 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Supervised Fine-Tuning: Emphasizing Key Answer Tokens for Improved LLM Accuracy
Dec 24, 2025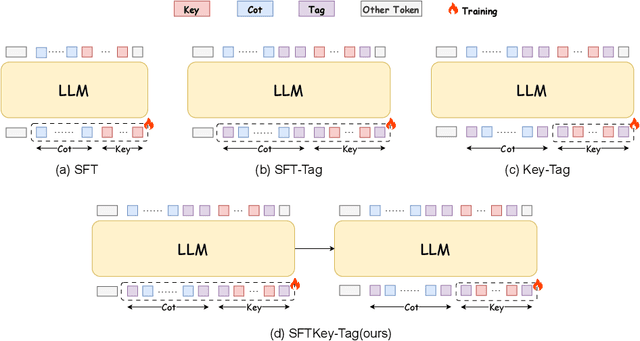
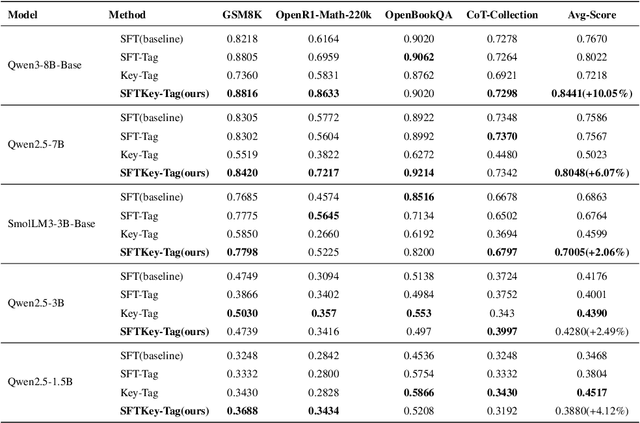
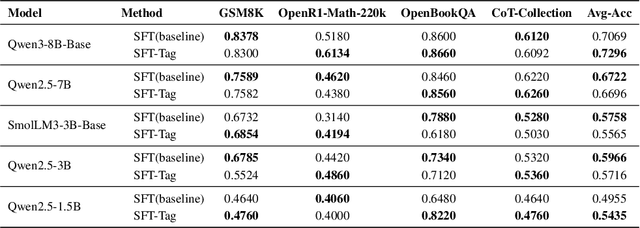
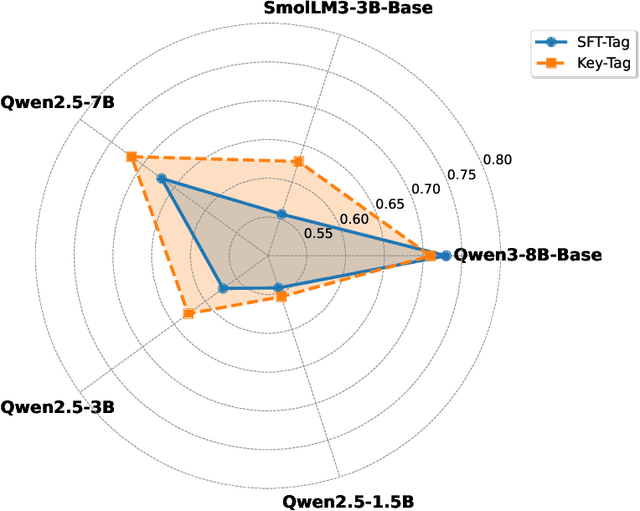
With the rapid advancement of Large Language Models (LLMs), the Chain-of-Thought (CoT) component has become significant for complex reasoning tasks. However, in conventional Supervised Fine-Tuning (SFT), the model could allocate disproportionately more attention to CoT sequences with excessive length. This reduces focus on the much shorter but essential Key portion-the final answer, whose correctness directly determines task success and evaluation quality. To address this limitation, we propose SFTKey, a two-stage training scheme. In the first stage, conventional SFT is applied to ensure proper output format, while in the second stage, only the Key portion is fine-tuned to improve accuracy. Extensive experiments across multiple benchmarks and model families demonstrate that SFTKey achieves an average accuracy improvement exceeding 5\% over conventional SFT, while preserving the ability to generate correct formats. Overall, this study advances LLM fine-tuning by explicitly balancing CoT learning with additional optimization on answer-relevant tokens.
