 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Advantage Estimation: Enhancing PPO for Long-Context LLM Training
Jan 12, 2026Training Large Language Models (LLMs) for reasoning tasks is increasingly driven by Reinforcement Learning with Verifiable Rewards (RLVR), where Proximal Policy Optimization (PPO) provides a principled framework for stable policy updates. However, the practical application of PPO is hindered by unreliable advantage estimation in the sparse-reward RLVR regime. This issue arises because the sparse rewards in RLVR lead to inaccurate intermediate value predictions, which in turn introduce significant bias when aggregated at every token by Generalized Advantage Estimation (GAE). To address this, we introduce Segmental Advantage Estimation (SAE), which mitigates the bias that GAE can incur in RLVR. Our key insight is that aggregating $n$-step advantages at every token(as in GAE) is unnecessary and often introduces excessive bias, since individual tokens carry minimal information. Instead, SAE first partitions the generated sequence into coherent sub-segments using low-probability tokens as heuristic boundaries. It then selectively computes variance-reduced advantage estimates only from these information-rich segment transitions, effectively filtering out noise from intermediate tokens. Our experiments demonstrate that SAE achieves superior performance, with marked improvements in final scores, training stability, and sample efficiency. These gains are shown to be consistent across multiple model sizes, and a correlation analysis confirms that our proposed advantage estimator achieves a higher correlation with an approximate ground-truth advantage, justifying its superior performance.
Beyond Outlining: Heterogeneous Recursive Planning for Adaptive Long-form Writing with Language Models
Mar 11, 2025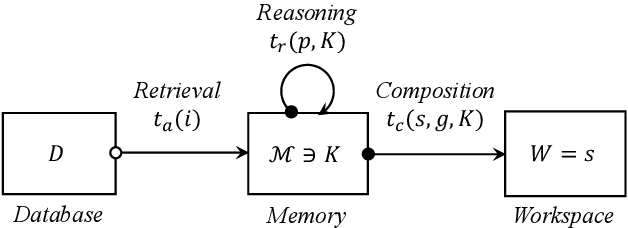
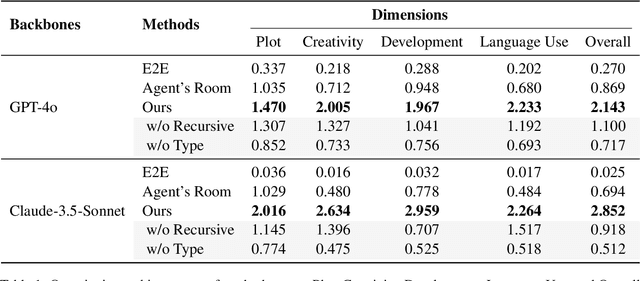
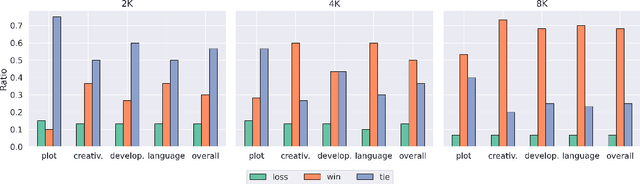
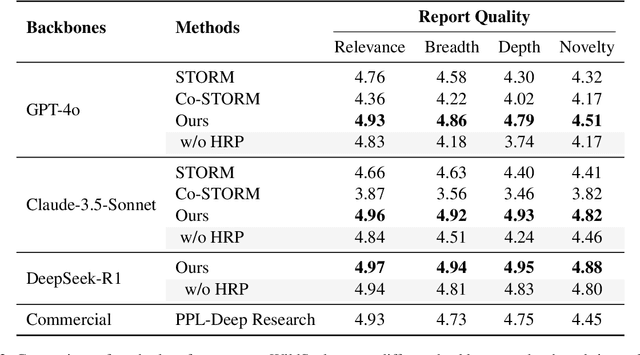
Long-form writing agents require flexible integration and interaction across information retrieval, reasoning, and composition. Current approaches rely on predetermined workflows and rigid thinking patterns to generate outlines before writing, resulting in constrained adaptability during writing. In this paper we propose a general agent framework that achieves human-like adaptive writing through recursive task decomposition and dynamic integration of three fundamental task types, i.e. retrieval, reasoning, and composition. Our methodology features: 1) a planning mechanism that interleaves recursive task decomposition and execution, eliminating artificial restrictions on writing workflow; and 2) integration of task types that facilitates heterogeneous task decomposition. Evaluations on both fiction writing and technical report generation show that our method consistently outperforms state-of-the-art approaches across all automatic evaluation metrics, which demonstrate the effectiveness and broad applicability of our proposed framework.
