 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundational Generative Model for Breast Ultrasound Image Analysis
Jan 12, 2025



Foundational models have emerged as powerful tools for addressing various tasks in clinical settings. However, their potential development to breast ultrasound analysis remains untapped. In this paper, we present BUSGen, the first foundational generative model specifically designed for breast ultrasound image analysis. Pretrained on over 3.5 million breast ultrasound images, BUSGen has acquired extensive knowledge of breast structures, pathological features, and clinical variations. With few-shot adaptation, BUSGen can generate repositories of realistic and informative task-specific data, facilitating the development of models for a wide range of downstream tasks. Extensive experiments highlight BUSGen's exceptional adaptability, significantly exceeding real-data-trained foundational models in breast cancer screening, diagnosis, and prognosis. In breast cancer early diagnosis, our approach outperformed all board-certified radiologists (n=9), achieving an average sensitivity improvement of 16.5% (P-value<0.0001). Additionally, we characterized the scaling effect of using generated data which was as effective as the collected real-world data for training diagnostic models. Moreover, extensive experiments demonstrated that our approach improved the generalization ability of downstream models. Importantly, BUSGen protected patient privacy by enabling fully de-identified data sharing, making progress forward in secure medical data utilization. An online demo of BUSGen is available at https://aibus.bio.
Knowledge-driven AI-generated data for accurate and interpretable breast ultrasound diagnoses
Jul 23, 2024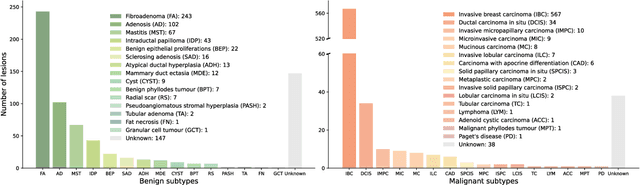
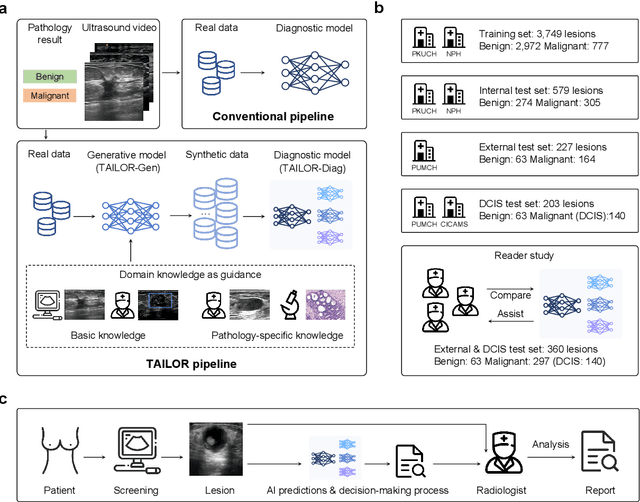
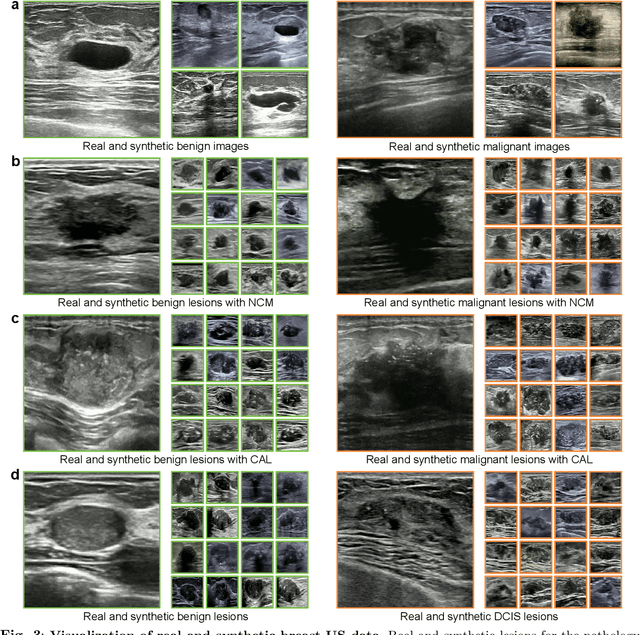
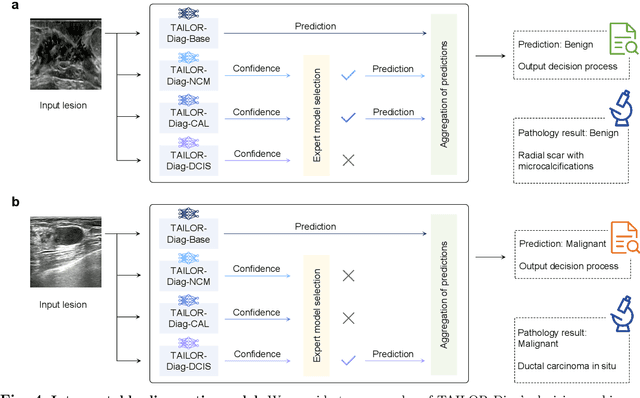