SciSage: A Multi-Agent Framework for High-Quality Scientific Survey Generation
Jun 15, 2025The rapid growth of scientific literature demands robust tools for automated survey-generation. However, current large language model (LLM)-based methods often lack in-depth analysis, structural coherence, and reliable citations. To address these limitations, we introduce SciSage, a multi-agent framework employing a reflect-when-you-write paradigm. SciSage features a hierarchical Reflector agent that critically evaluates drafts at outline, section, and document levels, collaborating with specialized agents for query interpretation, content retrieval, and refinement. We also release SurveyScope, a rigorously curated benchmark of 46 high-impact papers (2020-2025) across 11 computer science domains, with strict recency and citation-based quality controls. Evaluations demonstrate that SciSage outperforms state-of-the-art baselines (LLM x MapReduce-V2, AutoSurvey), achieving +1.73 points in document coherence and +32% in citation F1 scores. Human evaluations reveal mixed outcomes (3 wins vs. 7 losses against human-written surveys), but highlight SciSage's strengths in topical breadth and retrieval efficiency. Overall, SciSage offers a promising foundation for research-assistive writing tools.
CareBot: A Pioneering Full-Process Open-Source Medical Language Model
Dec 23, 2024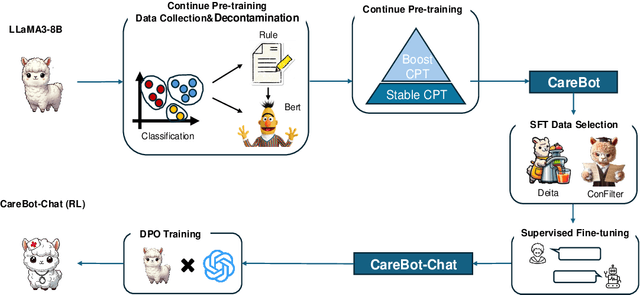
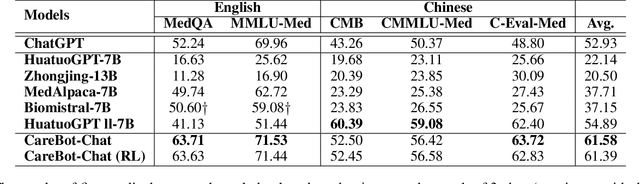
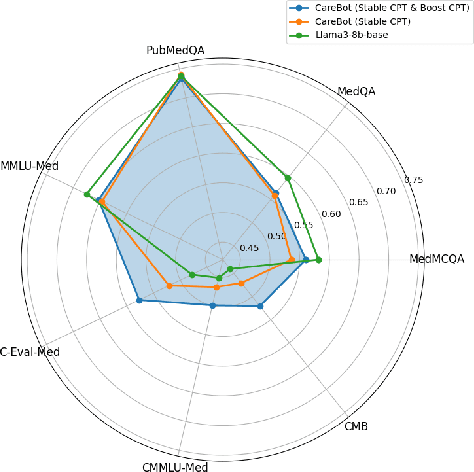
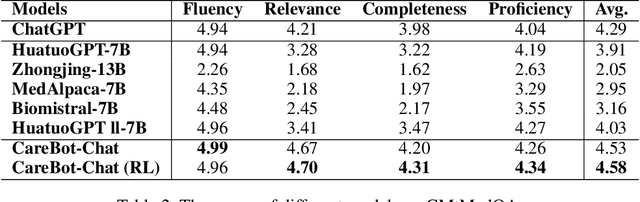
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional domains such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. In this paper, we propose CareBot, a bilingual medical LLM, which leverages a comprehensive approach integrating continuous pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning with human feedback (RLHF). Our novel two-stage CPT method, comprising Stable CPT and Boost CPT, effectively bridges the gap between general and domain-specific data, facilitating a smooth transition from pre-training to fine-tuning and enhancing domain knowledge progressively. We also introduce DataRater, a model designed to assess data quality during CPT, ensuring that the training data is both accurate and relevant. For SFT, we develope a large and diverse bilingual dataset, along with ConFilter, a metric to enhance multi-turn dialogue quality, which is crucial to improving the model's ability to handle more complex dialogues. The combination of high-quality data sources and innovative techniques significantly improves CareBot's performance across a range of medical applications. Our rigorous evaluations on Chinese and English benchmarks confirm CareBot's effectiveness in medical consultation and education. These advancements not only address current limitations in medical LLMs but also set a new standard for developing effective and reliable open-source models in the medical domain. We will open-source the datasets and models later, contributing valuable resources to the research community.
