 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Nov 26, 2024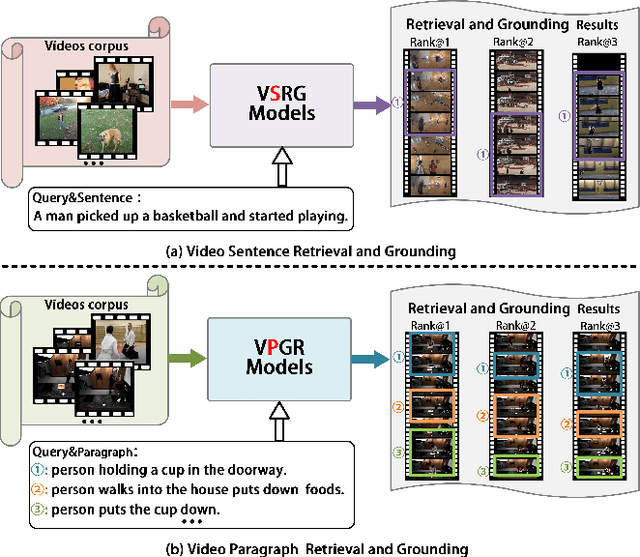
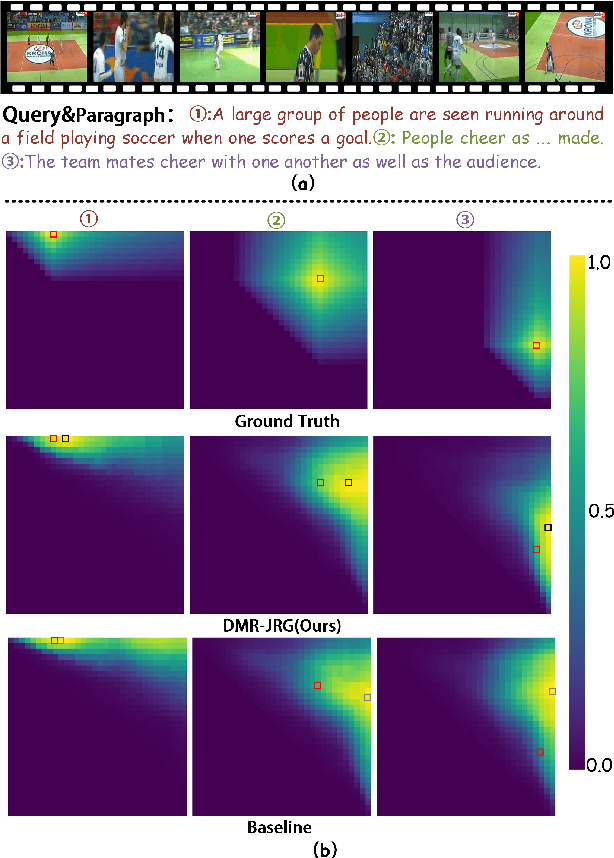

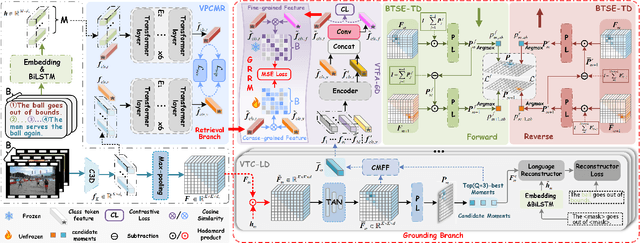
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.