Data-driven deep learning models have shown great capabilities to assist radiologists in breast ultrasound (US) diagnoses. However, their effectiveness is limited by the long-tail distribution of training data, which leads to inaccuracies in rare cases. In this study, we address a long-standing challenge of improving the diagnostic model performance on rare cases using long-tailed data. Specifically, we introduce a pipeline, TAILOR, that builds a knowledge-driven generative model to produce tailored synthetic data. The generative model, using 3,749 lesions as source data, can generate millions of breast-US images, especially for error-prone rare cases. The generated data can be further used to build a diagnostic model for accurate and interpretable diagnoses. In the prospective external evaluation, our diagnostic model outperforms the average performance of nine radiologists by 33.5% in specificity with the same sensitivity, improving their performance by providing predictions with an interpretable decision-making process. Moreover, on ductal carcinoma in situ (DCIS), our diagnostic model outperforms all radiologists by a large margin, with only 34 DCIS lesions in the source data. We believe that TAILOR can potentially be extended to various diseases and imaging modalities.
VarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding
Nov 01, 2022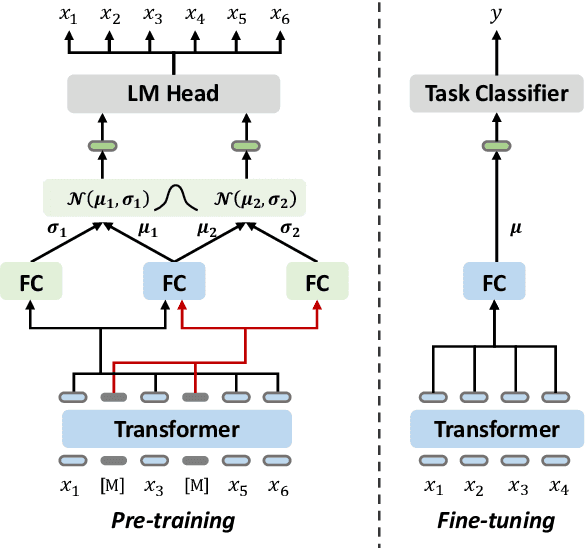
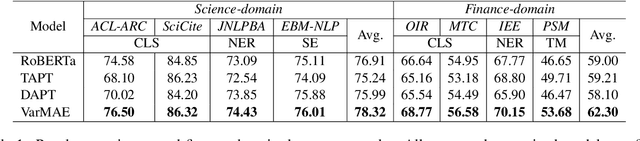

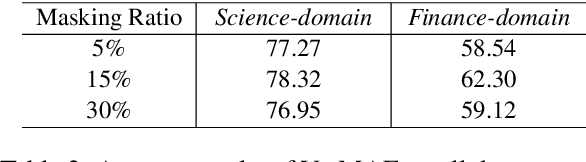
Pre-trained language models have achieved promising performance on general benchmarks, but underperform when migrated to a specific domain. Recent works perform pre-training from scratch or continual pre-training on domain corpora. However, in many specific domains, the limited corpus can hardly support obtaining precise representations. To address this issue, we propose a novel Transformer-based language model named VarMAE for domain-adaptive language understanding. Under the masked autoencoding objective, we design a context uncertainty learning module to encode the token's context into a smooth latent distribution. The module can produce diverse and well-formed contextual representations. Experiments on science- and finance-domain NLU tasks demonstrate that VarMAE can be efficiently adapted to new domains with limited resources.
