosen ratio, and a decoder conditioned on visual features is trained to reconstruct the original text. After training, the learned visual features can be applied to downstream vision tasks. Unlike autoregressive captioning, the strength of the visual learning signal in MDC does not depend on each token's position in the sequence, reducing the need for auxiliary objectives. Linear probing experiments across a variety of academic-scale models and datasets show that the learned visual features are competitive with those produced by autoregressive and contrastive approaches.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
ToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Feb 17, 2025
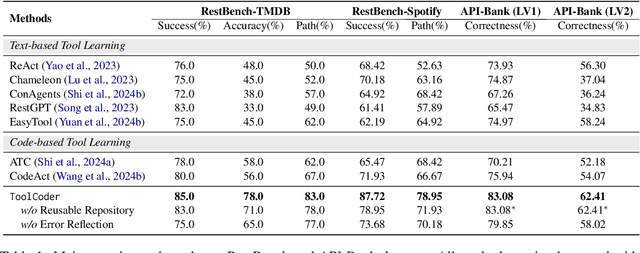
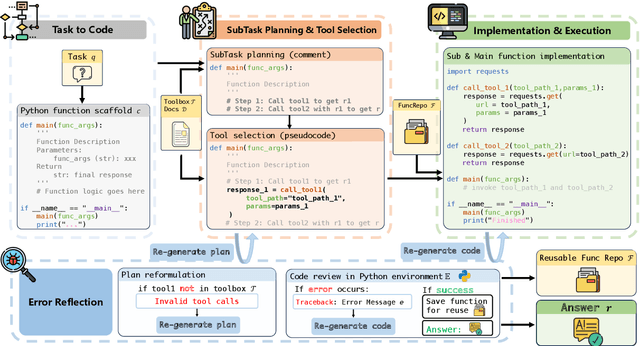
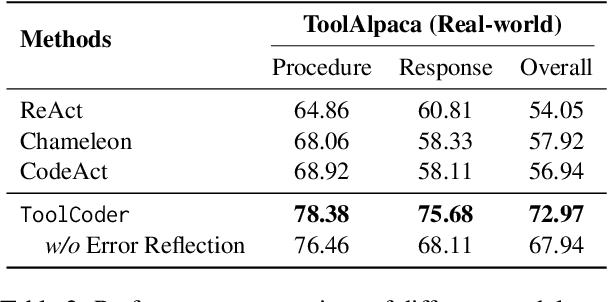
Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multi-step planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
Revisiting Robust RAG: Do We Still Need Complex Robust Training in the Era of Powerful LLMs?
Feb 17, 2025Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
Following the Autoregressive Nature of LLM Embeddings via Compression and Alignment
Feb 17, 2025A new trend uses LLMs as dense text encoders via contrastive learning. However, since LLM embeddings predict the probability distribution of the next token, they are inherently generative and distributive, conflicting with contrastive learning, which requires embeddings to capture full-text semantics and align via cosine similarity. This discrepancy hinders the full utilization of LLMs' pre-training capabilities, resulting in inefficient learning. In response to this issue, we propose AutoRegEmbed, a new contrastive learning method built on embedding conditional probability distributions, which integrates two core tasks: information compression and conditional distribution alignment. The information compression task encodes text into the embedding space, ensuring that the embedding vectors capture global semantics. The conditional distribution alignment task focuses on aligning text embeddings with positive samples embeddings by leveraging the conditional distribution of embeddings while simultaneously reducing the likelihood of generating negative samples from text embeddings, thereby achieving embedding alignment and uniformity. Experimental results demonstrate that our method significantly outperforms traditional contrastive learning approaches and achieves performance comparable to state-of-the-art models when using the same amount of data.
UnKE: Unstructured Knowledge Editing in Large Language Models
May 24, 2024



Recent knowledge editing methods have primarily focused on modifying structured knowledge in large language models, heavily relying on the assumption that structured knowledge is stored as key-value pairs locally in MLP layers or specific neurons. However, this task setting overlooks the fact that a significant portion of real-world knowledge is stored in an unstructured format, characterized by long-form content, noise, and a complex yet comprehensive nature. The "knowledge locating" and "term-driven optimization" techniques conducted from the assumption used in previous methods (e.g., MEMIT) are ill-suited for unstructured knowledge. To address these challenges, we propose a novel unstructured knowledge editing method, namely UnKE, which extends previous assumptions in the layer dimension and token dimension. Firstly, in the layer dimension, we discard the "knowledge locating" step and treat first few layers as the key, which expand knowledge storage through layers to break the "knowledge stored locally" assumption. Next, we replace "term-driven optimization" with "cause-driven optimization" across all inputted tokens in the token dimension, directly optimizing the last layer of the key generator to perform editing to generate the required key vectors. By utilizing key-value pairs at the layer level, UnKE effectively represents and edits complex and comprehensive unstructured knowledge, leveraging the potential of both the MLP and attention layers. Results on newly proposed unstructure knowledge editing dataset (UnKEBench) and traditional structured datasets demonstrate that UnKE achieves remarkable performance, surpassing strong baselines.
Efficient Vision-Language Pre-training by Cluster Masking
May 14, 2024
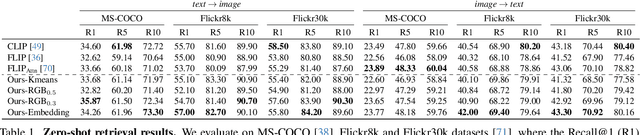


We propose a simple strategy for masking image patches during visual-language contrastive learning that improves the quality of the learned representations and the training speed. During each iteration of training, we randomly mask clusters of visually similar image patches, as measured by their raw pixel intensities. This provides an extra learning signal, beyond the contrastive training itself, since it forces a model to predict words for masked visual structures solely from context. It also speeds up training by reducing the amount of data used in each image. We evaluate the effectiveness of our model by pre-training on a number of benchmarks, finding that it outperforms other masking strategies, such as FLIP, on the quality of the learned representation.
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Apr 07, 2024



The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.