A Survey on Incomplete Multi-view Clustering
Aug 17, 2022
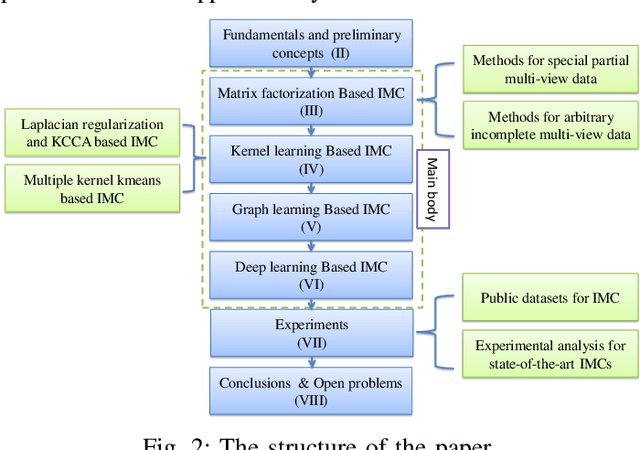
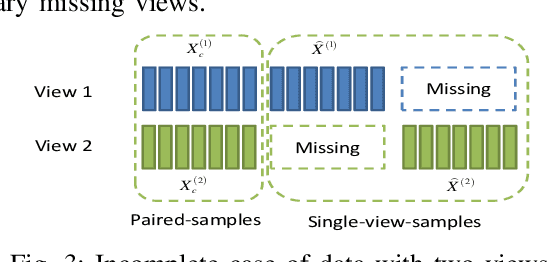
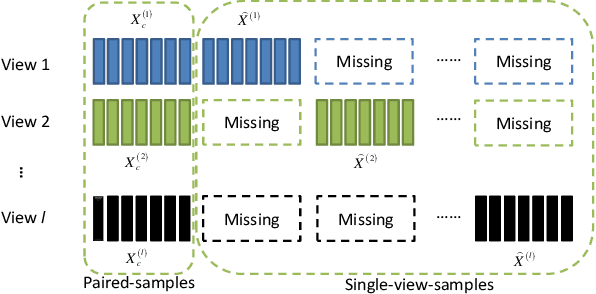
Conventional multi-view clustering seeks to partition data into respective groups based on the assumption that all views are fully observed. However, in practical applications, such as disease diagnosis, multimedia analysis, and recommendation system, it is common to observe that not all views of samples are available in many cases, which leads to the failure of the conventional multi-view clustering methods. Clustering on such incomplete multi-view data is referred to as incomplete multi-view clustering. In view of the promising application prospects, the research of incomplete multi-view clustering has noticeable advances in recent years. However, there is no survey to summarize the current progresses and point out the future research directions. To this end, we review the recent studies of incomplete multi-view clustering. Importantly, we provide some frameworks to unify the corresponding incomplete multi-view clustering methods, and make an in-depth comparative analysis for some representative methods from theoretical and experimental perspectives. Finally, some open problems in the incomplete multi-view clustering field are offered for researchers.
Learning Modal-Invariant and Temporal-Memory for Video-based Visible-Infrared Person Re-Identification
Aug 04, 2022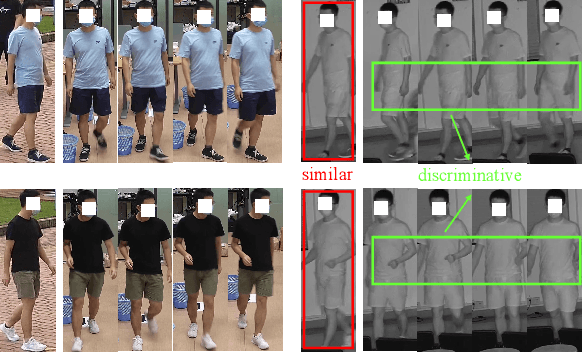


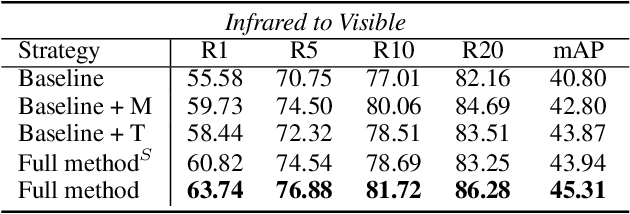
Thanks for the cross-modal retrieval techniques, visible-infrared (RGB-IR) person re-identification (Re-ID) is achieved by projecting them into a common space, allowing person Re-ID in 24-hour surveillance systems. However, with respect to the probe-to-gallery, almost all existing RGB-IR based cross-modal person Re-ID methods focus on image-to-image matching, while the video-to-video matching which contains much richer spatial- and temporal-information remains under-explored. In this paper, we primarily study the video-based cross-modal person Re-ID method. To achieve this task, a video-based RGB-IR dataset is constructed, in which 927 valid identities with 463,259 frames and 21,863 tracklets captured by 12 RGB/IR cameras are collected. Based on our constructed dataset, we prove that with the increase of frames in a tracklet, the performance does meet more enhancement, demonstrating the significance of video-to-video matching in RGB-IR person Re-ID. Additionally, a novel method is further proposed, which not only projects two modalities to a modal-invariant subspace, but also extracts the temporal-memory for motion-invariant. Thanks to these two strategies, much better results are achieved on our video-based cross-modal person Re-ID. The code and dataset are released at: https://github.com/VCMproject233/MITML.
HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
Mar 19, 2022
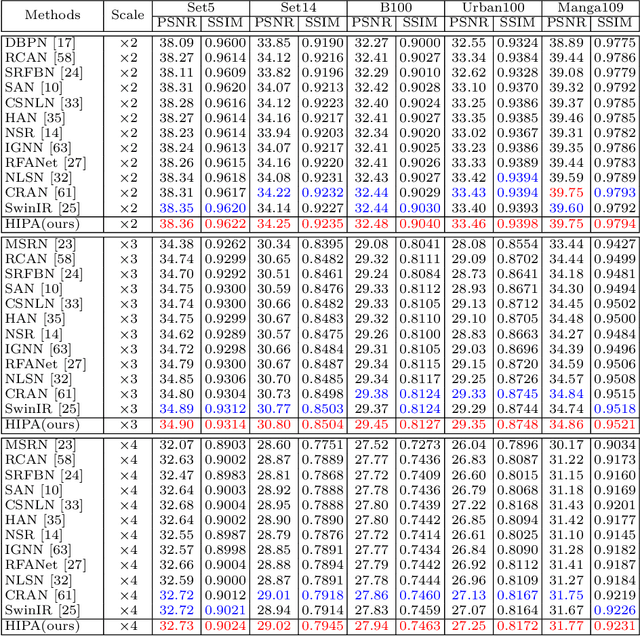
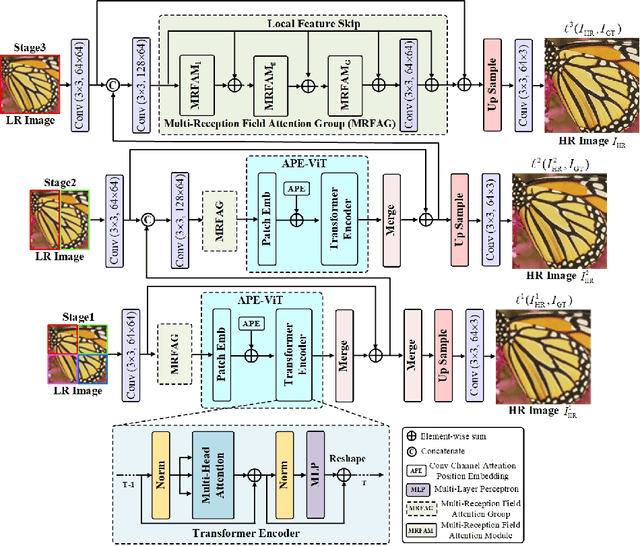

Transformer-based architectures start to emerge in single image super resolution (SISR) and have achieved promising performance. Most existing Vision Transformers divide images into the same number of patches with a fixed size, which may not be optimal for restoring patches with different levels of texture richness. This paper presents HIPA, a novel Transformer architecture that progressively recovers the high resolution image using a hierarchical patch partition. Specifically, we build a cascaded model that processes an input image in multiple stages, where we start with tokens with small patch sizes and gradually merge to the full resolution. Such a hierarchical patch mechanism not only explicitly enables feature aggregation at multiple resolutions but also adaptively learns patch-aware features for different image regions, e.g., using a smaller patch for areas with fine details and a larger patch for textureless regions. Meanwhile, a new attention-based position encoding scheme for Transformer is proposed to let the network focus on which tokens should be paid more attention by assigning different weights to different tokens, which is the first time to our best knowledge. Furthermore, we also propose a new multi-reception field attention module to enlarge the convolution reception field from different branches. The experimental results on several public datasets demonstrate the superior performance of the proposed HIPA over previous methods quantitatively and qualitatively.
