 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition Rebinding Cache Reuse: Replay-Free Visual Revisiting for Interleaved Multimodal Reasoning
Jun 25, 2026Interleaved multimodal reasoning improves visual grounding by revisiting visual evidence during multi-step generation, yet existing methods typically rely on token replay, repeatedly forwarding selected visual tokens. A natural shortcut is to reuse the historical visual key-value (KV) cache directly. However, we identify a critical failure mode of this strategy: cached visual keys are already bound to their original positional context. Such stale positional binding distorts attention under later decoding contexts and can trigger severe autoregressive decoding collapse. This failure suggests that effective cache reuse requires reconstructing visual evidence under positions compatible with the current decoding state, rather than directly copying position-bound historical cache entries. To this end, we propose Position Rebinding Cache Reuse (PRCR), a cache-level framework for replay-free visual revisiting. PRCR stores raw visual KV cache together with their original spatial coordinates, then reassigns position-compatible coordinates to select entries and rebinds their keys before injecting the reconstructed cache into the active decoder cache. This design reuses historical visual evidence while preserving textual positional continuity and relative visual structure. Experiments across multiple multimodal reasoning benchmarks show that PRCR achieves replay-level or better performance, improving average accuracy by 5 percent and reducing visual-revisiting computation by up to tens of thousands of times.
VikingMem: A Memory Base Management System for Stateful LLM-based Applications
May 28, 2026Large Language Models have revolutionized interactive applications; however, their finite context windows pose a critical data management challenge for maintaining stateful, long-term interactions. Existing memory approaches often rely on simplistic extraction methods that lead to incomplete memories or use rigid, single-purpose memory extraction prompts tailored to a single use case, such as chatbots. Consequently, they lack generalizability and perform poorly across diverse downstream tasks. To bridge this gap, we introduce the Memory Base, a novel data management paradigm for managing the persistent state of long-term interactions. It is characterized by three core principles: selective extraction of high-value memories from raw information streams; inherent statefulness and evolution, where memory content is progressively summarized, corrected, and temporally weighted to prioritize recent interactions; and a generalizable abstraction paradigm designed for robust transferability across diverse applications, including education, recommendation, and agent memory. Building on this foundation, we present VikingMem, an end-to-end Memory Base Management System implemented on the VikingDB vector engine. VikingMem materializes this paradigm through interconnected event and entity abstractions. It features event-centric memory extraction to selectively handle complex information streams, while entities are dynamically updated by events to achieve stateful evolution. Using temporal compression via a topic-wise timeline and time-weighted recall, the system progressively produces high-level summary memories, prioritizes recent items, and compresses and fades older ones. Extensive evaluations on long-term memory benchmarks demonstrate that VikingMem outperformes baselines by up to 30% in memory retrieval effectiveness while maintaining the low latency essential for interactive applications.
Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Nov 26, 2024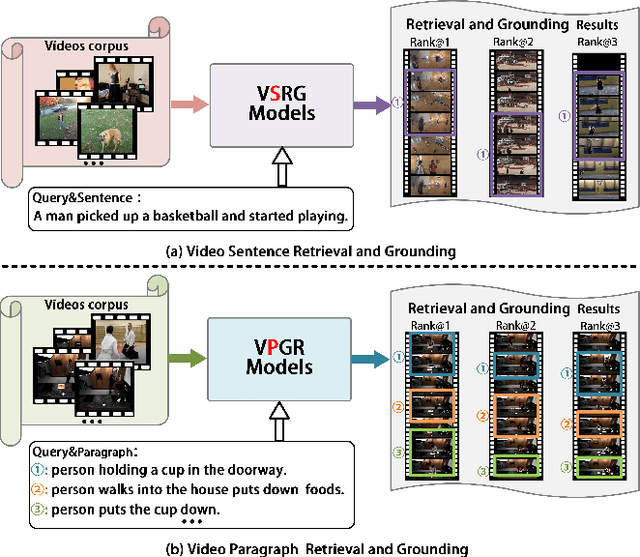
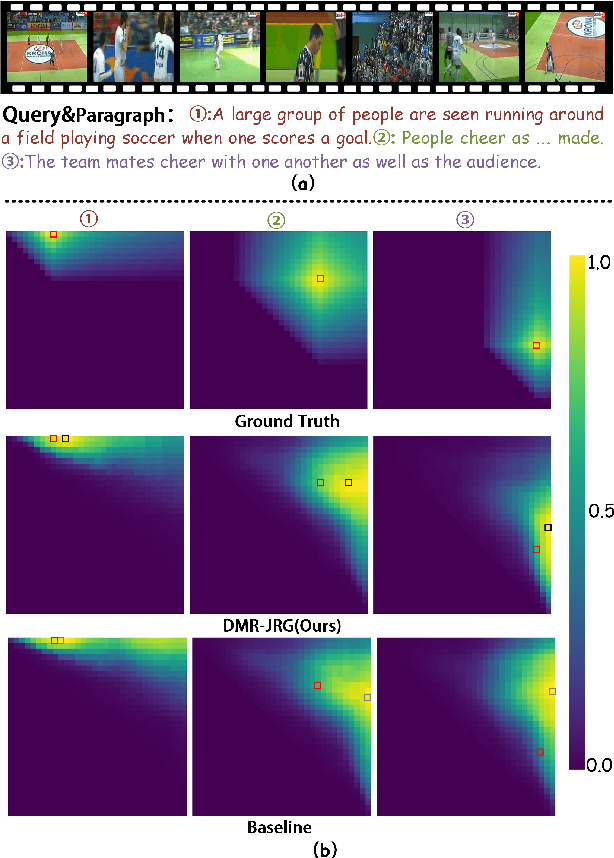

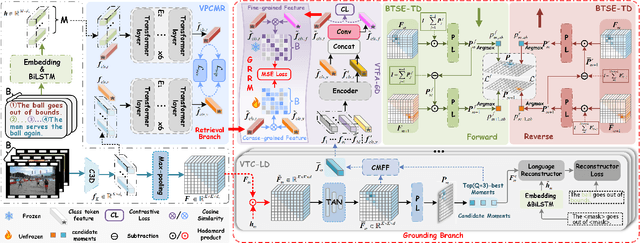
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.
Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding
Oct 31, 2024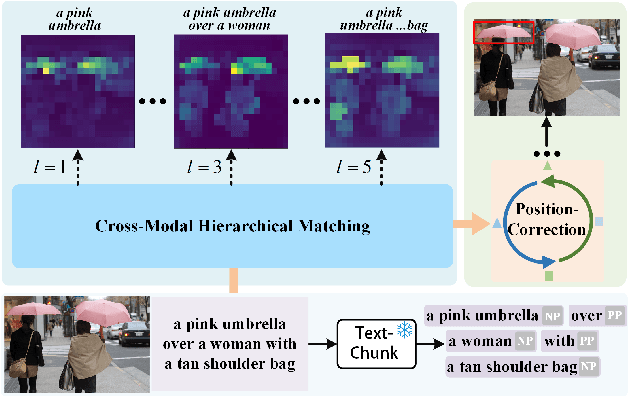

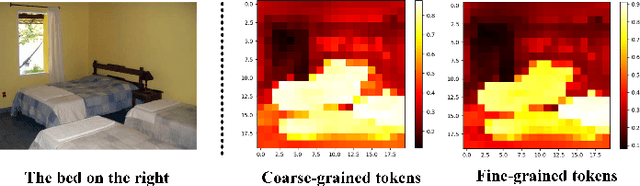
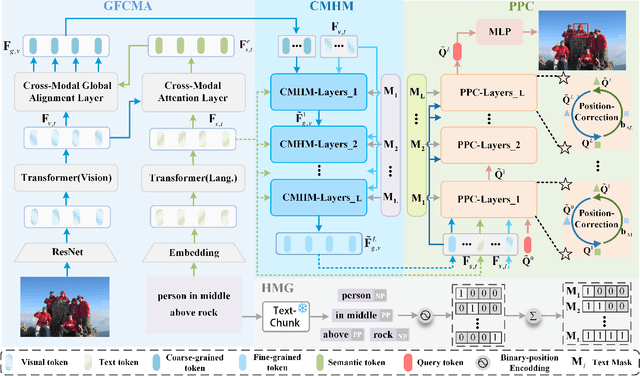
Visual grounding has attracted wide attention thanks to its broad application in various visual language tasks. Although visual grounding has made significant research progress, existing methods ignore the promotion effect of the association between text and image features at different hierarchies on cross-modal matching. This paper proposes a Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction Visual Grounding method. It first generates a mask through decoupled sentence phrases, and a text and image hierarchical matching mechanism is constructed, highlighting the role of association between different hierarchies in cross-modal matching. In addition, a corresponding target object position progressive correction strategy is defined based on the hierarchical matching mechanism to achieve accurate positioning for the target object described in the text. This method can continuously optimize and adjust the bounding box position of the target object as the certainty of the text description of the target object improves. This design explores the association between features at different hierarchies and highlights the role of features related to the target object and its position in target positioning. The proposed method is validated on different datasets through experiments, and its superiority is verified by the performance comparison with the state-of-the-art methods.