PALI-NLP at SemEval-2022 Task 4: Discriminative Fine-tuning of Deep Transformers for Patronizing and Condescending Language Detection
Mar 09, 2022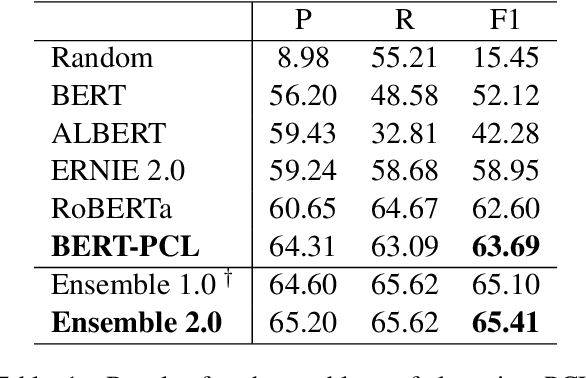
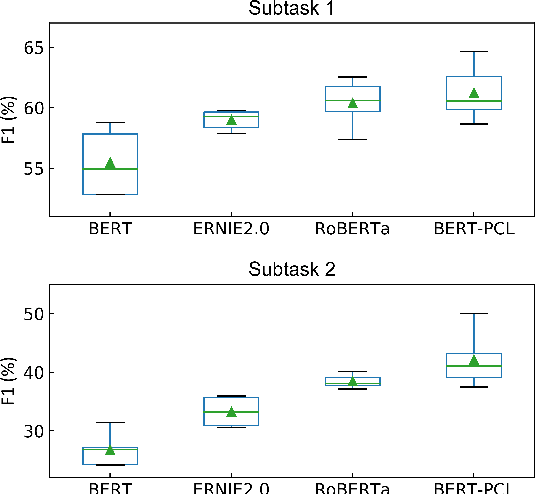
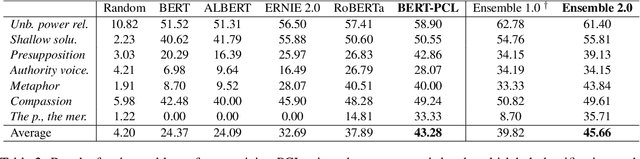
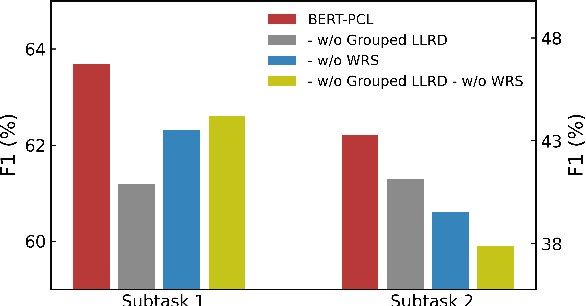
Patronizing and condescending language (PCL) has a large harmful impact and is difficult to detect, both for human judges and existing NLP systems. At SemEval-2022 Task 4, we propose a novel Transformer-based model and its ensembles to accurately understand such language context for PCL detection. To facilitate comprehension of the subtle and subjective nature of PCL, two fine-tuning strategies are applied to capture discriminative features from diverse linguistic behaviour and categorical distribution. The system achieves remarkable results on the official ranking, namely 1st in Subtask 1 and 5th in Subtask 2. Extensive experiments on the task demonstrate the effectiveness of our system and its strategies.