MoSLD: An Extremely Parameter-Efficient Mixture-of-Shared LoRAs for Multi-Task Learning
Dec 12, 2024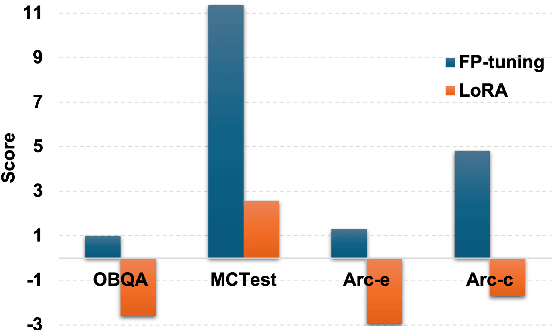


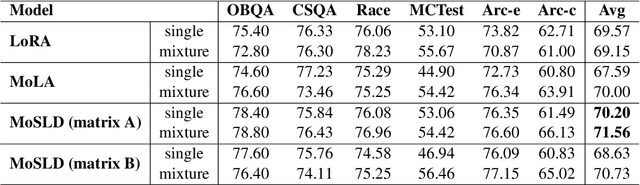
Recently, LoRA has emerged as a crucial technique for fine-tuning large pre-trained models, yet its performance in multi-task learning scenarios often falls short. In contrast, the MoE architecture presents a natural solution to this issue. However, it introduces challenges such as mutual interference of data across multiple domains and knowledge forgetting of various tasks. Additionally, MoE significantly increases the number of parameters, posing a computational cost challenge. Therefore, in this paper, we propose MoSLD, a mixture-of-shared-LoRAs model with a dropout strategy. MoSLD addresses these challenges by sharing the upper projection matrix in LoRA among different experts, encouraging the model to learn general knowledge across tasks, while still allowing the lower projection matrix to focus on the unique features of each task. The application of dropout alleviates the imbalanced update of parameter matrix and mitigates parameter overfitting in LoRA. Extensive experiments demonstrate that our model exhibits excellent performance in both single-task and multi-task scenarios, with robust out-of-domain generalization capabilities.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
Aqulia-Med LLM: Pioneering Full-Process Open-Source Medical Language Models
Jun 18, 2024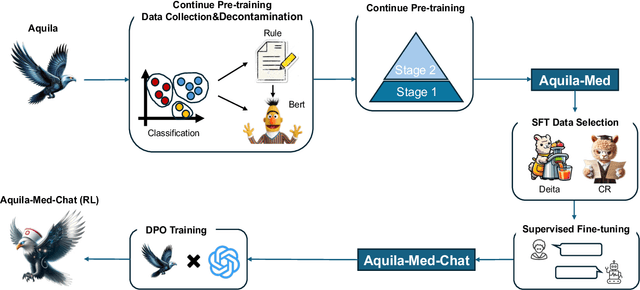

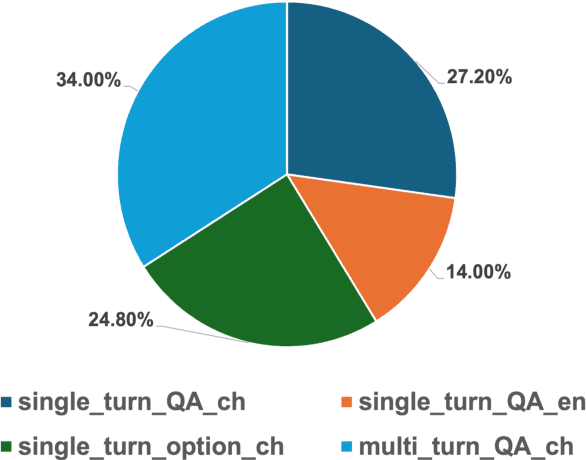
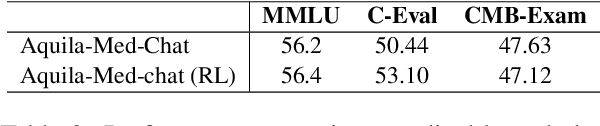
