 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDA-Net: Accurate TDD Channel Estimation via Deep Unfolding the Doppler-Delay-Angle Representation of Channel Signals
Apr 07, 2026In TDD massive MIMO systems, channel estimation under sparse frequency-hopping pilots is challenging: each snapshot captures only one narrow pilot block that hops across frequency, with tens of milliseconds between adjacent snapshots. Finite-window leakage and off-grid effects weaken the ideal Doppler-delay-angle (DDA) sparsity, limiting both classical sparse recovery and purely data-driven approaches lacking an explicit structured transform-domain model. We propose DDA-Net, a model-driven 3D deep unfolding network for joint multi-snapshot channel state reconstruction. DDA-Net unfolds an ADMM formulation with an exact closed-form data-consistency update that avoids tensor inversion, learns the prior via a lightweight Doppler-domain denoiser, and uses delay oversampling to reduce basis mismatch. On QuaDRiGa UMa-NLOS, DDA-Net improves NMSE over the best baseline by more than 5 dB at 10 dB SNR, and retains a lead of about 1.5 dB under zero-shot testing on 3GPP CDL-B channels at the same SNR. Ablation studies show that window-level 3D processing is necessary across scenarios, while Doppler parameterization adds in-distribution gains and recovers a clear lead under scenario shift after few-shot fine-tuning with only 20 target-domain samples. These results demonstrate that combining exact physical data consistency with a learned DDA-domain prior is an effective and sample-efficient approach to channel state acquisition under sparse frequency-hopping pilots.
Covering-radius and Collinearity- Minimizing Pilots for Channel Estimation in TDD Systems
Apr 07, 2026This letter studies pilot design for orthogonal frequency-division multiplexing-based time-division duplex (TDD) systems under a sliding-window latest-slot recovery framework that jointly exploits delay--Doppler sparsity across recent slots. Under contiguous-subband and fairness constraints, this viewpoint naturally leads to a geometry-aware time--frequency joint pilot assignment. We show that effective patterns should balance grid coverage and redundant-collinearity suppression, with an additional symmetry-avoidance refinement when complete collinearity elimination is infeasible. Based on these principles, we formulate a mixed-integer construction method compatible with practical TDD allocation. Numerical results show that minimum-coverage-radius and collinearity-control (MCC) pattern improves both surrogate geometry metrics and latest-slot recovery performance.
Toward Robust Semantic Communications: Proactive Importance-Ordered Restructuring for Enhanced Unequal Error Protection
Apr 01, 2026Semantic communications (SemCom) is a promising task-oriented paradigm in which semantic features exhibit non-uniform importance. Consequently, unequal error protection (UEP), which allocates resources based on semantic importance, plays a pivotal role in maximizing system utility. However, most existing schemes adopt passive importance evaluation, which neither proactively reshapes the importance distribution nor explores its impact on UEP performance. In this paper, we propose a novel importance-ordered semantic feature restructuring (ISFR) scheme that proactively enforces a descending importance hierarchy and jointly optimizes multi-dimensional resources to improve system utility. Specifically, modules with decreasing retention probabilities and increasing distortion levels are employed, which drive the model to concentrate key semantics into front-end features and thus strengthen importance differentiation. Moreover, a joint optimization problem that jointly optimizes channel matching, feature selection, modulation schemes, and power allocation is formulated to minimize the importance-weighted total semantic distortion. To solve this non-convex problem, a hierarchical decoupling strategy is proposed, which decomposes it into four tractable subproblems. This approach leverages the ordered prior to drastically prune the search space for feature selection and modulation, while integrating greedy-based channel matching and convex power allocation. Simulation results demonstrate that the proposed ISFR scheme outperforms traditional uniform importance-based schemes under harsh channel conditions and limited resources, validating the significant robustness improvement enabled by the concentration of key semantic information.
Modulation Symbol Pulse Shaping Transceiver for Affine Frequency Division Multiplexing
Mar 18, 2026The recently proposed affine frequency division multiplexing (AFDM) waveform can adjust the time-frequency diversity gain by tuning chirp-rate parameter. Therefore, it is a candidate waveform in doubly-selective channels. This letter reveals that the modulation-symbol-domain shaping pulse of AFDM is generated by a convolution-like operation between the time-domain and frequency-domain shaping pulses, indicating that the modulation-symbol-domain pulse shaping of AFDM can be achieved by separately shaping in the time domain and frequency domain. Based on this, this letter presents an AFDM modulation-symbol-domain pulse shaping transceiver which has an ability to achieve the Nyquist pulse shaping, and provides the corresponding input-output relationship. Numerical results demonstrate the effectiveness of the proposed transceiver in improving the channel sparsity and pilot-to-data interference.