Sequential Attention Module for Natural Language Processing
Sep 07, 2021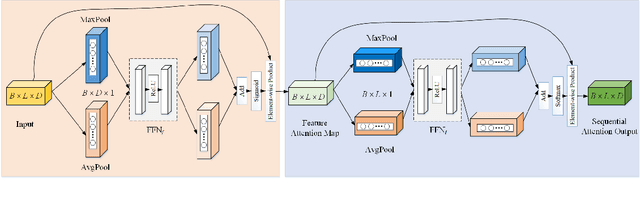


Recently, large pre-trained neural language models have attained remarkable performance on many downstream natural language processing (NLP) applications via fine-tuning. In this paper, we target at how to further improve the token representations on the language models. We, therefore, propose a simple yet effective plug-and-play module, Sequential Attention Module (SAM), on the token embeddings learned from a pre-trained language model. Our proposed SAM consists of two main attention modules deployed sequentially: Feature-wise Attention Module (FAM) and Token-wise Attention Module (TAM). More specifically, FAM can effectively identify the importance of features at each dimension and promote the effect via dot-product on the original token embeddings for downstream NLP applications. Meanwhile, TAM can further re-weight the features at the token-wise level. Moreover, we propose an adaptive filter on FAM to prevent noise impact and increase information absorption. Finally, we conduct extensive experiments to demonstrate the advantages and properties of our proposed SAM. We first show how SAM plays a primary role in the champion solution of two subtasks of SemEval'21 Task 7. After that, we apply SAM on sentiment analysis and three popular NLP tasks and demonstrate that SAM consistently outperforms the state-of-the-art baselines.
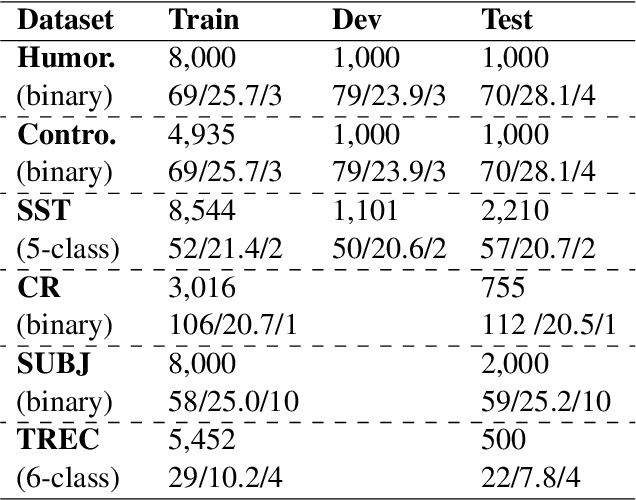
Sattiy at SemEval-2021 Task 9: An Ensemble Solution for Statement Verification and Evidence Finding with Tables
Apr 21, 2021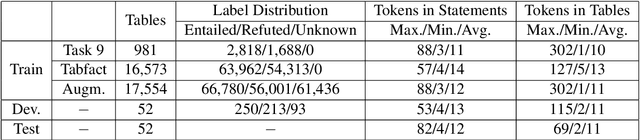
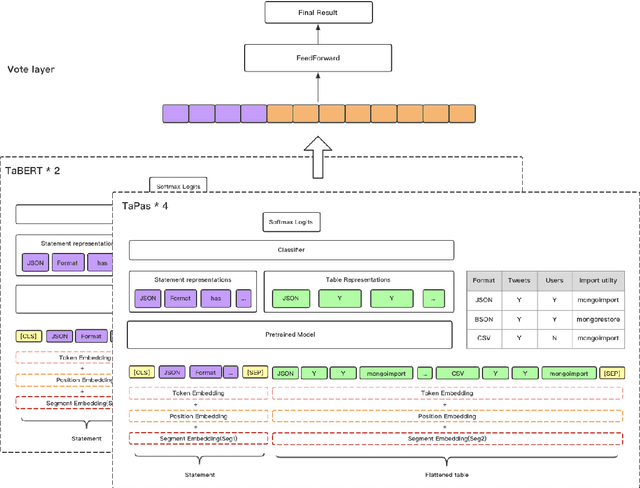
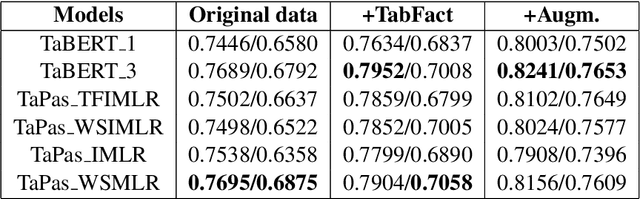
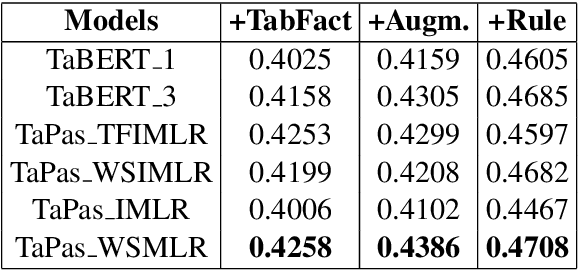