Pseudocylindrical Convolutions for Learned Omnidirectional Image Compression
Dec 25, 2021
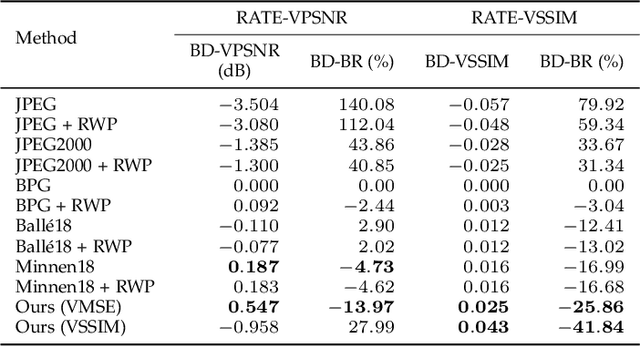
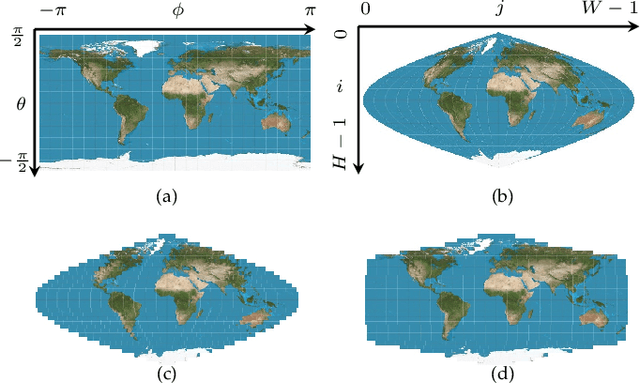

Although equirectangular projection (ERP) is a convenient form to store omnidirectional images (also known as 360-degree images), it is neither equal-area nor conformal, thus not friendly to subsequent visual communication. In the context of image compression, ERP will over-sample and deform things and stuff near the poles, making it difficult for perceptually optimal bit allocation. In conventional 360-degree image compression, techniques such as region-wise packing and tiled representation are introduced to alleviate the over-sampling problem, achieving limited success. In this paper, we make one of the first attempts to learn deep neural networks for omnidirectional image compression. We first describe parametric pseudocylindrical representation as a generalization of common pseudocylindrical map projections. A computationally tractable greedy method is presented to determine the (sub)-optimal configuration of the pseudocylindrical representation in terms of a novel proxy objective for rate-distortion performance. We then propose pseudocylindrical convolutions for 360-degree image compression. Under reasonable constraints on the parametric representation, the pseudocylindrical convolution can be efficiently implemented by standard convolution with the so-called pseudocylindrical padding. To demonstrate the feasibility of our idea, we implement an end-to-end 360-degree image compression system, consisting of the learned pseudocylindrical representation, an analysis transform, a non-uniform quantizer, a synthesis transform, and an entropy model. Experimental results on $19,790$ omnidirectional images show that our method achieves consistently better rate-distortion performance than the competing methods. Moreover, the visual quality by our method is significantly improved for all images at all bitrates.
