 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Discovered Intention-aware Transformer for Multi-modal Vehicle Trajectory Prediction
Apr 08, 2026Predicting vehicle trajectories plays an important role in autonomous driving and ITS applications. Although multiple deep learning algorithms are devised to predict vehicle trajectories, their reliant on specific graph structure (e.g., Graph Neural Network) or explicit intention labeling limit their flexibilities. In this study, we propose a pure Transformer-based network with multiple modals considering their neighboring vehicles. Two separate tracks are employed. One track focuses on predicting the trajectories while the other focuses on predicting the likelihood of each intention considering neighboring vehicles. Study finds that the two track design can increase the performance by separating spatial module from the trajectory generating module. Also, we find the the model can learn an ordered group of trajectories by predicting residual offsets among K trajectories.
GCAgent: Enhancing Group Chat Communication through Dialogue Agents System
Mar 05, 2026As a key form in online social platforms, group chat is a popular space for interest exchange or problem-solving, but its effectiveness is often hindered by inactivity and management challenges. While recent large language models (LLMs) have powered impressive one-to-one conversational agents, their seamlessly integration into multi-participant conversations remains unexplored. To address this gap, we introduce GCAgent, an LLM-driven system for enhancing group chats communication with both entertainment- and utility-oriented dialogue agents. The system comprises three tightly integrated modules: Agent Builder, which customizes agents to align with users' interests; Dialogue Manager, which coordinates dialogue states and manage agent invocations; and Interface Plugins, which reduce interaction barriers by three distinct tools. Through extensive experiment, GCAgent achieved an average score of 4.68 across various criteria and was preferred in 51.04\% of cases compared to its base model. Additionally, in real-world deployments over 350 days, it increased message volume by 28.80\%, significantly improving group activity and engagement. Overall, this work presents a practical blueprint for extending LLM-based dialogue agent from one-party chats to multi-party group scenarios.
From Tags to Trees: Structuring Fine-Grained Knowledge for Controllable Data Selection in LLM Instruction Tuning
Jan 20, 2026Effective and controllable data selection is critical for LLM instruction tuning, especially with massive open-source datasets. Existing approaches primarily rely on instance-level quality scores, or diversity metrics based on embedding clusters or semantic tags. However, constrained by the flatness of embedding spaces or the coarseness of tags, these approaches overlook fine-grained knowledge and its intrinsic hierarchical dependencies, consequently hindering precise data valuation and knowledge-aligned sampling. To address this challenge, we propose Tree-aware Aligned Global Sampling (TAGS), a unified framework that leverages a knowledge tree built from fine-grained tags, thereby enabling joint control of global quality, diversity, and target alignment. Using an LLM-based tagger, we extract atomic knowledge concepts, which are organized into a global tree through bottom-up hierarchical clustering. By grounding data instances onto this tree, a tree-aware metric then quantifies data quality and diversity, facilitating effective sampling. Our controllable sampling strategy maximizes tree-level information gain and enforces leaf-level alignment via KL-divergence for specific domains. Extensive experiments demonstrate that TAGS significantly outperforms state-of-the-art baselines. Notably, it surpasses the full-dataset model by \textbf{+5.84\%} using only \textbf{5\%} of the data, while our aligned sampling strategy further boosts average performance by \textbf{+4.24\%}.
PaRT: Enhancing Proactive Social Chatbots with Personalized Real-Time Retrieval
Apr 29, 2025Social chatbots have become essential intelligent companions in daily scenarios ranging from emotional support to personal interaction. However, conventional chatbots with passive response mechanisms usually rely on users to initiate or sustain dialogues by bringing up new topics, resulting in diminished engagement and shortened dialogue duration. In this paper, we present PaRT, a novel framework enabling context-aware proactive dialogues for social chatbots through personalized real-time retrieval and generation. Specifically, PaRT first integrates user profiles and dialogue context into a large language model (LLM), which is initially prompted to refine user queries and recognize their underlying intents for the upcoming conversation. Guided by refined intents, the LLM generates personalized dialogue topics, which then serve as targeted queries to retrieve relevant passages from RedNote. Finally, we prompt LLMs with summarized passages to generate knowledge-grounded and engagement-optimized responses. Our approach has been running stably in a real-world production environment for more than 30 days, achieving a 21.77\% improvement in the average duration of dialogues.
A Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
Generating Event-oriented Attribution for Movies via Two-Stage Prefix-Enhanced Multimodal LLM
Sep 14, 2024The prosperity of social media platforms has raised the urgent demand for semantic-rich services, e.g., event and storyline attribution. However, most existing research focuses on clip-level event understanding, primarily through basic captioning tasks, without analyzing the causes of events across an entire movie. This is a significant challenge, as even advanced multimodal large language models (MLLMs) struggle with extensive multimodal information due to limited context length. To address this issue, we propose a Two-Stage Prefix-Enhanced MLLM (TSPE) approach for event attribution, i.e., connecting associated events with their causal semantics, in movie videos. In the local stage, we introduce an interaction-aware prefix that guides the model to focus on the relevant multimodal information within a single clip, briefly summarizing the single event. Correspondingly, in the global stage, we strengthen the connections between associated events using an inferential knowledge graph, and design an event-aware prefix that directs the model to focus on associated events rather than all preceding clips, resulting in accurate event attribution. Comprehensive evaluations of two real-world datasets demonstrate that our framework outperforms state-of-the-art methods.