From Novice to Expert: LLM Agent Policy Optimization via Step-wise Reinforcement Learning
Nov 06, 2024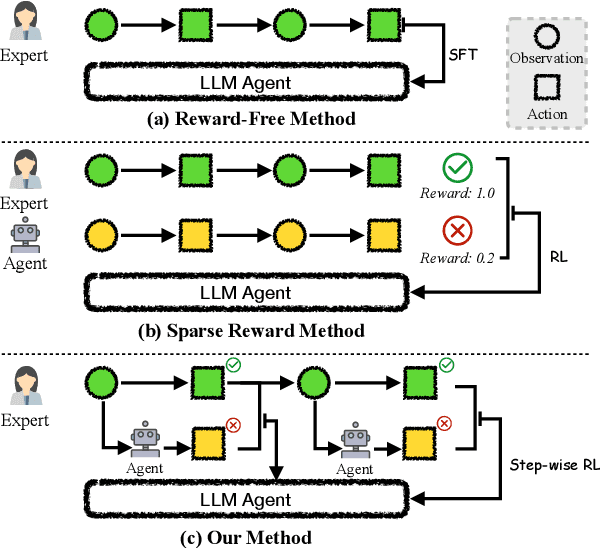
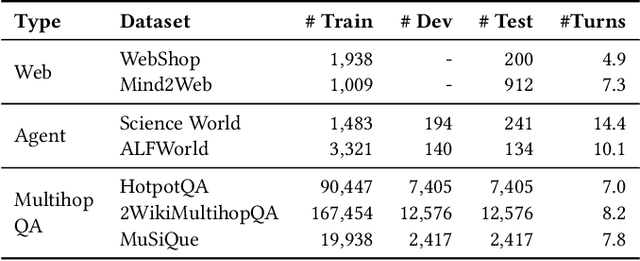

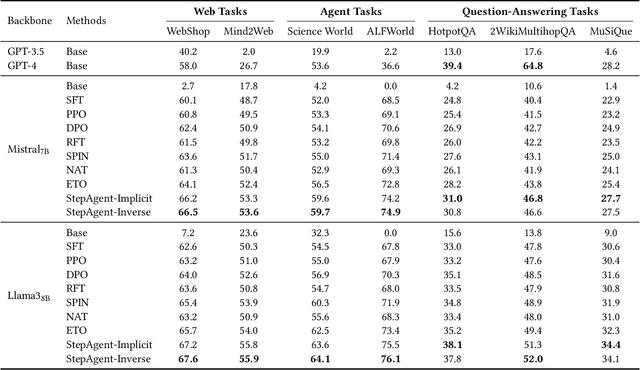
The outstanding capabilities of large language models (LLMs) render them a crucial component in various autonomous agent systems. While traditional methods depend on the inherent knowledge of LLMs without fine-tuning, more recent approaches have shifted toward the reinforcement learning strategy to further enhance agents' ability to solve complex interactive tasks with environments and tools. However, previous approaches are constrained by the sparse reward issue, where existing datasets solely provide a final scalar reward for each multi-step reasoning chain, potentially leading to ineffectiveness and inefficiency in policy learning. In this paper, we introduce StepAgent, which utilizes step-wise reward to optimize the agent's reinforcement learning process. Inheriting the spirit of novice-to-expert theory, we first compare the actions of the expert and the agent to automatically generate intermediate rewards for fine-grained optimization. Additionally, we propose implicit-reward and inverse reinforcement learning techniques to facilitate agent reflection and policy adjustment. Further theoretical analysis demonstrates that the action distribution of the agent can converge toward the expert action distribution over multiple training cycles. Experimental results across various datasets indicate that StepAgent outperforms existing baseline methods.
When Does Group Invariant Learning Survive Spurious Correlations?
