 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Multimodal Learning via Conformal Shapley Intervals
Jan 30, 2026Multimodal learning combines information from multiple data modalities to improve predictive performance. However, modalities often contribute unequally and in a data dependent way, making it unclear which data modalities are genuinely informative and to what extent their contributions can be trusted. Quantifying modality level importance together with uncertainty is therefore central to interpretable and reliable multimodal learning. We introduce conformal Shapley intervals, a framework that combines Shapley values with conformal inference to construct uncertainty-aware importance intervals for each modality. Building on these intervals, we propose a modality selection procedure with a provable optimality guarantee: conditional on the observed features, the selected subset of modalities achieves performance close to that of the optimal subset. We demonstrate the effectiveness of our approach on multiple datasets, showing that it provides meaningful uncertainty quantification and strong predictive performance while relying on only a small number of informative modalities.
ALIGN: Aligned Delegation with Performance Guarantees for Multi-Agent LLM Reasoning
Jan 28, 2026LLMs often underperform on complex reasoning tasks when relying on a single generation-and-selection pipeline. Inference-time ensemble methods can improve performance by sampling diverse reasoning paths or aggregating multiple candidate answers, but they typically treat candidates independently and provide no formal guarantees that ensembling improves reasoning quality. We propose a novel method, Aligned Delegation for Multi-Agent LLM Reasoning (ALIGN), which formulates LLM reasoning as an aligned delegation game. In ALIGN, a principal delegates a task to multiple agents that generate candidate solutions under designed incentives, and then selects among their outputs to produce a final answer. This formulation induces structured interaction among agents while preserving alignment between agent and principal objectives. We establish theoretical guarantees showing that, under a fair comparison with equal access to candidate solutions, ALIGN provably improves expected performance over single-agent generation. Our analysis accommodates correlated candidate answers and relaxes independence assumptions that are commonly used in prior work. Empirical results across a broad range of LLM reasoning benchmarks consistently demonstrate that ALIGN outperforms strong single-agent and ensemble baselines.
Rethinking Supervised Fine-Tuning: Emphasizing Key Answer Tokens for Improved LLM Accuracy
Dec 24, 2025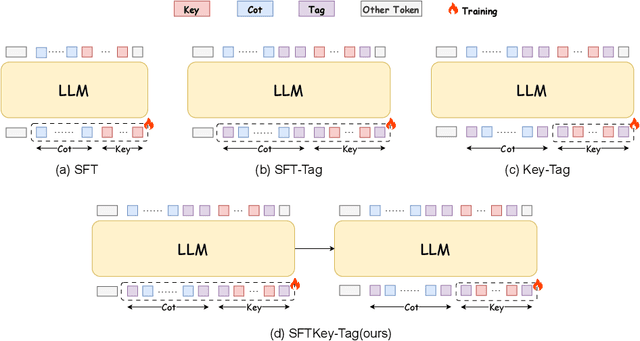
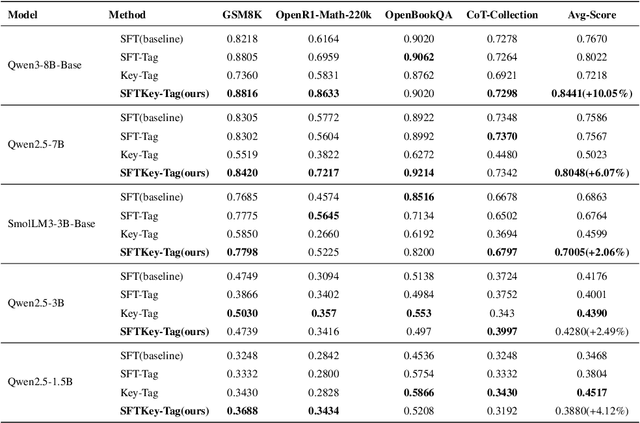
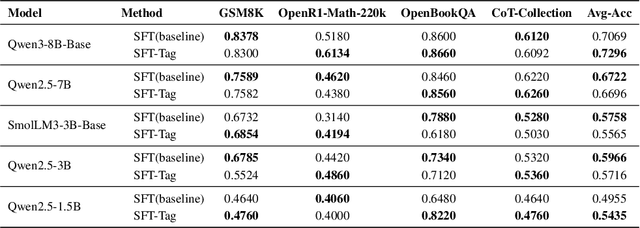
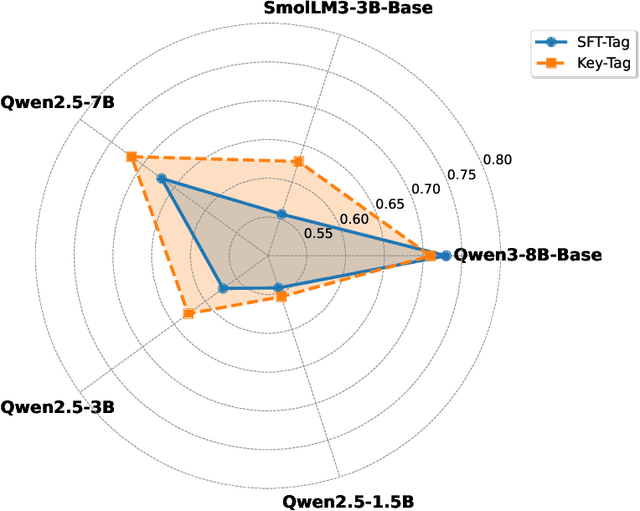
