 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierLoc: Hyperbolic Entity Embeddings for Hierarchical Visual Geolocation
Jan 30, 2026Visual geolocalization, the task of predicting where an image was taken, remains challenging due to global scale, visual ambiguity, and the inherently hierarchical structure of geography. Existing paradigms rely on either large-scale retrieval, which requires storing a large number of image embeddings, grid-based classifiers that ignore geographic continuity, or generative models that diffuse over space but struggle with fine detail. We introduce an entity-centric formulation of geolocation that replaces image-to-image retrieval with a compact hierarchy of geographic entities embedded in Hyperbolic space. Images are aligned directly to country, region, subregion, and city entities through Geo-Weighted Hyperbolic contrastive learning by directly incorporating haversine distance into the contrastive objective. This hierarchical design enables interpretable predictions and efficient inference with 240k entity embeddings instead of over 5 million image embeddings on the OSV5M benchmark, on which our method establishes a new state-of-the-art performance. Compared to the current methods in the literature, it reduces mean geodesic error by 19.5\%, while improving the fine-grained subregion accuracy by 43%. These results demonstrate that geometry-aware hierarchical embeddings provide a scalable and conceptually new alternative for global image geolocation.
Low-Complexity Sparse Superimposed Coding for Ultra Reliable Low Latency Communications
Jan 22, 2026Sparse superimposed coding (SSC) has emerged as a promising technique for short-packet transmission in ultra-reliable low-latency communication scenarios. However, conventional SSC schemes often suffer from high encoding and decoding complexity due to the use of dense codebook matrices. In this paper, we propose a low-complexity SSC scheme by designing a sparse codebook structure, where each codeword contains only a small number of non-zero elements. The decoding is performed using the traditional multipath matching pursuit algorithm, and the overall complexity is significantly reduced by exploiting the sparsity of the codebook. Simulation results show that the proposed scheme achieves a favorable trade-off between BLER performance and computational complexity, and exhibits strong robustness across different transmission block lengths.
Dual-Mapping Sparse Vector Transmission for Short Packet URLLC
Jan 22, 2026Sparse vector coding (SVC) is a promising short-packet transmission method for ultra reliable low latency communication (URLLC) in next generation communication systems. In this paper, a dual-mapping SVC (DM-SVC) based short packet transmission scheme is proposed to further enhance the transmission performance of SVC. The core idea behind the proposed scheme lies in mapping the transmitted information bits onto sparse vectors via block and single-element sparse mappings. The block sparse mapping pattern is able to concentrate the transmit power in a small number of non-zero blocks thus improving the decoding accuracy, while the single-element sparse mapping pattern ensures that the code length does not increase dramatically with the number of transmitted information bits. At the receiver, a two-stage decoding algorithm is proposed to sequentially identify non-zero block indexes and single-element non-zero indexes. Extensive simulation results verify that proposed DM-SVC scheme outperforms the existing SVC schemes in terms of block error rate and spectral efficiency.
Hierarchical Sparse Vector Transmission for Ultra Reliable and Low Latency Communications
Jan 19, 2026Sparse vector transmission (SVT) is a promising candidate technology for achieving ultra-reliable low-latency communication (URLLC). In this paper, a hierarchical SVT scheme is proposed for multi-user URLLC scenarios. The hierarchical SVT scheme partitions the transmitted bits into common and private parts. The common information is conveyed by the indices of non-zero sections in a sparse vector, while each user's private information is embedded into non-zero blocks with specific block lengths. At the receiver, the common bits are first recovered from the detected non-zero sections, followed by user-specific private bits decoding based on the corresponding non-zero block indices. Simulation results show the proposed scheme outperforms state-of-the-art SVT schemes in terms of block error rate.