U2-Former: A Nested U-shaped Transformer for Image Restoration
Dec 08, 2021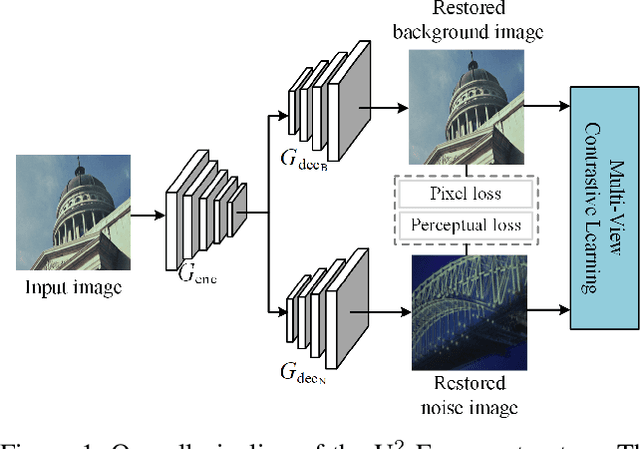
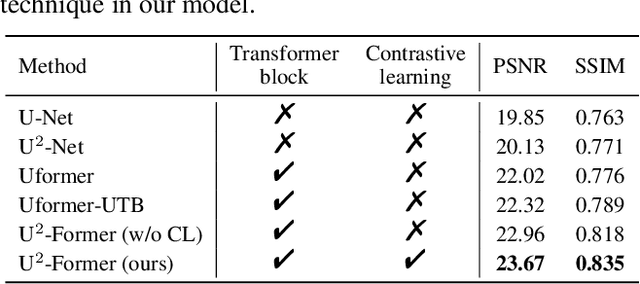
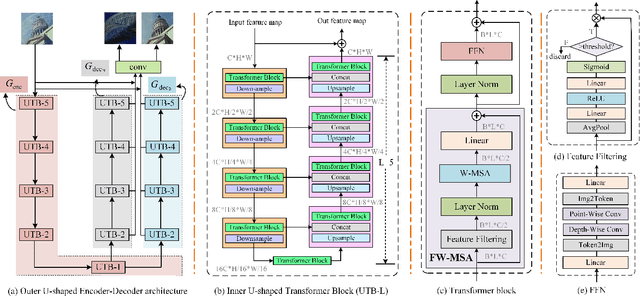
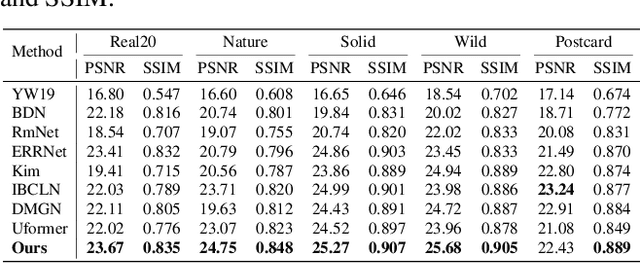
While Transformer has achieved remarkable performance in various high-level vision tasks, it is still challenging to exploit the full potential of Transformer in image restoration. The crux lies in the limited depth of applying Transformer in the typical encoder-decoder framework for image restoration, resulting from heavy self-attention computation load and inefficient communications across different depth (scales) of layers. In this paper, we present a deep and effective Transformer-based network for image restoration, termed as U2-Former, which is able to employ Transformer as the core operation to perform image restoration in a deep encoding and decoding space. Specifically, it leverages the nested U-shaped structure to facilitate the interactions across different layers with different scales of feature maps. Furthermore, we optimize the computational efficiency for the basic Transformer block by introducing a feature-filtering mechanism to compress the token representation. Apart from the typical supervision ways for image restoration, our U2-Former also performs contrastive learning in multiple aspects to further decouple the noise component from the background image. Extensive experiments on various image restoration tasks, including reflection removal, rain streak removal and dehazing respectively, demonstrate the effectiveness of the proposed U2-Former.
