 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPARKLING: Balancing Signal Preservation and Symmetry Breaking for Width-Progressive Learning
Feb 02, 2026Progressive Learning (PL) reduces pre-training computational overhead by gradually increasing model scale. While prior work has extensively explored depth expansion, width expansion remains significantly understudied, with the few existing methods limited to the early stages of training. However, expanding width during the mid-stage is essential for maximizing computational savings, yet it remains a formidable challenge due to severe training instabilities. Empirically, we show that naive initialization at this stage disrupts activation statistics, triggering loss spikes, while copy-based initialization introduces gradient symmetry that hinders feature diversity. To address these issues, we propose SPARKLING (balancing {S}ignal {P}reservation {A}nd symmet{R}y brea{K}ing for width-progressive {L}earn{ING}), a novel framework for mid-stage width expansion. Our method achieves signal preservation via RMS-scale consistency, stabilizing activation statistics during expansion. Symmetry breaking is ensured through asymmetric optimizer state resetting and learning rate re-warmup. Extensive experiments on Mixture-of-Experts (MoE) models demonstrate that, across multiple width axes and optimizer families, SPARKLING consistently outperforms training from scratch and reduces training cost by up to 35% under $2\times$ width expansion.
Towards Solving the Gilbert-Pollak Conjecture via Large Language Models
Jan 29, 2026The Gilbert-Pollak Conjecture \citep{gilbert1968steiner}, also known as the Steiner Ratio Conjecture, states that for any finite point set in the Euclidean plane, the Steiner minimum tree has length at least $\sqrt{3}/2 \approx 0.866$ times that of the Euclidean minimum spanning tree (the Steiner ratio). A sequence of improvements through the 1980s culminated in a lower bound of $0.824$, with no substantial progress reported over the past three decades. Recent advances in LLMs have demonstrated strong performance on contest-level mathematical problems, yet their potential for addressing open, research-level questions remains largely unexplored. In this work, we present a novel AI system for obtaining tighter lower bounds on the Steiner ratio. Rather than directly prompting LLMs to solve the conjecture, we task them with generating rule-constrained geometric lemmas implemented as executable code. These lemmas are then used to construct a collection of specialized functions, which we call verification functions, that yield theoretically certified lower bounds of the Steiner ratio. Through progressive lemma refinement driven by reflection, the system establishes a new certified lower bound of 0.8559 for the Steiner ratio. The entire research effort involves only thousands of LLM calls, demonstrating the strong potential of LLM-based systems for advanced mathematical research.
The AI Hippocampus: How Far are We From Human Memory?
Jan 14, 2026Memory plays a foundational role in augmenting the reasoning, adaptability, and contextual fidelity of modern Large Language Models and Multi-Modal LLMs. As these models transition from static predictors to interactive systems capable of continual learning and personalized inference, the incorporation of memory mechanisms has emerged as a central theme in their architectural and functional evolution. This survey presents a comprehensive and structured synthesis of memory in LLMs and MLLMs, organizing the literature into a cohesive taxonomy comprising implicit, explicit, and agentic memory paradigms. Specifically, the survey delineates three primary memory frameworks. Implicit memory refers to the knowledge embedded within the internal parameters of pre-trained transformers, encompassing their capacity for memorization, associative retrieval, and contextual reasoning. Recent work has explored methods to interpret, manipulate, and reconfigure this latent memory. Explicit memory involves external storage and retrieval components designed to augment model outputs with dynamic, queryable knowledge representations, such as textual corpora, dense vectors, and graph-based structures, thereby enabling scalable and updatable interaction with information sources. Agentic memory introduces persistent, temporally extended memory structures within autonomous agents, facilitating long-term planning, self-consistency, and collaborative behavior in multi-agent systems, with relevance to embodied and interactive AI. Extending beyond text, the survey examines the integration of memory within multi-modal settings, where coherence across vision, language, audio, and action modalities is essential. Key architectural advances, benchmark tasks, and open challenges are discussed, including issues related to memory capacity, alignment, factual consistency, and cross-system interoperability.
Luminark: Training-free, Probabilistically-Certified Watermarking for General Vision Generative Models
Jan 03, 2026In this paper, we introduce \emph{Luminark}, a training-free and probabilistically-certified watermarking method for general vision generative models. Our approach is built upon a novel watermark definition that leverages patch-level luminance statistics. Specifically, the service provider predefines a binary pattern together with corresponding patch-level thresholds. To detect a watermark in a given image, we evaluate whether the luminance of each patch surpasses its threshold and then verify whether the resulting binary pattern aligns with the target one. A simple statistical analysis demonstrates that the false positive rate of the proposed method can be effectively controlled, thereby ensuring certified detection. To enable seamless watermark injection across different paradigms, we leverage the widely adopted guidance technique as a plug-and-play mechanism and develop the \emph{watermark guidance}. This design enables Luminark to achieve generality across state-of-the-art generative models without compromising image quality. Empirically, we evaluate our approach on nine models spanning diffusion, autoregressive, and hybrid frameworks. Across all evaluations, Luminark consistently demonstrates high detection accuracy, strong robustness against common image transformations, and good performance on visual quality.