GeoSceneGraph: Geometric Scene Graph Diffusion Model for Text-guided 3D Indoor Scene Synthesis
Nov 18, 2025Methods that synthesize indoor 3D scenes from text prompts have wide-ranging applications in film production, interior design, video games, virtual reality, and synthetic data generation for training embodied agents. Existing approaches typically either train generative models from scratch or leverage vision-language models (VLMs). While VLMs achieve strong performance, particularly for complex or open-ended prompts, smaller task-specific models remain necessary for deployment on resource-constrained devices such as extended reality (XR) glasses or mobile phones. However, many generative approaches that train from scratch overlook the inherent graph structure of indoor scenes, which can limit scene coherence and realism. Conversely, methods that incorporate scene graphs either demand a user-provided semantic graph, which is generally inconvenient and restrictive, or rely on ground-truth relationship annotations, limiting their capacity to capture more varied object interactions. To address these challenges, we introduce GeoSceneGraph, a method that synthesizes 3D scenes from text prompts by leveraging the graph structure and geometric symmetries of 3D scenes, without relying on predefined relationship classes. Despite not using ground-truth relationships, GeoSceneGraph achieves performance comparable to methods that do. Our model is built on equivariant graph neural networks (EGNNs), but existing EGNN approaches are typically limited to low-dimensional conditioning and are not designed to handle complex modalities such as text. We propose a simple and effective strategy for conditioning EGNNs on text features, and we validate our design through ablation studies.
LADB: Latent Aligned Diffusion Bridges for Semi-Supervised Domain Translation
Sep 10, 2025Diffusion models excel at generating high-quality outputs but face challenges in data-scarce domains, where exhaustive retraining or costly paired data are often required. To address these limitations, we propose Latent Aligned Diffusion Bridges (LADB), a semi-supervised framework for sample-to-sample translation that effectively bridges domain gaps using partially paired data. By aligning source and target distributions within a shared latent space, LADB seamlessly integrates pretrained source-domain diffusion models with a target-domain Latent Aligned Diffusion Model (LADM), trained on partially paired latent representations. This approach enables deterministic domain mapping without the need for full supervision. Compared to unpaired methods, which often lack controllability, and fully paired approaches that require large, domain-specific datasets, LADB strikes a balance between fidelity and diversity by leveraging a mixture of paired and unpaired latent-target couplings. Our experimental results demonstrate superior performance in depth-to-image translation under partial supervision. Furthermore, we extend LADB to handle multi-source translation (from depth maps and segmentation masks) and multi-target translation in a class-conditioned style transfer task, showcasing its versatility in handling diverse and heterogeneous use cases. Ultimately, we present LADB as a scalable and versatile solution for real-world domain translation, particularly in scenarios where data annotation is costly or incomplete.
MeSS: City Mesh-Guided Outdoor Scene Generation with Cross-View Consistent Diffusion
Aug 21, 2025Mesh models have become increasingly accessible for numerous cities; however, the lack of realistic textures restricts their application in virtual urban navigation and autonomous driving. To address this, this paper proposes MeSS (Meshbased Scene Synthesis) for generating high-quality, styleconsistent outdoor scenes with city mesh models serving as the geometric prior. While image and video diffusion models can leverage spatial layouts (such as depth maps or HD maps) as control conditions to generate street-level perspective views, they are not directly applicable to 3D scene generation. Video diffusion models excel at synthesizing consistent view sequences that depict scenes but often struggle to adhere to predefined camera paths or align accurately with rendered control videos. In contrast, image diffusion models, though unable to guarantee cross-view visual consistency, can produce more geometry-aligned results when combined with ControlNet. Building on this insight, our approach enhances image diffusion models by improving cross-view consistency. The pipeline comprises three key stages: first, we generate geometrically consistent sparse views using Cascaded Outpainting ControlNets; second, we propagate denser intermediate views via a component dubbed AGInpaint; and third, we globally eliminate visual inconsistencies (e.g., varying exposure) using the GCAlign module. Concurrently with generation, a 3D Gaussian Splatting (3DGS) scene is reconstructed by initializing Gaussian balls on the mesh surface. Our method outperforms existing approaches in both geometric alignment and generation quality. Once synthesized, the scene can be rendered in diverse styles through relighting and style transfer techniques.