BPFNet: A Unified Framework for Bimodal Palmprint Alignment and Fusion
Oct 04, 2021
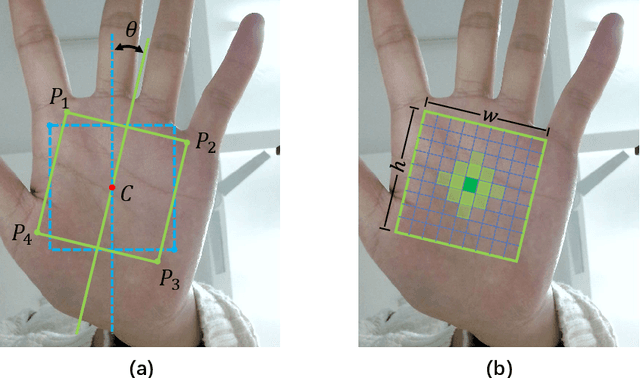
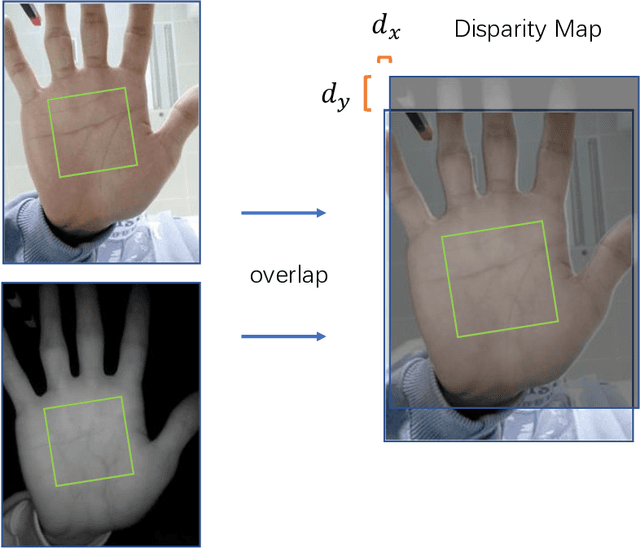
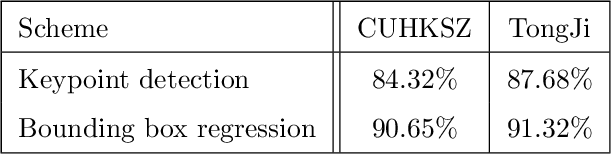
Bimodal palmprint recognition leverages palmprint and palm vein images simultaneously,which achieves high accuracy by multi-model information fusion and has strong anti-falsification property. In the recognition pipeline, the detection of palm and the alignment of region-of-interest (ROI) are two crucial steps for accurate matching. Most existing methods localize palm ROI by keypoint detection algorithms, however the intrinsic difficulties of keypoint detection tasks make the results unsatisfactory. Besides, the ROI alignment and fusion algorithms at image-level are not fully investigaged.To bridge the gap, in this paper, we propose Bimodal Palmprint Fusion Network (BPFNet) which focuses on ROI localization, alignment and bimodal image fusion.BPFNet is an end-to-end framework containing two subnets: The detection network directly regresses the palmprint ROIs based on bounding box prediction and conducts alignment by translation estimation.In the downstream,the bimodal fusion network implements bimodal ROI image fusion leveraging a novel proposed cross-modal selection scheme. To show the effectiveness of BPFNet,we carry out experiments on the large-scale touchless palmprint datasets CUHKSZ-v1 and TongJi and the proposed method achieves state-of-the-art performances.