Knowledge-driven AI-generated data for accurate and interpretable breast ultrasound diagnoses
Jul 23, 2024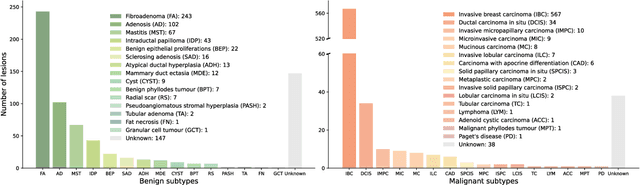
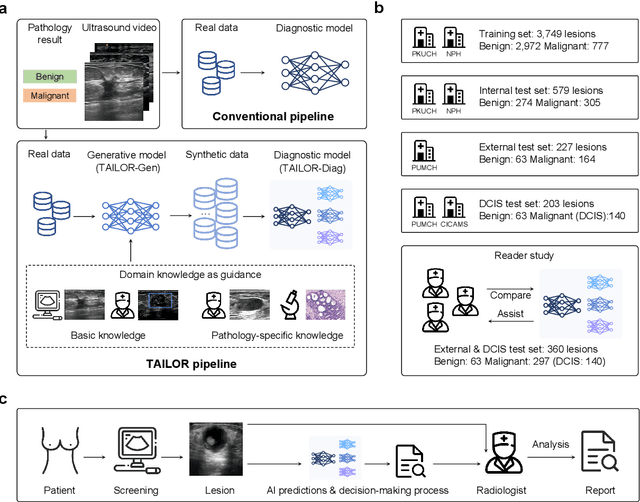
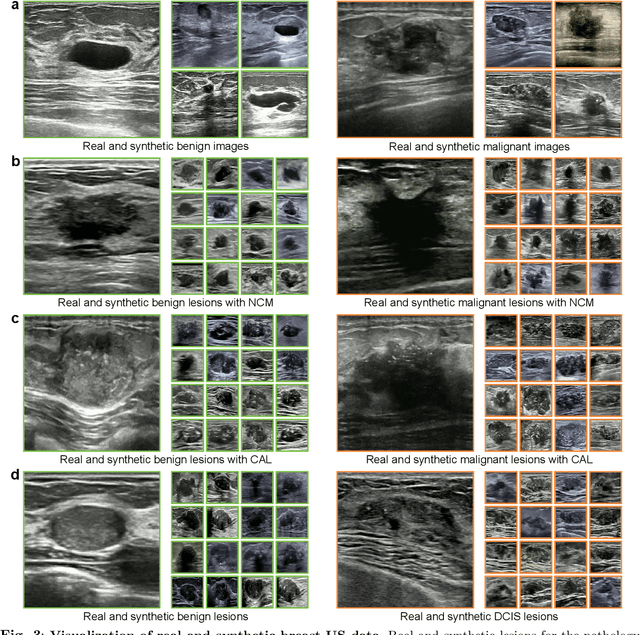
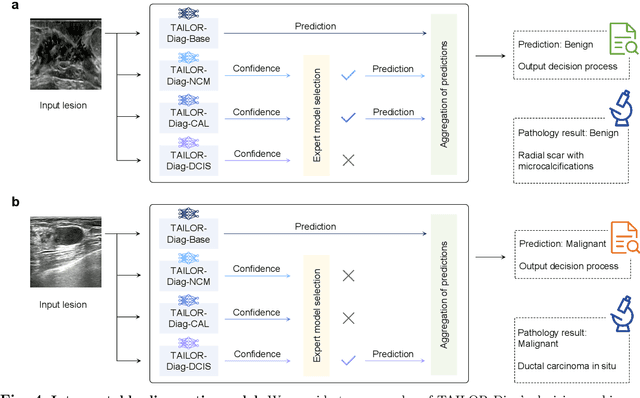
Data-driven deep learning models have shown great capabilities to assist radiologists in breast ultrasound (US) diagnoses. However, their effectiveness is limited by the long-tail distribution of training data, which leads to inaccuracies in rare cases. In this study, we address a long-standing challenge of improving the diagnostic model performance on rare cases using long-tailed data. Specifically, we introduce a pipeline, TAILOR, that builds a knowledge-driven generative model to produce tailored synthetic data. The generative model, using 3,749 lesions as source data, can generate millions of breast-US images, especially for error-prone rare cases. The generated data can be further used to build a diagnostic model for accurate and interpretable diagnoses. In the prospective external evaluation, our diagnostic model outperforms the average performance of nine radiologists by 33.5% in specificity with the same sensitivity, improving their performance by providing predictions with an interpretable decision-making process. Moreover, on ductal carcinoma in situ (DCIS), our diagnostic model outperforms all radiologists by a large margin, with only 34 DCIS lesions in the source data. We believe that TAILOR can potentially be extended to various diseases and imaging modalities.
Retrieve-Plan-Generation: An Iterative Planning and Answering Framework for Knowledge-Intensive LLM Generation
Jun 21, 2024



Despite the significant progress of large language models (LLMs) in various tasks, they often produce factual errors due to their limited internal knowledge. Retrieval-Augmented Generation (RAG), which enhances LLMs with external knowledge sources, offers a promising solution. However, these methods can be misled by irrelevant paragraphs in retrieved documents. Due to the inherent uncertainty in LLM generation, inputting the entire document may introduce off-topic information, causing the model to deviate from the central topic and affecting the relevance of the generated content. To address these issues, we propose the Retrieve-Plan-Generation (RPG) framework. RPG generates plan tokens to guide subsequent generation in the plan stage. In the answer stage, the model selects relevant fine-grained paragraphs based on the plan and uses them for further answer generation. This plan-answer process is repeated iteratively until completion, enhancing generation relevance by focusing on specific topics. To implement this framework efficiently, we utilize a simple but effective multi-task prompt-tuning method, enabling the existing LLMs to handle both planning and answering. We comprehensively compare RPG with baselines across 5 knowledge-intensive generation tasks, demonstrating the effectiveness of our approach.