Basis Expansion Extrapolation based Long-Term Channel Prediction for Massive MIMO OTFS Systems
Jul 02, 2025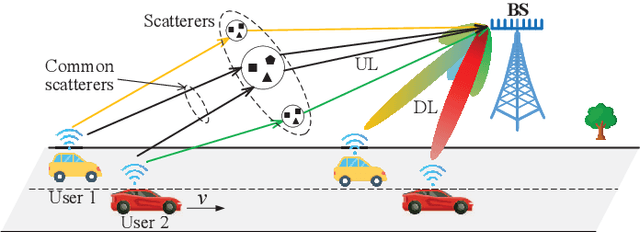
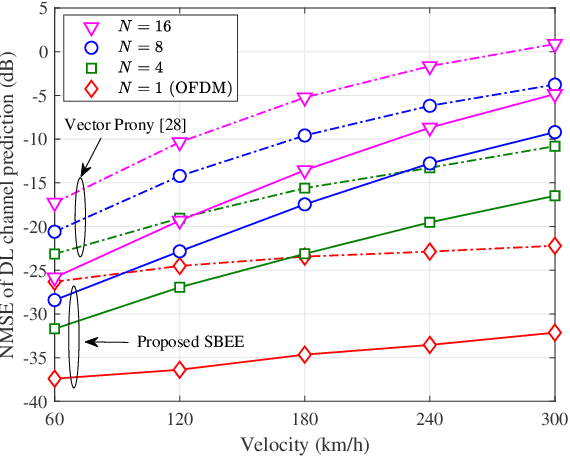
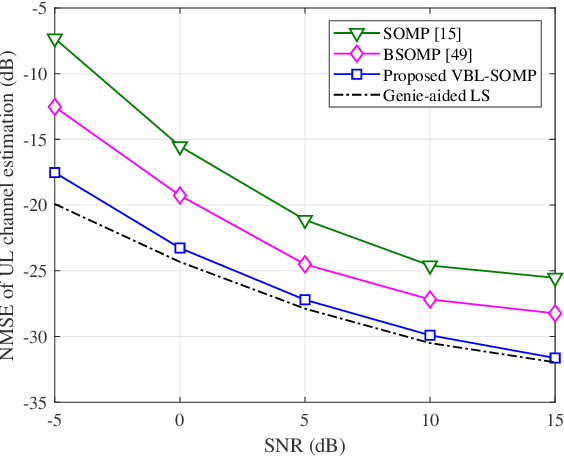
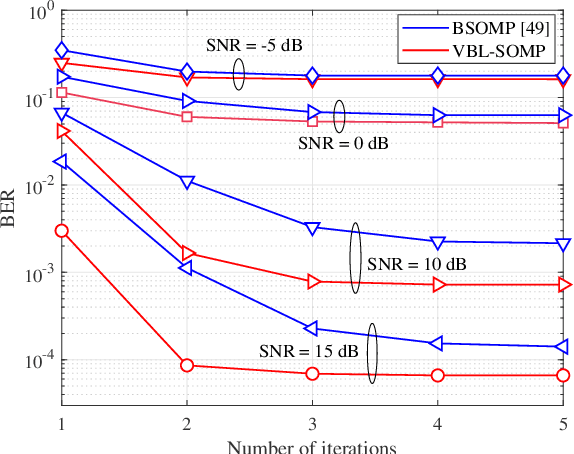
Massive multi-input multi-output (MIMO) combined with orthogonal time frequency space (OTFS) modulation has emerged as a promising technique for high-mobility scenarios. However, its performance could be severely degraded due to channel aging caused by user mobility and high processing latency. In this paper, an integrated scheme of uplink (UL) channel estimation and downlink (DL) channel prediction is proposed to alleviate channel aging in time division duplex (TDD) massive MIMO-OTFS systems. Specifically, first, an iterative basis expansion model (BEM) based UL channel estimation scheme is proposed to accurately estimate UL channels with the aid of carefully designed OTFS frame pattern. Then a set of Slepian sequences are used to model the estimated UL channels, and the dynamic Slepian coefficients are fitted by a set of orthogonal polynomials. A channel predictor is derived to predict DL channels by iteratively extrapolating the Slepian coefficients. Simulation results verify that the proposed UL channel estimation and DL channel prediction schemes outperform the existing schemes in terms of normalized mean square error of channel estimation/prediction and DL spectral efficiency, with less pilot overhead.
NeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Dec 05, 2023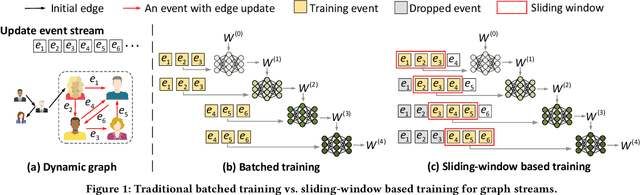
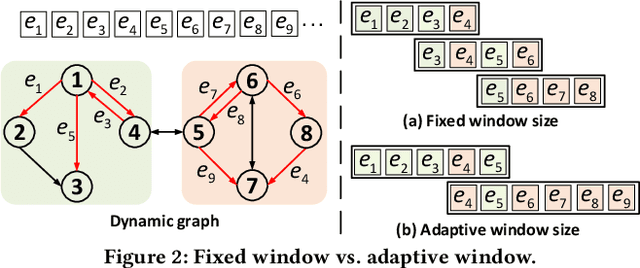
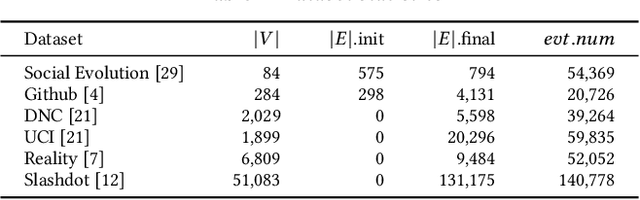
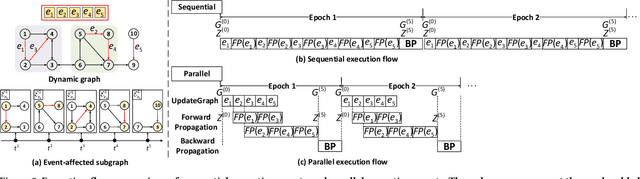
Existing Graph Neural Network (GNN) training frameworks have been designed to help developers easily create performant GNN implementations. However, most existing GNN frameworks assume that the input graphs are static, but ignore that most real-world graphs are constantly evolving. Though many dynamic GNN models have emerged to learn from evolving graphs, the training process of these dynamic GNNs is dramatically different from traditional GNNs in that it captures both the spatial and temporal dependencies of graph updates. This poses new challenges for designing dynamic GNN training frameworks. First, the traditional batched training method fails to capture real-time structural evolution information. Second, the time-dependent nature makes parallel training hard to design. Third, it lacks system supports for users to efficiently implement dynamic GNNs. In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs. Our experimental results demonstrate that, compared to state-of-the-art dynamic GNN implementations, NeutronStream achieves speedups ranging from 1.48X to 5.87X and an average accuracy improvement of 3.97%.
Comprehensive Evaluation of GNN Training Systems: A Data Management Perspective
Nov 22, 2023Many Graph Neural Network (GNN) training systems have emerged recently to support efficient GNN training. Since GNNs embody complex data dependencies between training samples, the training of GNNs should address distinct challenges different from DNN training in data management, such as data partitioning, batch preparation for mini-batch training, and data transferring between CPUs and GPUs. These factors, which take up a large proportion of training time, make data management in GNN training more significant. This paper reviews GNN training from a data management perspective and provides a comprehensive analysis and evaluation of the representative approaches. We conduct extensive experiments on various benchmark datasets and show many interesting and valuable results. We also provide some practical tips learned from these experiments, which are helpful for designing GNN training systems in the future.