 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeutronStream: A Dynamic GNN Training Framework with Sliding Window for Graph Streams
Dec 05, 2023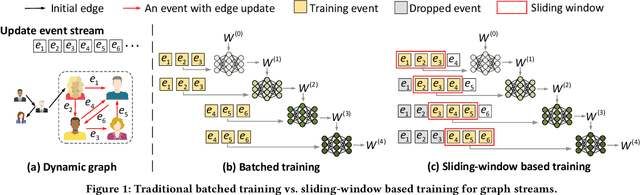
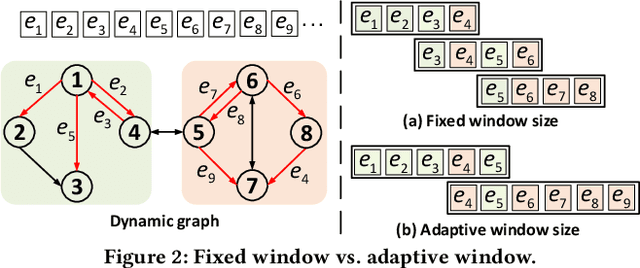
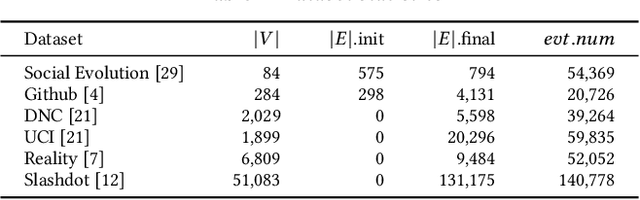
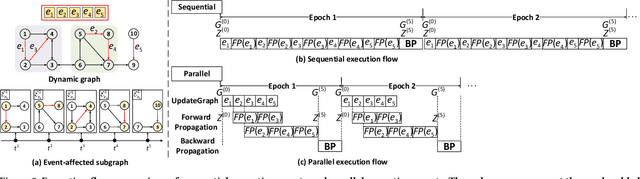
Existing Graph Neural Network (GNN) training frameworks have been designed to help developers easily create performant GNN implementations. However, most existing GNN frameworks assume that the input graphs are static, but ignore that most real-world graphs are constantly evolving. Though many dynamic GNN models have emerged to learn from evolving graphs, the training process of these dynamic GNNs is dramatically different from traditional GNNs in that it captures both the spatial and temporal dependencies of graph updates. This poses new challenges for designing dynamic GNN training frameworks. First, the traditional batched training method fails to capture real-time structural evolution information. Second, the time-dependent nature makes parallel training hard to design. Third, it lacks system supports for users to efficiently implement dynamic GNNs. In this paper, we present NeutronStream, a framework for training dynamic GNN models. NeutronStream abstracts the input dynamic graph into a chronologically updated stream of events and processes the stream with an optimized sliding window to incrementally capture the spatial-temporal dependencies of events. Furthermore, NeutronStream provides a parallel execution engine to tackle the sequential event processing challenge to achieve high performance. NeutronStream also integrates a built-in graph storage structure that supports dynamic updates and provides a set of easy-to-use APIs that allow users to express their dynamic GNNs. Our experimental results demonstrate that, compared to state-of-the-art dynamic GNN implementations, NeutronStream achieves speedups ranging from 1.48X to 5.87X and an average accuracy improvement of 3.97%.
Comprehensive Evaluation of GNN Training Systems: A Data Management Perspective
Nov 22, 2023Many Graph Neural Network (GNN) training systems have emerged recently to support efficient GNN training. Since GNNs embody complex data dependencies between training samples, the training of GNNs should address distinct challenges different from DNN training in data management, such as data partitioning, batch preparation for mini-batch training, and data transferring between CPUs and GPUs. These factors, which take up a large proportion of training time, make data management in GNN training more significant. This paper reviews GNN training from a data management perspective and provides a comprehensive analysis and evaluation of the representative approaches. We conduct extensive experiments on various benchmark datasets and show many interesting and valuable results. We also provide some practical tips learned from these experiments, which are helpful for designing GNN training systems in the future.
NeutronOrch: Rethinking Sample-based GNN Training under CPU-GPU Heterogeneous Environments
Nov 22, 2023Graph Neural Networks (GNNs) have demonstrated outstanding performance in various applications. Existing frameworks utilize CPU-GPU heterogeneous environments to train GNN models and integrate mini-batch and sampling techniques to overcome the GPU memory limitation. In CPU-GPU heterogeneous environments, we can divide sample-based GNN training into three steps: sample, gather, and train. Existing GNN systems use different task orchestrating methods to employ each step on CPU or GPU. After extensive experiments and analysis, we find that existing task orchestrating methods fail to fully utilize the heterogeneous resources, limited by inefficient CPU processing or GPU resource contention. In this paper, we propose NeutronOrch, a system for sample-based GNN training that incorporates a layer-based task orchestrating method and ensures balanced utilization of the CPU and GPU. NeutronOrch decouples the training process by layer and pushes down the training task of the bottom layer to the CPU. This significantly reduces the computational load and memory footprint of GPU training. To avoid inefficient CPU processing, NeutronOrch only offloads the training of frequently accessed vertices to the CPU and lets GPU reuse their embeddings with bounded staleness. Furthermore, NeutronOrch provides a fine-grained pipeline design for the layer-based task orchestrating method, fully overlapping different tasks on heterogeneous resources while strictly guaranteeing bounded staleness. The experimental results show that compared with the state-of-the-art GNN systems, NeutronOrch can achieve up to 4.61x performance speedup.