Efficient Reasoning for Large Reasoning Language Models via Certainty-Guided Reflection Suppression
Aug 07, 2025Recent Large Reasoning Language Models (LRLMs) employ long chain-of-thought reasoning with complex reflection behaviors, typically signaled by specific trigger words (e.g., "Wait" and "Alternatively") to enhance performance. However, these reflection behaviors can lead to the overthinking problem where the generation of redundant reasoning steps that unnecessarily increase token usage, raise inference costs, and reduce practical utility. In this paper, we propose Certainty-Guided Reflection Suppression (CGRS), a novel method that mitigates overthinking in LRLMs while maintaining reasoning accuracy. CGRS operates by dynamically suppressing the model's generation of reflection triggers when it exhibits high confidence in its current response, thereby preventing redundant reflection cycles without compromising output quality. Our approach is model-agnostic, requires no retraining or architectural modifications, and can be integrated seamlessly with existing autoregressive generation pipelines. Extensive experiments across four reasoning benchmarks (i.e., AIME24, AMC23, MATH500, and GPQA-D) demonstrate CGRS's effectiveness: it reduces token usage by an average of 18.5% to 41.9% while preserving accuracy. It also achieves the optimal balance between length reduction and performance compared to state-of-the-art baselines. These results hold consistently across model architectures (e.g., DeepSeek-R1-Distill series, QwQ-32B, and Qwen3 family) and scales (4B to 32B parameters), highlighting CGRS's practical value for efficient reasoning.
Solving the Hubbard model with Neural Quantum States
Jul 03, 2025The rapid development of neural quantum states (NQS) has established it as a promising framework for studying quantum many-body systems. In this work, by leveraging the cutting-edge transformer-based architectures and developing highly efficient optimization algorithms, we achieve the state-of-the-art results for the doped two-dimensional (2D) Hubbard model, arguably the minimum model for high-Tc superconductivity. Interestingly, we find different attention heads in the NQS ansatz can directly encode correlations at different scales, making it capable of capturing long-range correlations and entanglements in strongly correlated systems. With these advances, we establish the half-filled stripe in the ground state of 2D Hubbard model with the next nearest neighboring hoppings, consistent with experimental observations in cuprates. Our work establishes NQS as a powerful tool for solving challenging many-fermions systems.
AlphaDecay:Module-wise Weight Decay for Heavy-Tailed Balancing in LLMs
Jun 17, 2025Weight decay is a standard regularization technique for training large language models (LLMs). While it is common to assign a uniform decay rate to every layer, this approach overlooks the structural diversity of LLMs and the varying spectral properties across modules. In this paper, we introduce AlphaDecay, a simple yet effective method that adaptively assigns different weight decay strengths to each module of an LLM. Our approach is guided by Heavy-Tailed Self-Regularization (HT-SR) theory, which analyzes the empirical spectral density (ESD) of weight correlation matrices to quantify "heavy-tailedness." Modules exhibiting more pronounced heavy-tailed ESDs, reflecting stronger feature learning, are assigned weaker decay, while modules with lighter-tailed spectra receive stronger decay. Our method leverages tailored weight decay assignments to balance the module-wise differences in spectral properties, leading to improved performance. Extensive pre-training tasks with various model sizes from 60M to 1B demonstrate that AlphaDecay achieves better perplexity and generalization than conventional uniform decay and other adaptive decay baselines.
Diagnosing and Improving Diffusion Models by Estimating the Optimal Loss Value
Jun 16, 2025Diffusion models have achieved remarkable success in generative modeling. Despite more stable training, the loss of diffusion models is not indicative of absolute data-fitting quality, since its optimal value is typically not zero but unknown, leading to confusion between large optimal loss and insufficient model capacity. In this work, we advocate the need to estimate the optimal loss value for diagnosing and improving diffusion models. We first derive the optimal loss in closed form under a unified formulation of diffusion models, and develop effective estimators for it, including a stochastic variant scalable to large datasets with proper control of variance and bias. With this tool, we unlock the inherent metric for diagnosing the training quality of mainstream diffusion model variants, and develop a more performant training schedule based on the optimal loss. Moreover, using models with 120M to 1.5B parameters, we find that the power law is better demonstrated after subtracting the optimal loss from the actual training loss, suggesting a more principled setting for investigating the scaling law for diffusion models.