With the rapid advancement of Large Language Models (LLMs), the Chain-of-Thought (CoT) component has become significant for complex reasoning tasks. However, in conventional Supervised Fine-Tuning (SFT), the model could allocate disproportionately more attention to CoT sequences with excessive length. This reduces focus on the much shorter but essential Key portion-the final answer, whose correctness directly determines task success and evaluation quality. To address this limitation, we propose SFTKey, a two-stage training scheme. In the first stage, conventional SFT is applied to ensure proper output format, while in the second stage, only the Key portion is fine-tuned to improve accuracy. Extensive experiments across multiple benchmarks and model families demonstrate that SFTKey achieves an average accuracy improvement exceeding 5\% over conventional SFT, while preserving the ability to generate correct formats. Overall, this study advances LLM fine-tuning by explicitly balancing CoT learning with additional optimization on answer-relevant tokens.
Design, Results and Industry Implications of the World's First Insurance Large Language Model Evaluation Benchmark
Nov 11, 2025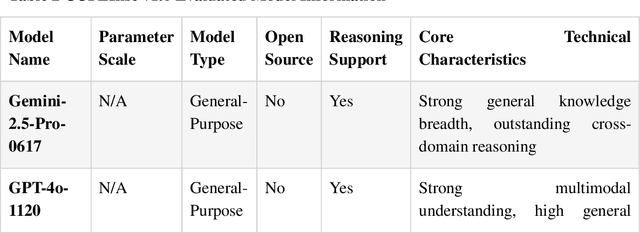
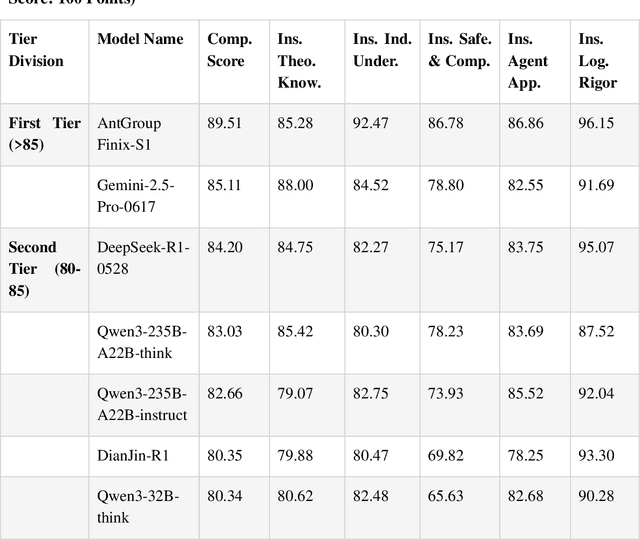
This paper comprehensively elaborates on the construction methodology, multi-dimensional evaluation system, and underlying design philosophy of CUFEInse v1.0. Adhering to the principles of "quantitative-oriented, expert-driven, and multi-validation," the benchmark establishes an evaluation framework covering 5 core dimensions, 54 sub-indicators, and 14,430 high-quality questions, encompassing insurance theoretical knowledge, industry understanding, safety and compliance, intelligent agent application, and logical rigor. Based on this benchmark, a comprehensive evaluation was conducted on 11 mainstream large language models. The evaluation results reveal that general-purpose models suffer from common bottlenecks such as weak actuarial capabilities and inadequate compliance adaptation. High-quality domain-specific training demonstrates significant advantages in insurance vertical scenarios but exhibits shortcomings in business adaptation and compliance. The evaluation also accurately identifies the common bottlenecks of current large models in professional scenarios such as insurance actuarial, underwriting and claim settlement reasoning, and compliant marketing copywriting. The establishment of CUFEInse not only fills the gap in professional evaluation benchmarks for the insurance field, providing academia and industry with a professional, systematic, and authoritative evaluation tool, but also its construction concept and methodology offer important references for the evaluation paradigm of large models in vertical fields, serving as an authoritative reference for academic model optimization and industrial model selection. Finally, the paper looks forward to the future iteration direction of the evaluation benchmark and the core development direction of "domain adaptation + reasoning enhancement" for insurance large models.