Dual-Stream Reciprocal Disentanglement Learning for Domain Adaption Person Re-Identification
Jun 26, 2021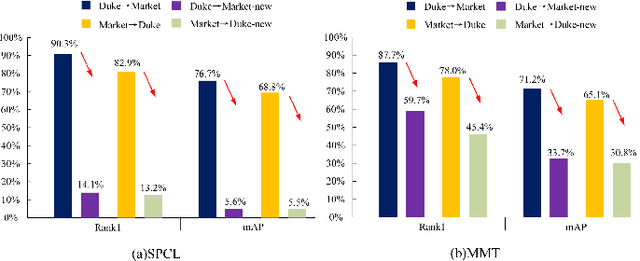
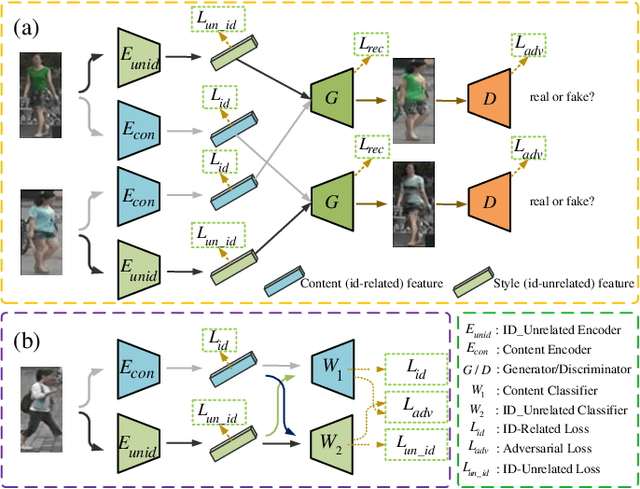
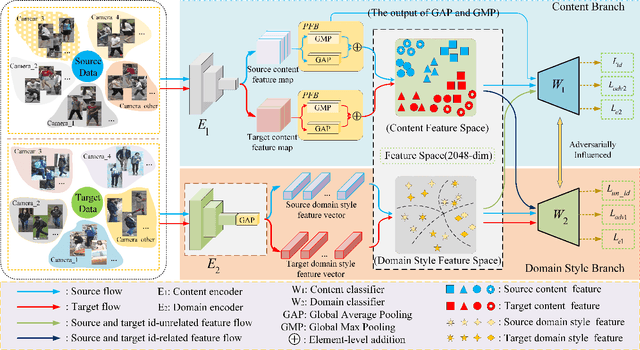
Since human-labeled samples are free for the target set, unsupervised person re-identification (Re-ID) has attracted much attention in recent years, by additionally exploiting the source set. However, due to the differences on camera styles, illumination and backgrounds, there exists a large gap between source domain and target domain, introducing a great challenge on cross-domain matching. To tackle this problem, in this paper we propose a novel method named Dual-stream Reciprocal Disentanglement Learning (DRDL), which is quite efficient in learning domain-invariant features. In DRDL, two encoders are first constructed for id-related and id-unrelated feature extractions, which are respectively measured by their associated classifiers. Furthermore, followed by an adversarial learning strategy, both streams reciprocally and positively effect each other, so that the id-related features and id-unrelated features are completely disentangled from a given image, allowing the encoder to be powerful enough to obtain the discriminative but domain-invariant features. In contrast to existing approaches, our proposed method is free from image generation, which not only reduces the computational complexity remarkably, but also removes redundant information from id-related features. Extensive experiments substantiate the superiority of our proposed method compared with the state-of-the-arts. The source code has been released in https://github.com/lhf12278/DRDL.
Touchless Palmprint Recognition based on 3D Gabor Template and Block Feature Refinement
Mar 03, 2021



With the growing demand for hand hygiene and convenience of use, palmprint recognition with touchless manner made a great development recently, providing an effective solution for person identification. Despite many efforts that have been devoted to this area, it is still uncertain about the discriminative ability of the contactless palmprint, especially for large-scale datasets. To tackle the problem, in this paper, we build a large-scale touchless palmprint dataset containing 2334 palms from 1167 individuals. To our best knowledge, it is the largest contactless palmprint image benchmark ever collected with regard to the number of individuals and palms. Besides, we propose a novel deep learning framework for touchless palmprint recognition named 3DCPN (3D Convolution Palmprint recognition Network) which leverages 3D convolution to dynamically integrate multiple Gabor features. In 3DCPN, a novel variant of Gabor filter is embedded into the first layer for enhancement of curve feature extraction. With a well-designed ensemble scheme,low-level 3D features are then convolved to extract high-level features. Finally on the top, we set a region-based loss function to strengthen the discriminative ability of both global and local descriptors. To demonstrate the superiority of our method, extensive experiments are conducted on our dataset and other popular databases TongJi and IITD, where the results show the proposed 3DCPN achieves state-of-the-art or comparable performances.
