 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Paper and Code
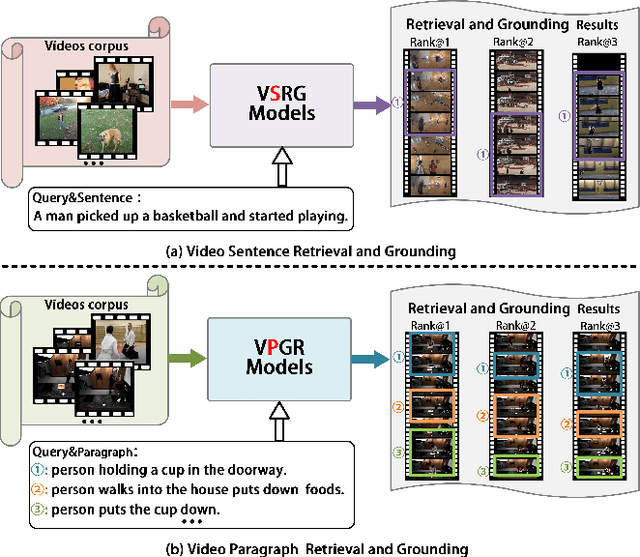
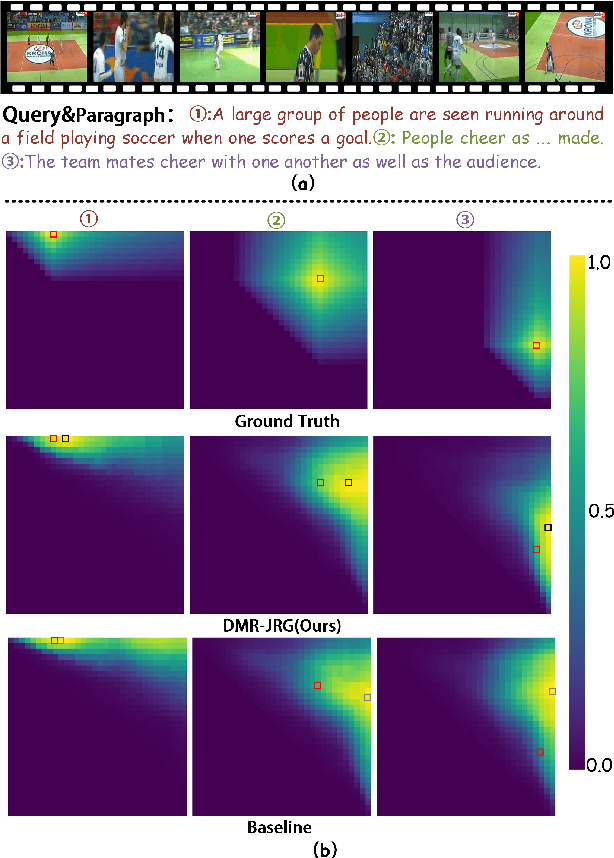

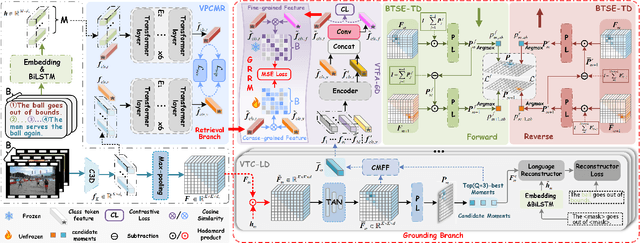
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.