SciSage: A Multi-Agent Framework for High-Quality Scientific Survey Generation
Jun 15, 2025The rapid growth of scientific literature demands robust tools for automated survey-generation. However, current large language model (LLM)-based methods often lack in-depth analysis, structural coherence, and reliable citations. To address these limitations, we introduce SciSage, a multi-agent framework employing a reflect-when-you-write paradigm. SciSage features a hierarchical Reflector agent that critically evaluates drafts at outline, section, and document levels, collaborating with specialized agents for query interpretation, content retrieval, and refinement. We also release SurveyScope, a rigorously curated benchmark of 46 high-impact papers (2020-2025) across 11 computer science domains, with strict recency and citation-based quality controls. Evaluations demonstrate that SciSage outperforms state-of-the-art baselines (LLM x MapReduce-V2, AutoSurvey), achieving +1.73 points in document coherence and +32% in citation F1 scores. Human evaluations reveal mixed outcomes (3 wins vs. 7 losses against human-written surveys), but highlight SciSage's strengths in topical breadth and retrieval efficiency. Overall, SciSage offers a promising foundation for research-assistive writing tools.
Learn then Decide: A Learning Approach for Designing Data Marketplaces
Mar 13, 2025



As data marketplaces become increasingly central to the digital economy, it is crucial to design efficient pricing mechanisms that optimize revenue while ensuring fair and adaptive pricing. We introduce the Maximum Auction-to-Posted Price (MAPP) mechanism, a novel two-stage approach that first estimates the bidders' value distribution through auctions and then determines the optimal posted price based on the learned distribution. We establish that MAPP is individually rational and incentive-compatible, ensuring truthful bidding while balancing revenue maximization with minimal price discrimination. MAPP achieves a regret of $O_p(n^{-1})$ when incorporating historical bid data, where $n$ is the number of bids in the current round. It outperforms existing methods while imposing weaker distributional assumptions. For sequential dataset sales over $T$ rounds, we propose an online MAPP mechanism that dynamically adjusts pricing across datasets with varying value distributions. Our approach achieves no-regret learning, with the average cumulative regret converging at a rate of $O_p(T^{-1/2}(\log T)^2)$. We validate the effectiveness of MAPP through simulations and real-world data from the FCC AWS-3 spectrum auction.