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional fields such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. We propose Aquila-Med, a bilingual medical LLM based on Aquila, addressing these challenges through continue pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF). We construct a large-scale Chinese and English medical dataset for continue pre-training and a high-quality SFT dataset, covering extensive medical specialties. Additionally, we develop a high-quality Direct Preference Optimization (DPO) dataset for further alignment. Aquila-Med achieves notable results across single-turn, multi-turn dialogues, and medical multiple-choice questions, demonstrating the effectiveness of our approach. We open-source the datasets and the entire training process, contributing valuable resources to the research community. Our models and datasets will released at https://huggingface.co/BAAI/AquilaMed-RL.
VarMAE: Pre-training of Variational Masked Autoencoder for Domain-adaptive Language Understanding
Nov 01, 2022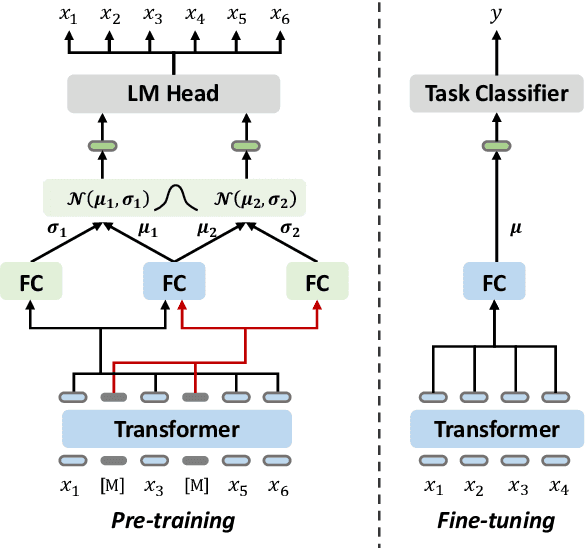
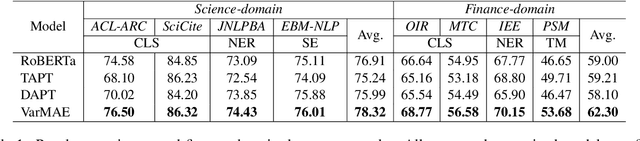

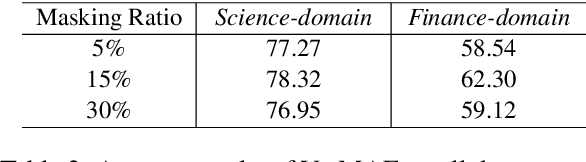
Pre-trained language models have achieved promising performance on general benchmarks, but underperform when migrated to a specific domain. Recent works perform pre-training from scratch or continual pre-training on domain corpora. However, in many specific domains, the limited corpus can hardly support obtaining precise representations. To address this issue, we propose a novel Transformer-based language model named VarMAE for domain-adaptive language understanding. Under the masked autoencoding objective, we design a context uncertainty learning module to encode the token's context into a smooth latent distribution. The module can produce diverse and well-formed contextual representations. Experiments on science- and finance-domain NLU tasks demonstrate that VarMAE can be efficiently adapted to new domains with limited resources.