An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models
Jul 05, 2024
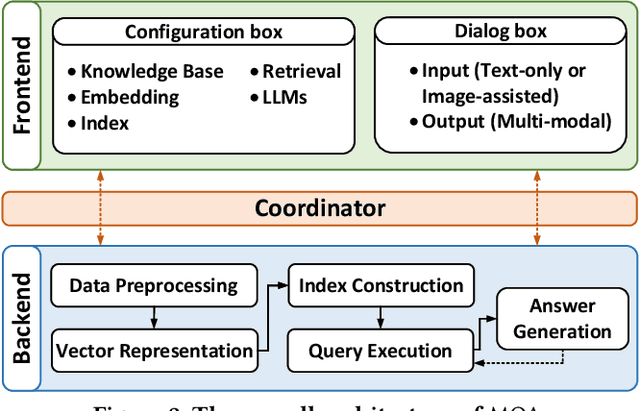
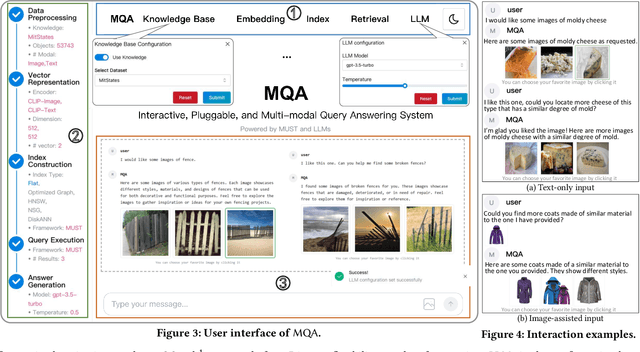

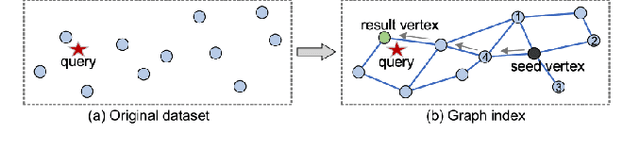
Retrieval-augmented Large Language Models (LLMs) have reshaped traditional query-answering systems, offering unparalleled user experiences. However, existing retrieval techniques often struggle to handle multi-modal query contexts. In this paper, we present an interactive Multi-modal Query Answering (MQA) system, empowered by our newly developed multi-modal retrieval framework and navigation graph index, integrated with cutting-edge LLMs. It comprises five core components: Data Preprocessing, Vector Representation, Index Construction, Query Execution, and Answer Generation, all orchestrated by a dedicated coordinator to ensure smooth data flow from input to answer generation. One notable aspect of MQA is its utilization of contrastive learning to assess the significance of different modalities, facilitating precise measurement of multi-modal information similarity. Furthermore, the system achieves efficient retrieval through our advanced navigation graph index, refined using computational pruning techniques. Another highlight of our system is its pluggable processing framework, allowing seamless integration of embedding models, graph indexes, and LLMs. This flexibility provides users diverse options for gaining insights from their multi-modal knowledge base. A preliminary video introduction of MQA is available at https://youtu.be/xvUuo2ZIqWk.