OptMetaOpenFOAM: Large Language Model Driven Chain of Thought for Sensitivity Analysis and Parameter Optimization based on CFD
Mar 03, 2025Merging natural language interfaces with computational fluid dynamics (CFD) workflows presents transformative opportunities for both industry and research. In this study, we introduce OptMetaOpenFOAM - a novel framework that bridges MetaOpenFOAM with external analysis and optimization tool libraries through a large language model (LLM)-driven chain-of-thought (COT) methodology. By automating complex CFD tasks via natural language inputs, the framework empowers non-expert users to perform sensitivity analyses and parameter optimizations with markedly improved efficiency. The test dataset comprises 11 distinct CFD analysis or optimization tasks, including a baseline simulation task derived from an OpenFOAM tutorial covering fluid dynamics, combustion, and heat transfer. Results confirm that OptMetaOpenFOAM can accurately interpret user requirements expressed in natural language and effectively invoke external tool libraries alongside MetaOpenFOAM to complete the tasks. Furthermore, validation on a non-OpenFOAM tutorial case - namely, a hydrogen combustion chamber - demonstrates that a mere 200-character natural language input can trigger a sequence of simulation, postprocessing, analysis, and optimization tasks spanning over 2,000 lines of code. These findings underscore the transformative potential of LLM-driven COT methodologies in linking external tool for advanced analysis and optimization, positioning OptMetaOpenFOAM as an effective tool that streamlines CFD simulations and enhances their convenience and efficiency for both industrial and research applications. Code is available at https://github.com/Terry-cyx/MetaOpenFOAM.
A Semiparametric Bayesian Method for Instrumental Variable Analysis with Partly Interval-Censored Time-to-Event Outcome
Jan 23, 2025



This paper develops a semiparametric Bayesian instrumental variable analysis method for estimating the causal effect of an endogenous variable when dealing with unobserved confounders and measurement errors with partly interval-censored time-to-event data, where event times are observed exactly for some subjects but left-censored, right-censored, or interval-censored for others. Our method is based on a two-stage Dirichlet process mixture instrumental variable (DPMIV) model which simultaneously models the first-stage random error term for the exposure variable and the second-stage random error term for the time-to-event outcome using a bivariate Gaussian mixture of the Dirichlet process (DPM) model. The DPM model can be broadly understood as a mixture model with an unspecified number of Gaussian components, which relaxes the normal error assumptions and allows the number of mixture components to be determined by the data. We develop an MCMC algorithm for the DPMIV model tailored for partly interval-censored data and conduct extensive simulations to assess the performance of our DPMIV method in comparison with some competing methods. Our simulations revealed that our proposed method is robust under different error distributions and can have superior performance over its parametric counterpart under various scenarios. We further demonstrate the effectiveness of our approach on an UK Biobank data to investigate the causal effect of systolic blood pressure on time-to-development of cardiovascular disease from the onset of diabetes mellitus.