Theoretical Benefit and Limitation of Diffusion Language Model
Feb 13, 2025
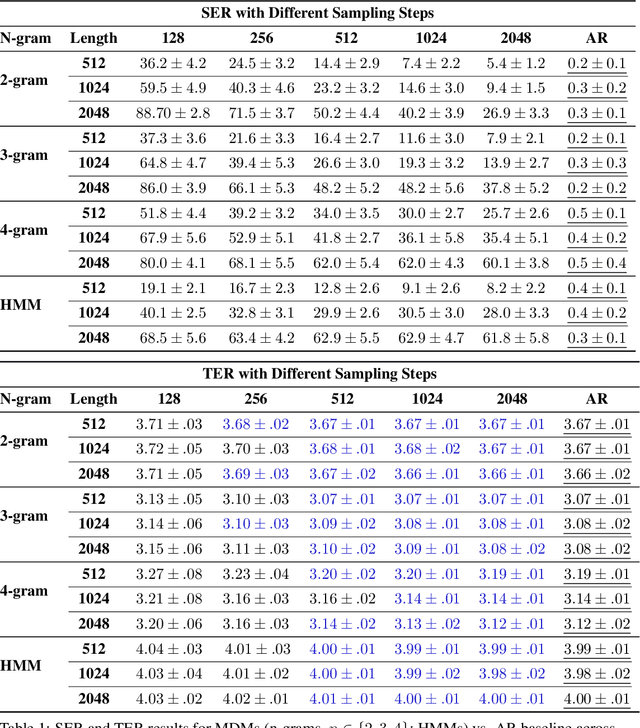
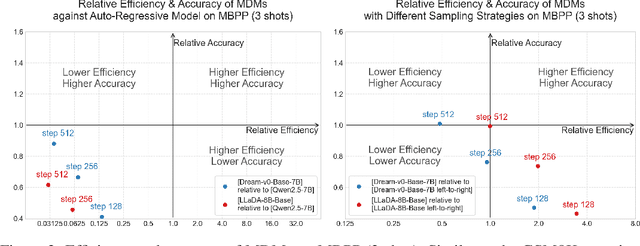
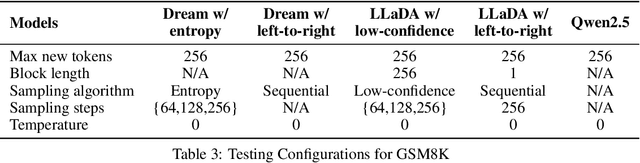
Diffusion language models have emerged as a promising approach for text generation. One would naturally expect this method to be an efficient replacement for autoregressive models since multiple tokens can be sampled in parallel during each diffusion step. However, its efficiency-accuracy trade-off is not yet well understood. In this paper, we present a rigorous theoretical analysis of a widely used type of diffusion language model, the Masked Diffusion Model (MDM), and find that its effectiveness heavily depends on the target evaluation metric. Under mild conditions, we prove that when using perplexity as the metric, MDMs can achieve near-optimal perplexity in sampling steps regardless of sequence length, demonstrating that efficiency can be achieved without sacrificing performance. However, when using the sequence error rate--which is important for understanding the "correctness" of a sequence, such as a reasoning chain--we show that the required sampling steps must scale linearly with sequence length to obtain "correct" sequences, thereby eliminating MDM's efficiency advantage over autoregressive models. Our analysis establishes the first theoretical foundation for understanding the benefits and limitations of MDMs. All theoretical findings are supported by empirical studies.
Enhancing Auto-regressive Chain-of-Thought through Loop-Aligned Reasoning
Feb 12, 2025



Chain-of-Thought (CoT) prompting has emerged as a powerful technique for enhancing language model's reasoning capabilities. However, generating long and correct CoT trajectories is challenging. Recent studies have demonstrated that Looped Transformers possess remarkable length generalization capabilities, but their limited generality and adaptability prevent them from serving as an alternative to auto-regressive solutions. To better leverage the strengths of Looped Transformers, we propose RELAY (REasoning through Loop Alignment iterativelY). Specifically, we align the steps of Chain-of-Thought (CoT) reasoning with loop iterations and apply intermediate supervision during the training of Looped Transformers. This additional iteration-wise supervision not only preserves the Looped Transformer's ability for length generalization but also enables it to predict CoT reasoning steps for unseen data. Therefore, we leverage this Looped Transformer to generate accurate reasoning chains for complex problems that exceed the training length, which will then be used to fine-tune an auto-regressive model. We conduct extensive experiments, and the results demonstrate the effectiveness of our approach, with significant improvements in the performance of the auto-regressive model. Code will be released at https://github.com/qifanyu/RELAY.