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024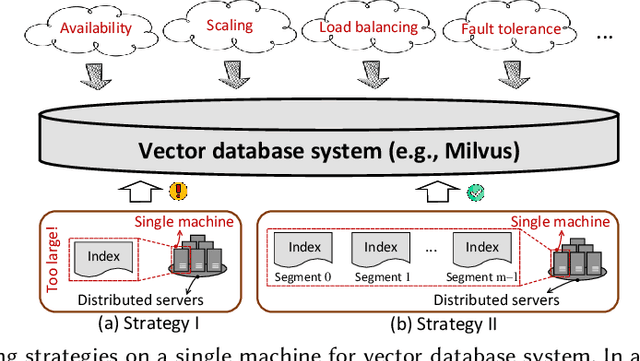

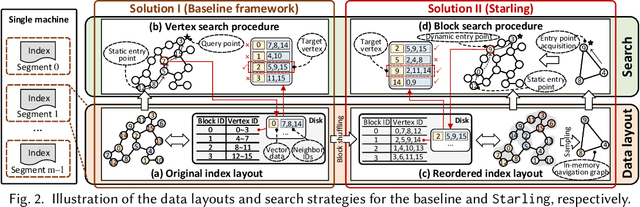

High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.
MUST: An Effective and Scalable Framework for Multimodal Search of Target Modality
Dec 11, 2023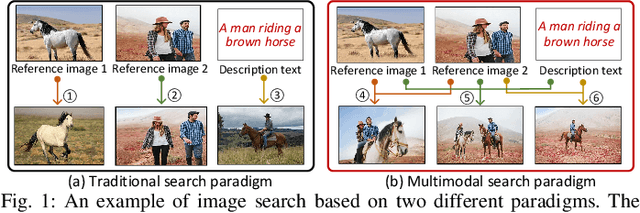
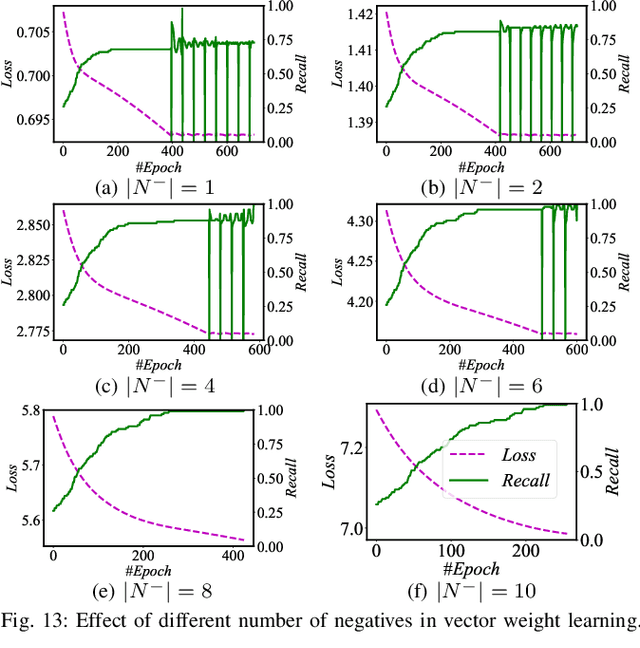
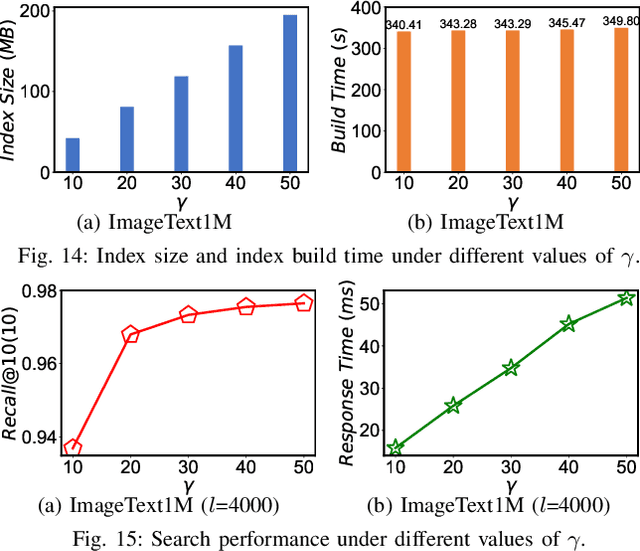
We investigate the problem of multimodal search of target modality, where the task involves enhancing a query in a specific target modality by integrating information from auxiliary modalities. The goal is to retrieve relevant objects whose contents in the target modality match the specified multimodal query. The paper first introduces two baseline approaches that integrate techniques from the Database, Information Retrieval, and Computer Vision communities. These baselines either merge the results of separate vector searches for each modality or perform a single-channel vector search by fusing all modalities. However, both baselines have limitations in terms of efficiency and accuracy as they fail to adequately consider the varying importance of fusing information across modalities. To overcome these limitations, the paper proposes a novel framework, called MUST. Our framework employs a hybrid fusion mechanism, combining different modalities at multiple stages. Notably, we leverage vector weight learning to determine the importance of each modality, thereby enhancing the accuracy of joint similarity measurement. Additionally, the proposed framework utilizes a fused proximity graph index, enabling efficient joint search for multimodal queries. MUST offers several other advantageous properties, including pluggable design to integrate any advanced embedding techniques, user flexibility to customize weight preferences, and modularized index construction. Extensive experiments on real-world datasets demonstrate