Jun 29, 2022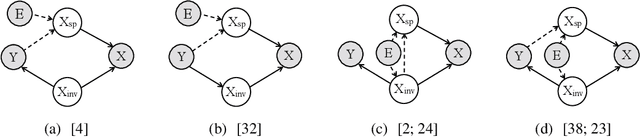
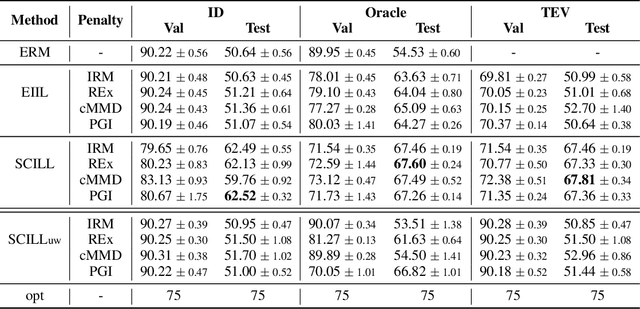
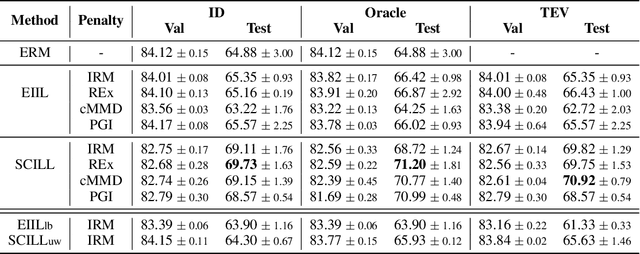
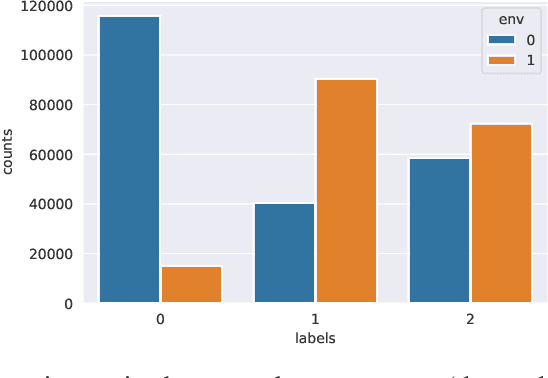
By inferring latent groups in the training data, recent works introduce invariant learning to the case where environment annotations are unavailable. Typically, learning group invariance under a majority/minority split is empirically shown to be effective in improving out-of-distribution generalization on many datasets. However, theoretical guarantee for these methods on learning invariant mechanisms is lacking. In this paper, we reveal the insufficiency of existing group invariant learning methods in preventing classifiers from depending on spurious correlations in the training set. Specifically, we propose two criteria on judging such sufficiency. Theoretically and empirically, we show that existing methods can violate both criteria and thus fail in generalizing to spurious correlation shifts. Motivated by this, we design a new group invariant learning method, which constructs groups with statistical independence tests, and reweights samples by group label proportion to meet the criteria. Experiments on both synthetic and real data demonstrate that the new method significantly outperforms existing group invariant learning methods in generalizing to spurious correlation shifts.
Uncertainty Calibration for Ensemble-Based Debiasing Methods
Nov 07, 2021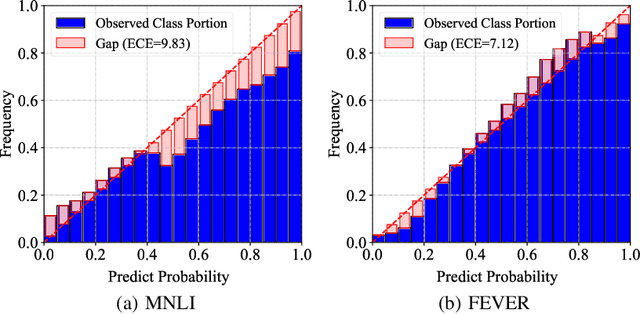
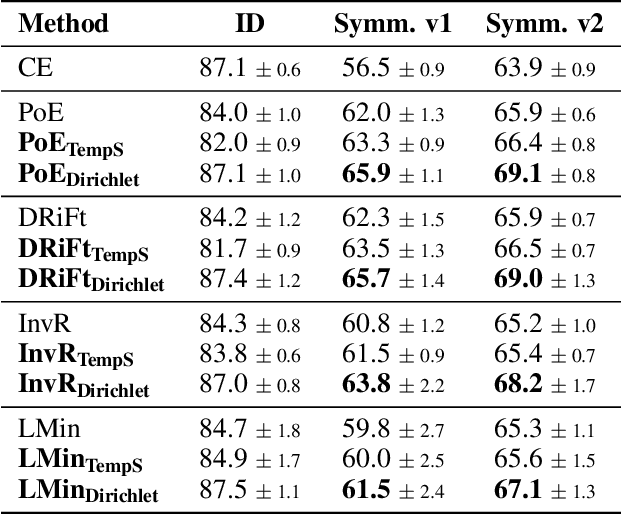
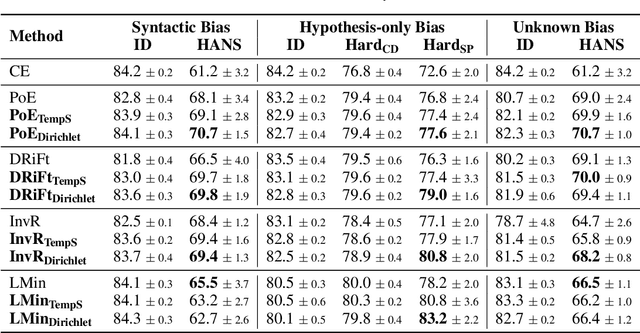
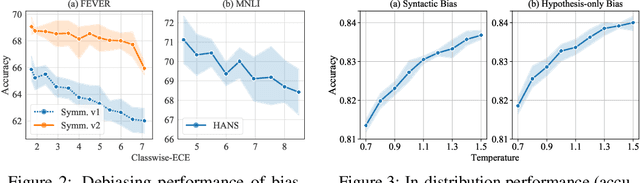
Ensemble-based debiasing methods have been shown effective in mitigating the reliance of classifiers on specific dataset bias, by exploiting the output of a bias-only model to adjust the learning target. In this paper, we focus on the bias-only model in these ensemble-based methods, which plays an important role but has not gained much attention in the existing literature. Theoretically, we prove that the debiasing performance can be damaged by inaccurate uncertainty