 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiskANN++: Efficient Page-based Search over Isomorphic Mapped Graph Index using Query-sensitivity Entry Vertex
Sep 30, 2023Given a vector dataset $\mathcal{X}$ and a query vector $\vec{x}_q$, graph-based Approximate Nearest Neighbor Search (ANNS) aims to build a graph index $G$ and approximately return vectors with minimum distances to $\vec{x}_q$ by searching over $G$. The main drawback of graph-based ANNS is that a graph index would be too large to fit into the memory especially for a large-scale $\mathcal{X}$. To solve this, a Product Quantization (PQ)-based hybrid method called DiskANN is proposed to store a low-dimensional PQ index in memory and retain a graph index in SSD, thus reducing memory overhead while ensuring a high search accuracy. However, it suffers from two I/O issues that significantly affect the overall efficiency: (1) long routing path from an entry vertex to the query's neighborhood that results in large number of I/O requests and (2) redundant I/O requests during the routing process. We propose an optimized DiskANN++ to overcome above issues. Specifically, for the first issue, we present a query-sensitive entry vertex selection strategy to replace DiskANN's static graph-central entry vertex by a dynamically determined entry vertex that is close to the query. For the second I/O issue, we present an isomorphic mapping on DiskANN's graph index to optimize the SSD layout and propose an asynchronously optimized Pagesearch based on the optimized SSD layout as an alternative to DiskANN's beamsearch. Comprehensive experimental studies on eight real-world datasets demonstrate our DiskANN++'s superiority on efficiency. We achieve a notable 1.5 X to 2.2 X improvement on QPS compared to DiskANN, given the same accuracy constraint.
Navigable Proximity Graph-Driven Native Hybrid Queries with Structured and Unstructured Constraints
Mar 25, 2022

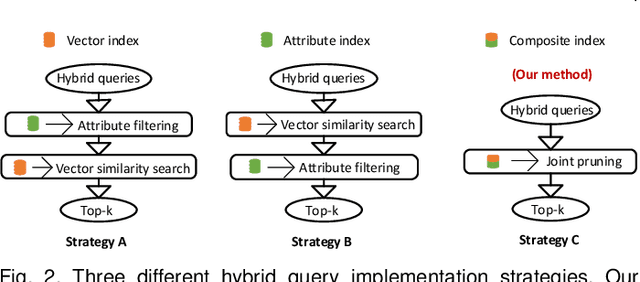
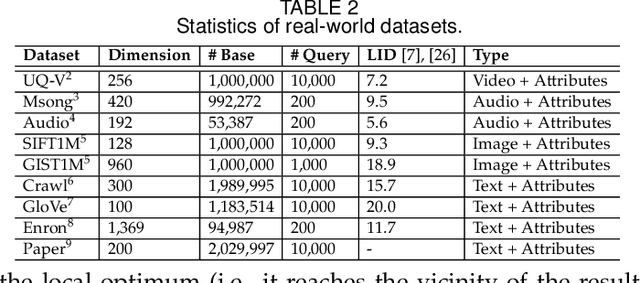
As research interest surges, vector similarity search is applied in multiple fields, including data mining, computer vision, and information retrieval. {Given a set of objects (e.g., a set of images) and a query object, we can easily transform each object into a feature vector and apply the vector similarity search to retrieve the most similar objects. However, the original vector similarity search cannot well support \textit{hybrid queries}, where users not only input unstructured query constraint (i.e., the feature vector of query object) but also structured query constraint (i.e., the desired attributes of interest). Hybrid query processing aims at identifying these objects with similar feature vectors to query object and satisfying the given attribute constraints. Recent efforts have attempted to answer a hybrid query by performing attribute filtering and vector similarity search separately and then merging the results later, which limits efficiency and accuracy because they are not purpose-built for hybrid queries.} In this paper, we propose a native hybrid query (NHQ) framework based on proximity graph (PG), which provides the specialized \textit{composite index and joint pruning} modules for hybrid queries. We easily deploy existing various PGs on this framework to process hybrid queries efficiently. Moreover, we present two novel navigable PGs (NPGs) with optimized edge selection and routing strategies, which obtain better overall performance than existing PGs. After that, we deploy the proposed NPGs in NHQ to form two hybrid query methods, which significantly outperform the state-of-the-art competitors on all experimental datasets (10$\times$ faster under the same \textit{Recall}), including eight public and one in-house real-world datasets. Our code and datasets have been released at \url{https://github.com/AshenOn3/NHQ}.