CareBot: A Pioneering Full-Process Open-Source Medical Language Model
Dec 23, 2024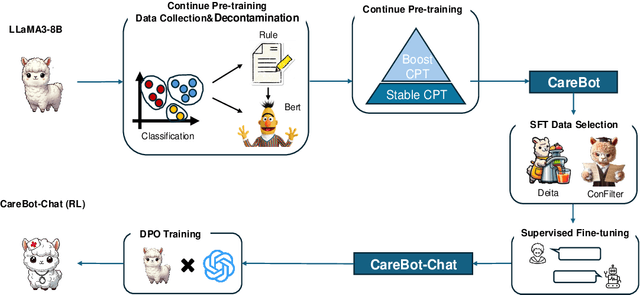
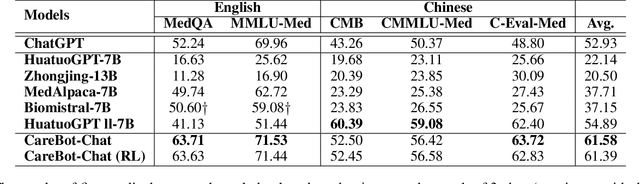
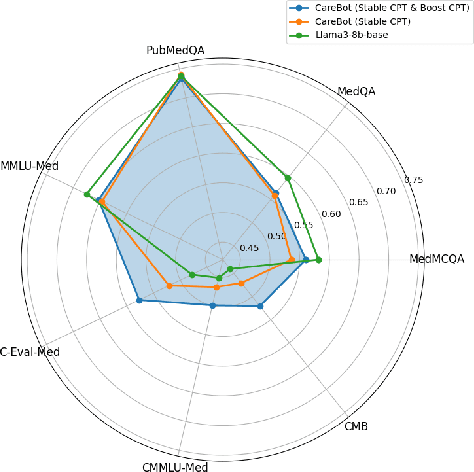
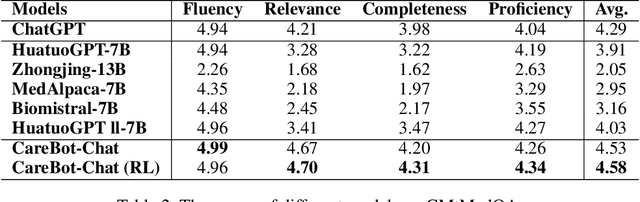
Recently, both closed-source LLMs and open-source communities have made significant strides, outperforming humans in various general domains. However, their performance in specific professional domains such as medicine, especially within the open-source community, remains suboptimal due to the complexity of medical knowledge. In this paper, we propose CareBot, a bilingual medical LLM, which leverages a comprehensive approach integrating continuous pre-training (CPT), supervised fine-tuning (SFT), and reinforcement learning with human feedback (RLHF). Our novel two-stage CPT method, comprising Stable CPT and Boost CPT, effectively bridges the gap between general and domain-specific data, facilitating a smooth transition from pre-training to fine-tuning and enhancing domain knowledge progressively. We also introduce DataRater, a model designed to assess data quality during CPT, ensuring that the training data is both accurate and relevant. For SFT, we develope a large and diverse bilingual dataset, along with ConFilter, a metric to enhance multi-turn dialogue quality, which is crucial to improving the model's ability to handle more complex dialogues. The combination of high-quality data sources and innovative techniques significantly improves CareBot's performance across a range of medical applications. Our rigorous evaluations on Chinese and English benchmarks confirm CareBot's effectiveness in medical consultation and education. These advancements not only address current limitations in medical LLMs but also set a new standard for developing effective and reliable open-source models in the medical domain. We will open-source the datasets and models later, contributing valuable resources to the research community.
Smaller Language Models Are Better Instruction Evolvers
Dec 15, 2024



Instruction tuning has been widely used to unleash the complete potential of large language models. Notably, complex and diverse instructions are of significant importance as they can effectively align models with various downstream tasks. However, current approaches to constructing large-scale instructions predominantly favour powerful models such as GPT-4 or those with over 70 billion parameters, under the empirical presumption that such larger language models (LLMs) inherently possess enhanced capabilities. In this study, we question this prevalent assumption and conduct an in-depth exploration into the potential of smaller language models (SLMs) in the context of instruction evolution. Extensive experiments across three scenarios of instruction evolution reveal that smaller language models (SLMs) can synthesize more effective instructions than LLMs. Further analysis demonstrates that SLMs possess a broader output space during instruction evolution, resulting in more complex and diverse variants. We also observe that the existing metrics fail to focus on the impact of the instructions. Thus, we propose Instruction Complex-Aware IFD (IC-IFD), which introduces instruction complexity in the original IFD score to evaluate the effectiveness of instruction data more accurately. Our source code is available at: \href{https://github.com/HypherX/Evolution-Analysis}{https://github.com/HypherX/Evolution-Analysis}