 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToolCoder: A Systematic Code-Empowered Tool Learning Framework for Large Language Models
Feb 17, 2025
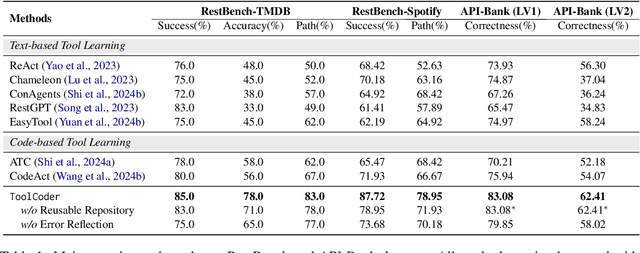
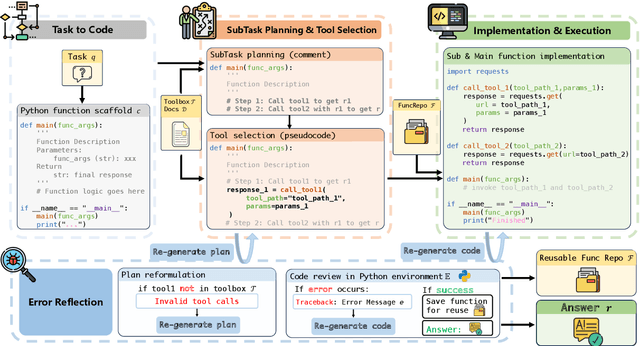
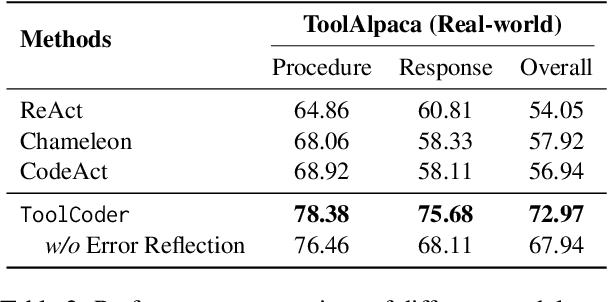
Tool learning has emerged as a crucial capability for large language models (LLMs) to solve complex real-world tasks through interaction with external tools. Existing approaches face significant challenges, including reliance on hand-crafted prompts, difficulty in multi-step planning, and lack of precise error diagnosis and reflection mechanisms. We propose ToolCoder, a novel framework that reformulates tool learning as a code generation task. Inspired by software engineering principles, ToolCoder transforms natural language queries into structured Python function scaffold and systematically breaks down tasks with descriptive comments, enabling LLMs to leverage coding paradigms for complex reasoning and planning. It then generates and executes function implementations to obtain final responses. Additionally, ToolCoder stores successfully executed functions in a repository to promote code reuse, while leveraging error traceback mechanisms for systematic debugging, optimizing both execution efficiency and robustness. Experiments demonstrate that ToolCoder achieves superior performance in task completion accuracy and execution reliability compared to existing approaches, establishing the effectiveness of code-centric approaches in tool learning.
Uncertainty Calibration for Ensemble-Based Debiasing Methods
Nov 07, 2021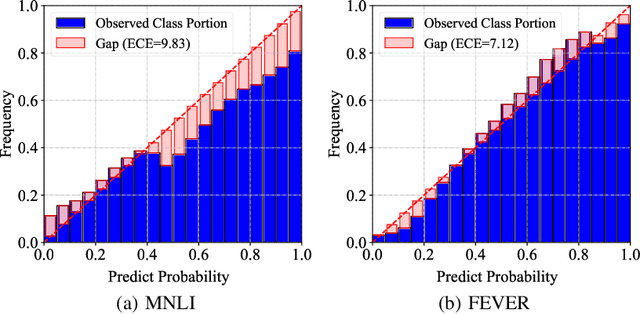
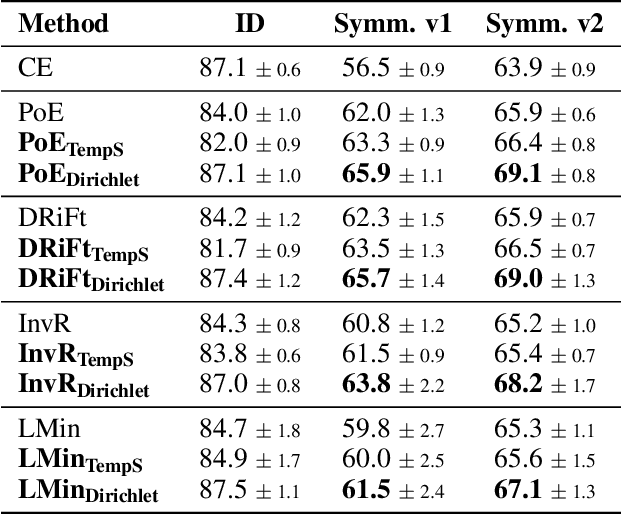
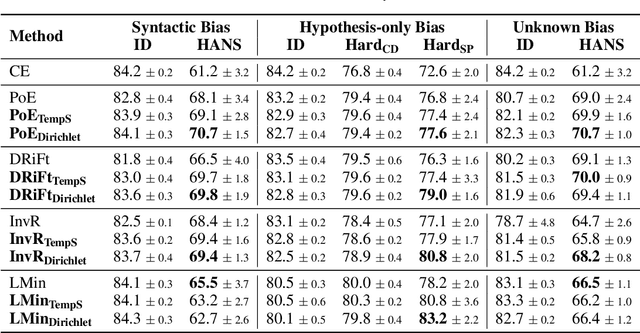
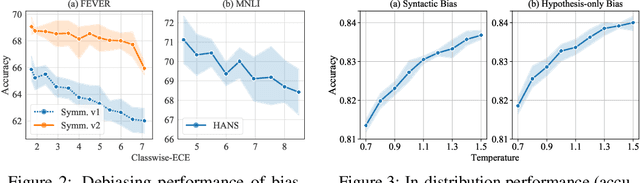
Ensemble-based debiasing methods have been shown effective in mitigating the reliance of classifiers on specific dataset bias, by exploiting the output of a bias-only model to adjust the learning target. In this paper, we focus on the bias-only model in these ensemble-based methods, which plays an important role but has not gained much attention in the existing literature. Theoretically, we prove that the debiasing performance can be damaged by inaccurate uncertainty estimations of the bias-only model. Empirically, we show that existing bias-only models fall short in producing accurate uncertainty estimations. Motivated by these findings, we propose to conduct calibration on the bias-only model, thus achieving a three-stage ensemble-based debiasing framework, including bias modeling, model calibrating, and debiasing. Experimental results on NLI and fact verification tasks show that our proposed three-stage debiasing framework consistently outperforms the traditional two-stage one in out-of-distribution accuracy.