estimations of the bias-only model. Empirically, we show that existing bias-only models fall short in producing accurate uncertainty estimations. Motivated by these findings, we propose to conduct calibration on the bias-only model, thus achieving a three-stage ensemble-based debiasing framework, including bias modeling, model calibrating, and debiasing. Experimental results on NLI and fact verification tasks show that our proposed three-stage debiasing framework consistently outperforms the traditional two-stage one in out-of-distribution accuracy.
On Layer Normalization in the Transformer Architecture
Feb 12, 2020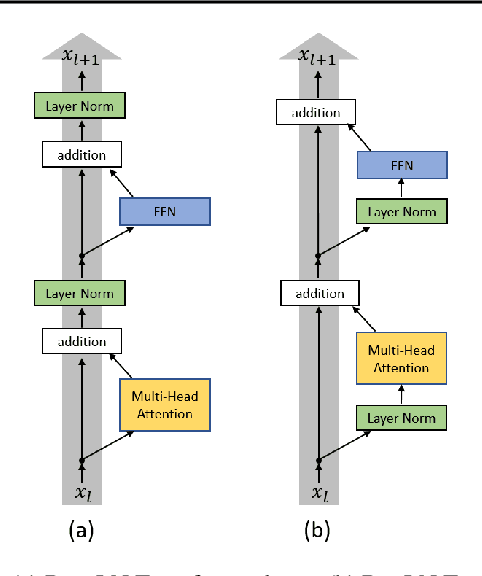

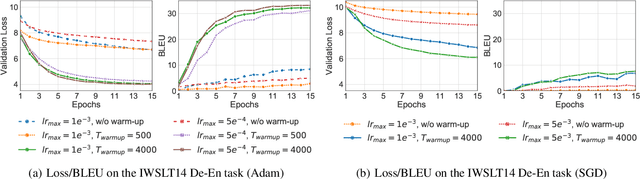

The Transformer is widely used in natural language processing tasks. To train a Transformer however, one usually needs a carefully designed learning rate warm-up stage, which is shown to be crucial to the final performance but will slow down the optimization and bring more hyper-parameter tunings. In this paper, we first study theoretically why the learning rate warm-up stage is essential and show that the location of layer normalization matters. Specifically, we prove with mean field theory that at initialization, for the original-designed Post-LN Transformer, which places the layer normalization between the residual blocks, the expected gradients of the parameters near the output layer are large. Therefore, using a large learning rate on those gradients makes the training unstable. The warm-up stage is practically helpful for avoiding this problem. On the other hand, our theory also shows that if the layer normalization is put inside the residual blocks (recently proposed as Pre-LN Transformer), the gradients are well-behaved at initialization. This motivates us to remove the warm-up stage for the training of Pre-LN Transformers. We show in our experiments that Pre-LN Transformers without the warm-up stage can reach comparable results with baselines while requiring significantly less training time and hyper-parameter tuning on a wide range of applications.