Low-Complexity Sparse Superimposed Coding for Ultra Reliable Low Latency Communications
Jan 22, 2026Sparse superimposed coding (SSC) has emerged as a promising technique for short-packet transmission in ultra-reliable low-latency communication scenarios. However, conventional SSC schemes often suffer from high encoding and decoding complexity due to the use of dense codebook matrices. In this paper, we propose a low-complexity SSC scheme by designing a sparse codebook structure, where each codeword contains only a small number of non-zero elements. The decoding is performed using the traditional multipath matching pursuit algorithm, and the overall complexity is significantly reduced by exploiting the sparsity of the codebook. Simulation results show that the proposed scheme achieves a favorable trade-off between BLER performance and computational complexity, and exhibits strong robustness across different transmission block lengths.
Dual-Mapping Sparse Vector Transmission for Short Packet URLLC
Jan 22, 2026Sparse vector coding (SVC) is a promising short-packet transmission method for ultra reliable low latency communication (URLLC) in next generation communication systems. In this paper, a dual-mapping SVC (DM-SVC) based short packet transmission scheme is proposed to further enhance the transmission performance of SVC. The core idea behind the proposed scheme lies in mapping the transmitted information bits onto sparse vectors via block and single-element sparse mappings. The block sparse mapping pattern is able to concentrate the transmit power in a small number of non-zero blocks thus improving the decoding accuracy, while the single-element sparse mapping pattern ensures that the code length does not increase dramatically with the number of transmitted information bits. At the receiver, a two-stage decoding algorithm is proposed to sequentially identify non-zero block indexes and single-element non-zero indexes. Extensive simulation results verify that proposed DM-SVC scheme outperforms the existing SVC schemes in terms of block error rate and spectral efficiency.
Hierarchical Sparse Vector Transmission for Ultra Reliable and Low Latency Communications
Jan 19, 2026Sparse vector transmission (SVT) is a promising candidate technology for achieving ultra-reliable low-latency communication (URLLC). In this paper, a hierarchical SVT scheme is proposed for multi-user URLLC scenarios. The hierarchical SVT scheme partitions the transmitted bits into common and private parts. The common information is conveyed by the indices of non-zero sections in a sparse vector, while each user's private information is embedded into non-zero blocks with specific block lengths. At the receiver, the common bits are first recovered from the detected non-zero sections, followed by user-specific private bits decoding based on the corresponding non-zero block indices. Simulation results show the proposed scheme outperforms state-of-the-art SVT schemes in terms of block error rate.
OMUDA: Omni-level Masking for Unsupervised Domain Adaptation in Semantic Segmentation
Dec 13, 2025Unsupervised domain adaptation (UDA) enables semantic segmentation models to generalize from a labeled source domain to an unlabeled target domain. However, existing UDA methods still struggle to bridge the domain gap due to cross-domain contextual ambiguity, inconsistent feature representations, and class-wise pseudo-label noise. To address these challenges, we propose Omni-level Masking for Unsupervised Domain Adaptation (OMUDA), a unified framework that introduces hierarchical masking strategies across distinct representation levels. Specifically, OMUDA comprises: 1) a Context-Aware Masking (CAM) strategy that adaptively distinguishes foreground from background to balance global context and local details; 2) a Feature Distillation Masking (FDM) strategy that enhances robust and consistent feature learning through knowledge transfer from pre-trained models; and 3) a Class Decoupling Masking (CDM) strategy that mitigates the impact of noisy pseudo-labels by explicitly modeling class-wise uncertainty. This hierarchical masking paradigm effectively reduces the domain shift at the contextual, representational, and categorical levels, providing a unified solution beyond existing approaches. Extensive experiments on multiple challenging cross-domain semantic segmentation benchmarks validate the effectiveness of OMUDA. Notably, on the SYNTHIA->Cityscapes and GTA5->Cityscapes tasks, OMUDA can be seamlessly integrated into existing UDA methods and consistently achieving state-of-the-art results with an average improvement of 7%.
