 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Dec 05, 2023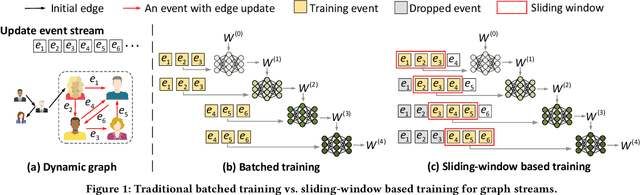
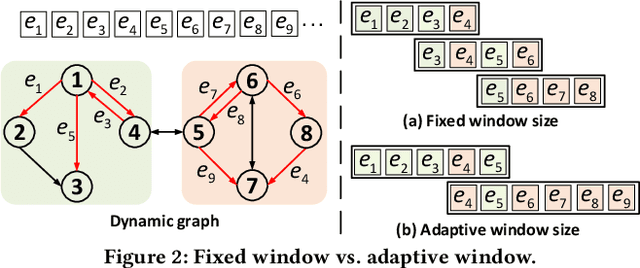
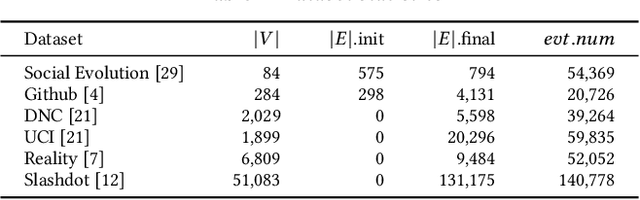
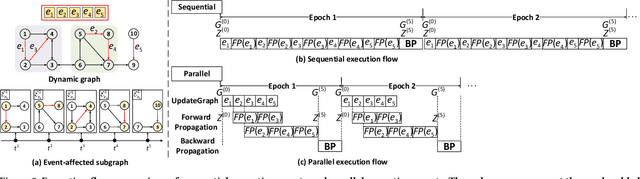
Existing Graph Neural Network (GNN) training frameworks have been designed to help developers easily create performant GNN implementations. However, most existing GNN frameworks assume that the input graphs are static, but ignore that most real-world graphs are constantly evolving. Though many dynamic GNN models have emerged to learn from evolving graphs, the training process of these dynamic GNNs is dramatically different from traditional GNNs in that it captures both the spatial and temporal dependencies of graph updates. This poses new challenges for designing dynamic GNN training frameworks. First, the traditional batched training method fails to capture real-time structural evolution information. Second, the time-dependent nature makes parallel training hard to design. Third, it lacks system supports for users to efficiently implement dynamic GNNs. In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs. Our experimental results demonstrate that, compared to state-of-the-art dynamic GNN implementations, NeutronStream achieves speedups ranging from 1.48X to 5.87X and an average accuracy improvement of 3.97%.
MxPool: Multiplex Pooling for Hierarchical Graph Representation Learning
Apr 15, 2020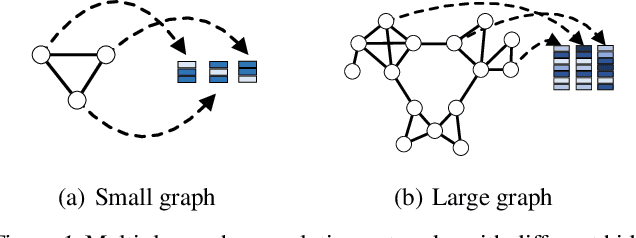
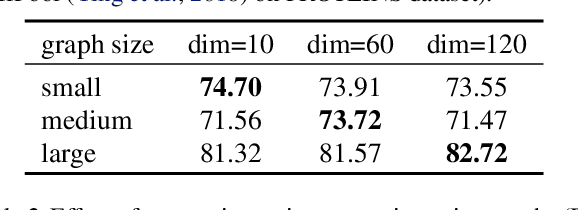
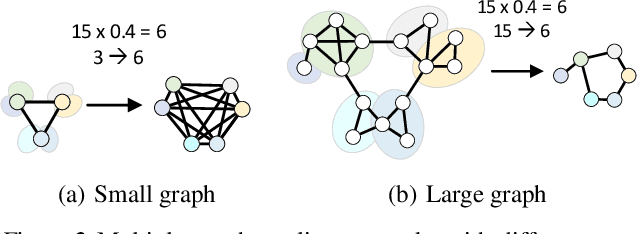

How to utilize deep learning methods for graph classification tasks has attracted considerable research attention in the past few years. Regarding graph classification tasks, the graphs to be classified may have various graph sizes (i.e., different number of nodes and edges) and have various graph properties (e.g., average node degree, diameter, and clustering coefficient). The diverse property of graphs has imposed significant challenges on existing graph learning techniques since diverse graphs have different best-fit hyperparameters. It is difficult to learn graph features from a set of diverse graphs by a unified graph neural network. This motivates us to use a multiplex structure in a diverse way and utilize a priori properties of graphs to guide the learning. In this paper, we propose MxPool, which concurrently uses multiple graph convolution/pooling networks to build a hierarchical learning structure for graph representation learning tasks. Our experiments on numerous graph classification benchmarks show that our MxPool has superiority over other state-of-the-art graph representation learning methods.