the superiority of MUST over the baselines in terms of both search accuracy and efficiency. Our framework achieves over 10x faster search times while attaining an average of 93% higher accuracy. Furthermore, MUST exhibits scalability to datasets containing more than 10 million data elements.
Navigable Proximity Graph-Driven Native Hybrid Queries with Structured and Unstructured Constraints
Mar 25, 2022

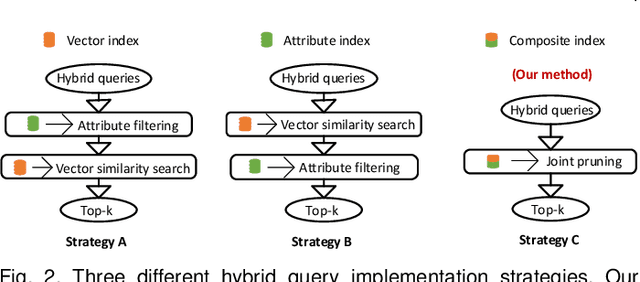
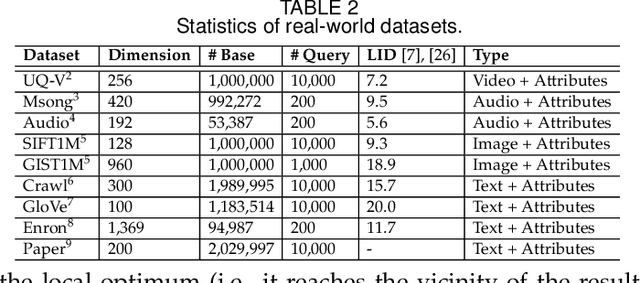
As research interest surges, vector similarity search is applied in multiple fields, including data mining, computer vision, and information retrieval. {Given a set of objects (e.g., a set of images) and a query object, we can easily transform each object into a feature vector and apply the vector similarity search to retrieve the most similar objects. However, the original vector similarity search cannot well support \textit{hybrid queries}, where users not only input unstructured query constraint (i.e., the feature vector of query object) but also structured query constraint (i.e., the desired attributes of interest). Hybrid query processing aims at identifying these objects with similar feature vectors to query object and satisfying the given attribute constraints. Recent efforts have attempted to answer a hybrid query by performing attribute filtering and vector similarity search separately and then merging the results later, which limits efficiency and accuracy because they are not purpose-built for hybrid queries.} In this paper, we propose a native hybrid query (NHQ) framework based on proximity graph (PG), which provides the specialized \textit{composite index and joint pruning} modules for hybrid queries. We easily deploy existing various PGs on this framework to process hybrid queries efficiently. Moreover, we present two novel navigable PGs (NPGs) with optimized edge selection and routing strategies, which obtain better overall