 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionANNS: An Efficient CPU/GPU Cooperative Processing Architecture for Billion-scale Approximate Nearest Neighbor Search
Sep 25, 2024



Approximate nearest neighbor search (ANNS) has emerged as a crucial component of database and AI infrastructure. Ever-increasing vector datasets pose significant challenges in terms of performance, cost, and accuracy for ANNS services. None of modern ANNS systems can address these issues simultaneously. We present FusionANNS, a high-throughput, low-latency, cost-efficient, and high-accuracy ANNS system for billion-scale datasets using SSDs and only one entry-level GPU. The key idea of FusionANNS lies in CPU/GPU collaborative filtering and re-ranking mechanisms, which significantly reduce I/O operations across CPUs, GPU, and SSDs to break through the I/O performance bottleneck. Specifically, we propose three novel designs: (1) multi-tiered indexing to avoid data swapping between CPUs and GPU, (2) heuristic re-ranking to eliminate unnecessary I/Os and computations while guaranteeing high accuracy, and (3) redundant-aware I/O deduplication to further improve I/O efficiency. We implement FusionANNS and compare it with the state-of-the-art SSD-based ANNS system--SPANN and GPU-accelerated in-memory ANNS system--RUMMY. Experimental results show that FusionANNS achieves 1) 9.4-13.1X higher query per second (QPS) and 5.7-8.8X higher cost efficiency compared with SPANN; 2) and 2-4.9X higher QPS and 2.3-6.8X higher cost efficiency compared with RUMMY, while guaranteeing low latency and high accuracy.
NeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Dec 05, 2023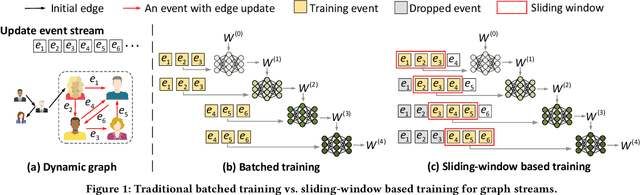
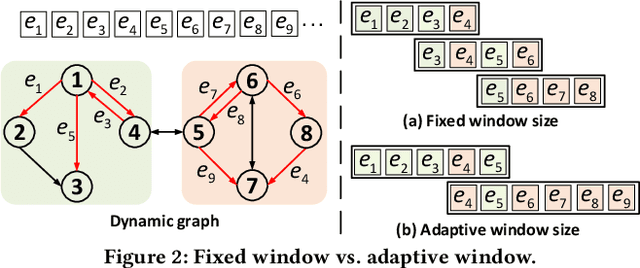
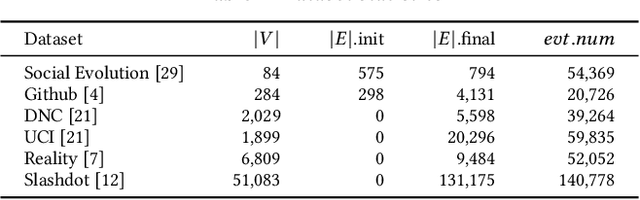
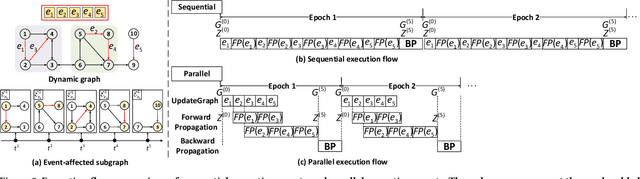
Existing Graph Neural Network (GNN) training frameworks have been designed to help developers easily create performant GNN implementations. However, most existing GNN frameworks assume that the input graphs are static, but ignore that most real-world graphs are constantly evolving. Though many dynamic GNN models have emerged to learn from evolving graphs, the training process of these dynamic GNNs is dramatically different from traditional GNNs in that it captures both the spatial and temporal dependencies of graph updates. This poses new challenges for designing dynamic GNN training frameworks. First, the traditional batched training method fails to capture real-time structural evolution information. Second, the time-dependent nature makes parallel training hard to design. Third, it lacks system supports for users to efficiently implement dynamic GNNs. In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs. Our experimental results demonstrate that, compared to state-of-the-art dynamic GNN implementations, NeutronStream achieves speedups ranging from 1.48X to 5.87X and an average accuracy improvement of 3.97%.