Question answering from semi-structured tables can be seen as a semantic parsing task and is significant and practical for pushing the boundary of natural language understanding. Existing research mainly focuses on understanding contents from unstructured evidence, e.g., news, natural language sentences, and documents. The task of verification from structured evidence, such as tables, charts, and databases, is still less explored. This paper describes sattiy team's system in SemEval-2021 task 9: Statement Verification and Evidence Finding with Tables (SEM-TAB-FACT). This competition aims to verify statements and to find evidence from tables for scientific articles and to promote the proper interpretation of the surrounding article. In this paper, we exploited ensemble models of pre-trained language models over tables, TaPas and TaBERT, for Task A and adjust the result based on some rules extracted for Task B. Finally, in the leaderboard, we attain the F1 scores of 0.8496 and 0.7732 in Task A for the 2-way and 3-way evaluation, respectively, and the F1 score of 0.4856 in Task B.
MagicPai at SemEval-2021 Task 7: Method for Detecting and Rating Humor Based on Multi-Task Adversarial Training
Apr 21, 2021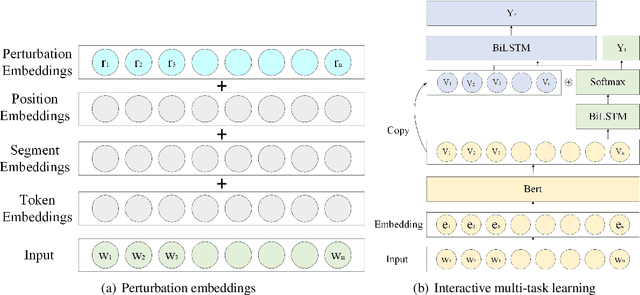
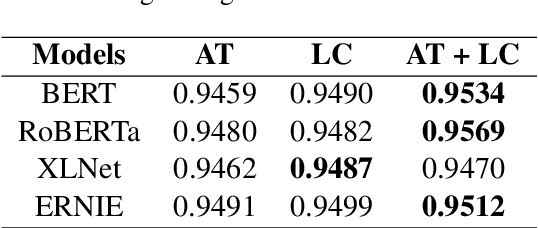
This paper describes MagicPai's system for SemEval 2021 Task 7, HaHackathon: Detecting and Rating Humor and Offense. This task aims to detect whether the text is humorous and how humorous it is. There are four subtasks in the competition. In this paper, we mainly present our solution, a multi-task learning model based on adversarial examples, for task 1a and 1b. More specifically, we first vectorize the cleaned dataset and add the perturbation to obtain more robust embedding representations. We then correct the loss via the confidence level. Finally, we perform interactive joint learning on multiple tasks to capture the relationship between whether the text is humorous and how humorous it is. The final result shows the effectiveness of our system.
* 7 pages, 1 figure, 4 tables