 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionANNS: An Efficient CPU/GPU Cooperative Processing Architecture for Billion-scale Approximate Nearest Neighbor Search
Sep 25, 2024



Approximate nearest neighbor search (ANNS) has emerged as a crucial component of database and AI infrastructure. Ever-increasing vector datasets pose significant challenges in terms of performance, cost, and accuracy for ANNS services. None of modern ANNS systems can address these issues simultaneously. We present FusionANNS, a high-throughput, low-latency, cost-efficient, and high-accuracy ANNS system for billion-scale datasets using SSDs and only one entry-level GPU. The key idea of FusionANNS lies in CPU/GPU collaborative filtering and re-ranking mechanisms, which significantly reduce I/O operations across CPUs, GPU, and SSDs to break through the I/O performance bottleneck. Specifically, we propose three novel designs: (1) multi-tiered indexing to avoid data swapping between CPUs and GPU, (2) heuristic re-ranking to eliminate unnecessary I/Os and computations while guaranteeing high accuracy, and (3) redundant-aware I/O deduplication to further improve I/O efficiency. We implement FusionANNS and compare it with the state-of-the-art SSD-based ANNS system--SPANN and GPU-accelerated in-memory ANNS system--RUMMY. Experimental results show that FusionANNS achieves 1) 9.4-13.1X higher query per second (QPS) and 5.7-8.8X higher cost efficiency compared with SPANN; 2) and 2-4.9X higher QPS and 2.3-6.8X higher cost efficiency compared with RUMMY, while guaranteeing low latency and high accuracy.
DiskANN++: Efficient Page-based Search over Isomorphic Mapped Graph Index using Query-sensitivity Entry Vertex
Sep 30, 2023Given a vector dataset $\mathcal{X}$ and a query vector $\vec{x}_q$, graph-based Approximate Nearest Neighbor Search (ANNS) aims to build a graph index $G$ and approximately return vectors with minimum distances to $\vec{x}_q$ by searching over $G$. The main drawback of graph-based ANNS is that a graph index would be too large to fit into the memory especially for a large-scale $\mathcal{X}$. To solve this, a Product Quantization (PQ)-based hybrid method called DiskANN is proposed to store a low-dimensional PQ index in memory and retain a graph index in SSD, thus reducing memory overhead while ensuring a high search accuracy. However, it suffers from two I/O issues that significantly affect the overall efficiency: (1) long routing path from an entry vertex to the query's neighborhood that results in large number of I/O requests and (2) redundant I/O requests during the routing process. We propose an optimized DiskANN++ to overcome above issues. Specifically, for the first issue, we present a query-sensitive entry vertex selection strategy to replace DiskANN's static graph-central entry vertex by a dynamically determined entry vertex that is close to the query. For the second I/O issue, we present an isomorphic mapping on DiskANN's graph index to optimize the SSD layout and propose an asynchronously optimized Pagesearch based on the optimized SSD layout as an alternative to DiskANN's beamsearch. Comprehensive experimental studies on eight real-world datasets demonstrate our DiskANN++'s superiority on efficiency. We achieve a notable 1.5 X to 2.2 X improvement on QPS compared to DiskANN, given the same accuracy constraint.
Gradient Mask: Lateral Inhibition Mechanism Improves Performance in Artificial Neural Networks
Aug 14, 2022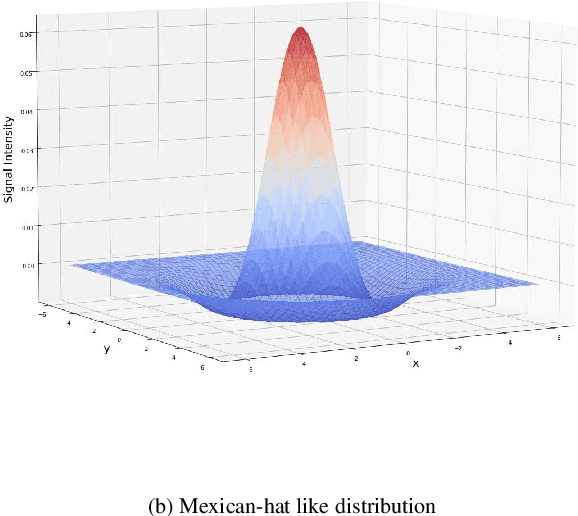

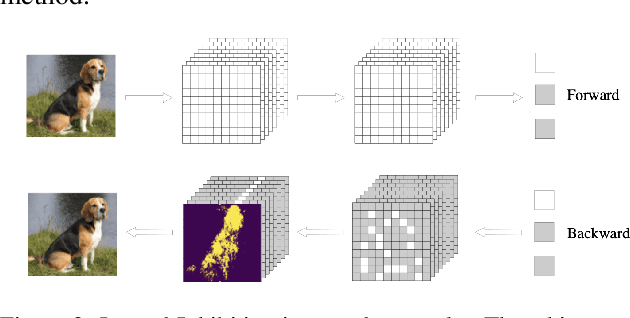

Lateral inhibitory connections have been observed in the cortex of the biological brain, and has been extensively studied in terms of its role in cognitive functions. However, in the vanilla version of backpropagation in deep learning, all gradients (which can be understood to comprise of both signal and noise gradients) flow through the network during weight updates. This may lead to overfitting. In this work, inspired by biological lateral inhibition, we propose Gradient Mask, which effectively filters out noise gradients in the process of backpropagation. This allows the learned feature information to be more intensively stored in the network while filtering out noisy or unimportant features. Furthermore, we demonstrate analytically how lateral inhibition in artificial neural networks improves the quality of propagated gradients. A new criterion for gradient quality is proposed which can be used as a measure during training of various convolutional neural networks (CNNs). Finally, we conduct several different experiments to study how Gradient Mask improves the performance of the network both quantitatively and qualitatively. Quantitatively, accuracy in the original CNN architecture, accuracy after pruning, and accuracy after adversarial attacks have shown improvements. Qualitatively, the CNN trained using Gradient Mask has developed saliency maps that focus primarily on the object of interest, which is useful for data augmentation and network interpretability.