Auto-MVCNN: Neural Architecture Search for Multi-view 3D Shape Recognition
Dec 10, 2020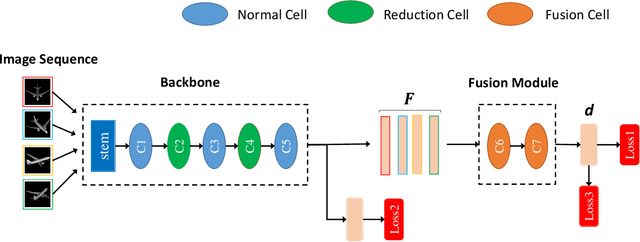
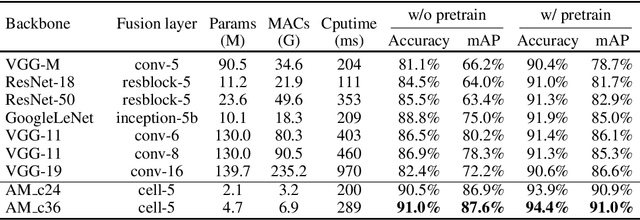
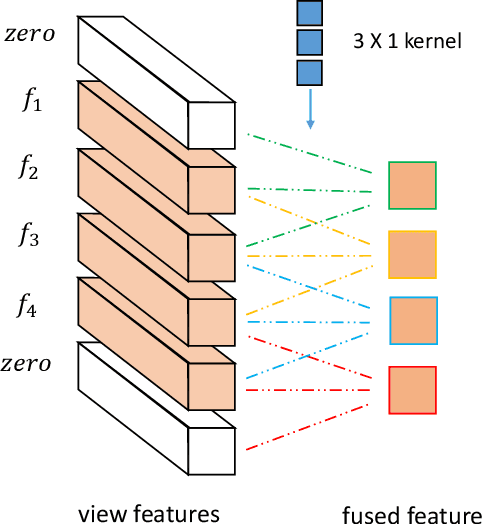
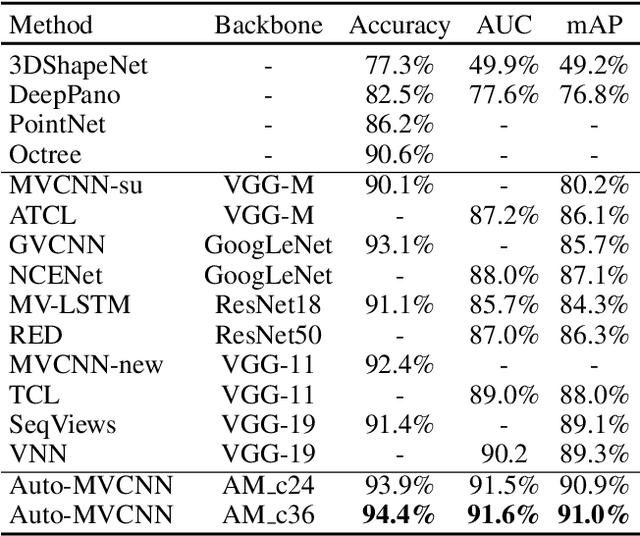
In 3D shape recognition, multi-view based methods leverage human's perspective to analyze 3D shapes and have achieved significant outcomes. Most existing research works in deep learning adopt handcrafted networks as backbones due to their high capacity of feature extraction, and also benefit from ImageNet pretraining. However, whether these network architectures are suitable for 3D analysis or not remains unclear. In this paper, we propose a neural architecture search method named Auto-MVCNN which is particularly designed for optimizing architecture in multi-view 3D shape recognition. Auto-MVCNN extends gradient-based frameworks to process multi-view images, by automatically searching the fusion cell to explore intrinsic correlation among view features. Moreover, we develop an end-to-end scheme to enhance retrieval performance through the trade-off parameter search. Extensive experimental results show that the searched architectures significantly outperform manually designed counterparts in various aspects, and our method achieves state-of-the-art performance at the same time.