PALI-NLP at SemEval-2022 Task 4: Discriminative Fine-tuning of Deep Transformers for Patronizing and Condescending Language Detection
Mar 09, 2022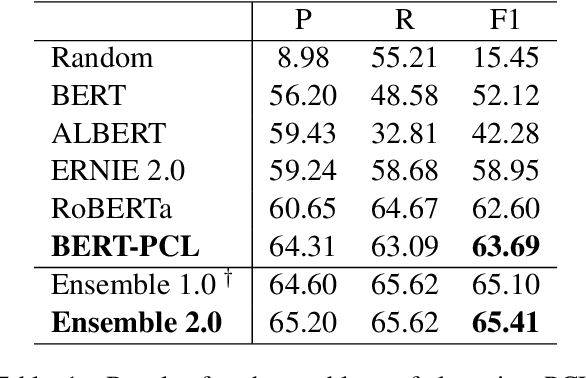
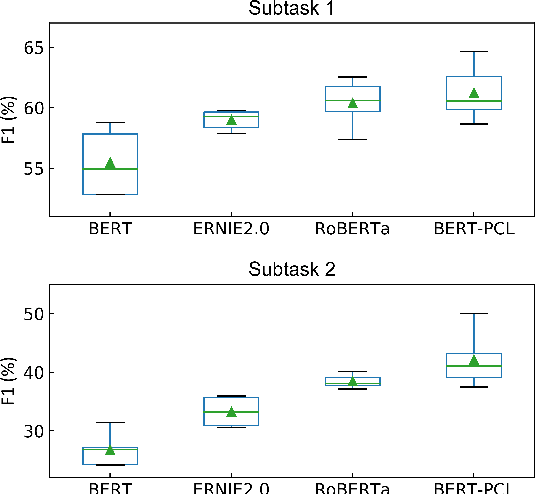
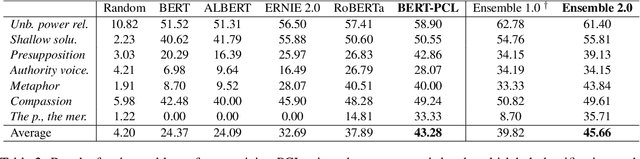
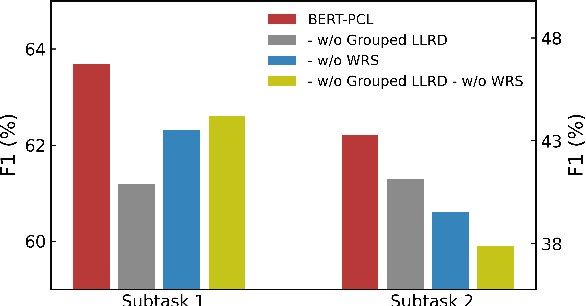
Patronizing and condescending language (PCL) has a large harmful impact and is difficult to detect, both for human judges and existing NLP systems. At SemEval-2022 Task 4, we propose a novel Transformer-based model and its ensembles to accurately understand such language context for PCL detection. To facilitate comprehension of the subtle and subjective nature of PCL, two fine-tuning strategies are applied to capture discriminative features from diverse linguistic behaviour and categorical distribution. The system achieves remarkable results on the official ranking, namely 1st in Subtask 1 and 5th in Subtask 2. Extensive experiments on the task demonstrate the effectiveness of our system and its strategies.