performance than existing PGs. After that, we deploy the proposed NPGs in NHQ to form two hybrid query methods, which significantly outperform the state-of-the-art competitors on all experimental datasets (10$\times$ faster under the same \textit{Recall}), including eight public and one in-house real-world datasets. Our code and datasets have been released at \url{https://github.com/AshenOn3/NHQ}.
A Comprehensive Survey and Experimental Comparison of Graph-Based Approximate Nearest Neighbor Search
Jan 29, 2021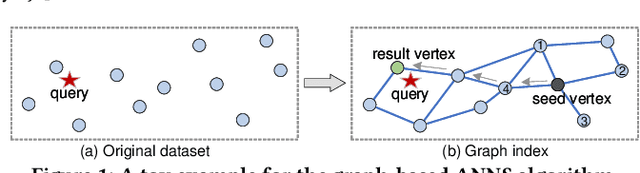

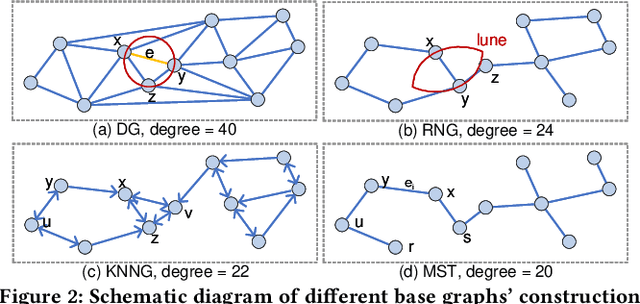
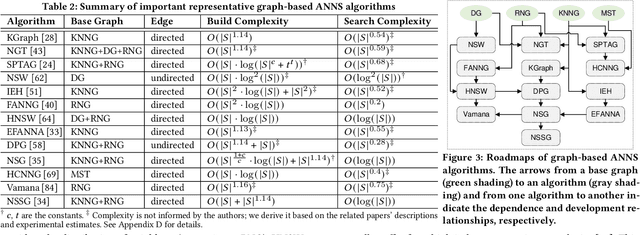
Approximate nearest neighbor search (ANNS) constitutes an important operation in a multitude of applications, including recommendation systems, information retrieval, and pattern recognition. In the past decade, graph-based ANNS algorithms have been the leading paradigm in this domain, with dozens of graph-based ANNS algorithms proposed. Such algorithms aim to provide effective, efficient solutions for retrieving the nearest neighbors for a given query. Nevertheless, these efforts focus on developing and optimizing algorithms with different approaches, so there is a real need for a comprehensive survey about the approaches' relative performance, strengths, and pitfalls. Thus here we provide a thorough comparative analysis and experimental evaluation of 13 representative graph-based ANNS algorithms via a new taxonomy and fine-grained pipeline. We compared each algorithm in a uniform test environment on eight real-world datasets and 12 synthetic datasets with varying sizes and characteristics. Our study yields novel discoveries, offerings several useful principles to improve algorithms. This effort also helped us pinpoint algorithms' working portions, along with rule-of-thumb recommendations about promising research directions and suitable algorithms for practitioners in different fields.