Basis Expansion Extrapolation based Long-Term Channel Prediction for Massive MIMO OTFS Systems
Jul 02, 2025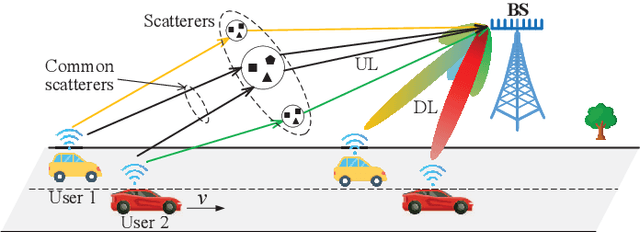
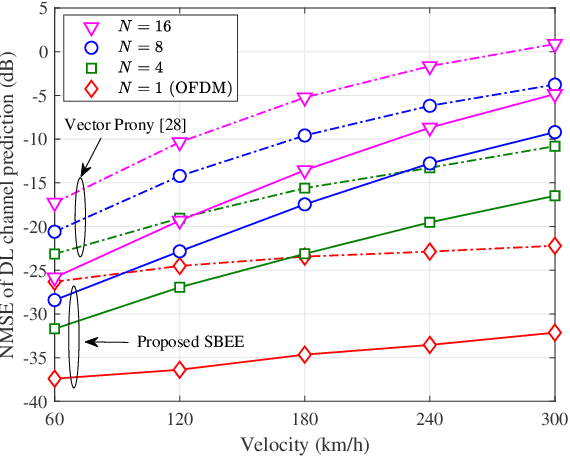
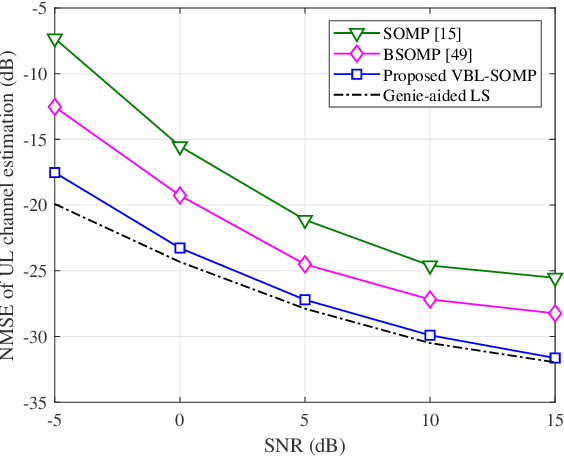
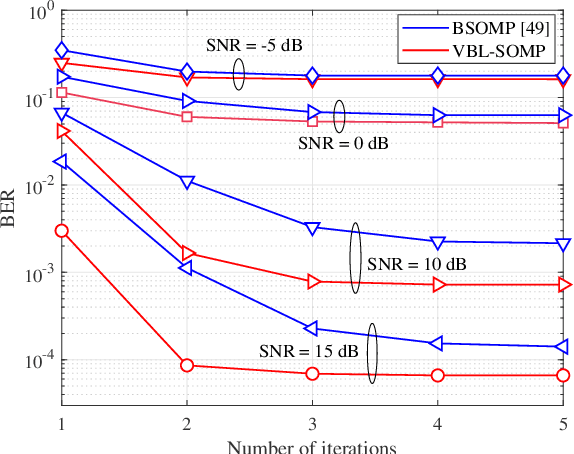
Massive multi-input multi-output (MIMO) combined with orthogonal time frequency space (OTFS) modulation has emerged as a promising technique for high-mobility scenarios. However, its performance could be severely degraded due to channel aging caused by user mobility and high processing latency. In this paper, an integrated scheme of uplink (UL) channel estimation and downlink (DL) channel prediction is proposed to alleviate channel aging in time division duplex (TDD) massive MIMO-OTFS systems. Specifically, first, an iterative basis expansion model (BEM) based UL channel estimation scheme is proposed to accurately estimate UL channels with the aid of carefully designed OTFS frame pattern. Then a set of Slepian sequences are used to model the estimated UL channels, and the dynamic Slepian coefficients are fitted by a set of orthogonal polynomials. A channel predictor is derived to predict DL channels by iteratively extrapolating the Slepian coefficients. Simulation results verify that the proposed UL channel estimation and DL channel prediction schemes outperform the existing schemes in terms of normalized mean square error of channel estimation/prediction and DL spectral efficiency, with less pilot overhead.
Multi-Reference and Adaptive Nonlinear Transform Source-Channel Coding for Wireless Image Semantic Transmission
May 19, 2025We propose a multi-reference and adaptive nonlinear transform source-channel coding (MA-NTSCC) system for wireless image semantic transmission to improve rate-distortion (RD) performance by introducing multi-dimensional contexts into the entropy model of the state-of-the-art (SOTA) NTSCC system. Improvements in RD performance of the proposed MA-NTSCC system are particularly significant in high-resolution image transmission under low bandwidth constraints. The proposed multi-reference entropy model leverages correlations within the latent representation in both spatial and channel dimensions. In the spatial dimension, the latent representation is divided into anchors and non-anchors in a checkerboard pattern, where anchors serve as reference to estimate the mutual information between anchors and non-anchors. In the channel dimension, the latent representation is partitioned into multiple groups, and features in previous groups are analyzed to estimate the mutual information between features in previous and current groups. Taking mutual information into account, the entropy model provides an accurate estimation on the entropy, which enables efficient bandwidth allocation and enhances RD performance. Additionally, the proposed lightweight adaptation modules enable the proposed MA-NTSCC model to achieve transmission quality comparable to separately trained models across various channel conditions and bandwidth requirements. In contrast, traditional NTSCC models provide signal-to-noise ratio (SNR)-distortion performance degrading with channel quality deviating from the fixed training SNR, and consume inflexible bandwidth to transmit an image. Comprehensive experiments are conducted to verify the peak signal-to-noise ratio (PSNR) performance and adaptability of the proposed MA-NTSCC model superior to SOTA methods over both additive white Gaussian noise channel and Rayleigh fading channel.