 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded information enhancement and cross-modal attention feature fusion for multispectral pedestrian detection
Feb 17, 2023Multispectral pedestrian detection is a technology designed to detect and locate pedestrians in Color and Thermal images, which has been widely used in automatic driving, video surveillance, etc. So far most available multispectral pedestrian detection algorithms only achieved limited success in pedestrian detection because of the lacking take into account the confusion of pedestrian information and background noise in Color and Thermal images. Here we propose a multispectral pedestrian detection algorithm, which mainly consists of a cascaded information enhancement module and a cross-modal attention feature fusion module. On the one hand, the cascaded information enhancement module adopts the channel and spatial attention mechanism to perform attention weighting on the features fused by the cascaded feature fusion block. Moreover, it multiplies the single-modal features with the attention weight element by element to enhance the pedestrian features in the single-modal and thus suppress the interference from the background. On the other hand, the cross-modal attention feature fusion module mines the features of both Color and Thermal modalities to complement each other, then the global features are constructed by adding the cross-modal complemented features element by element, which are attentionally weighted to achieve the effective fusion of the two modal features. Finally, the fused features are input into the detection head to detect and locate pedestrians. Extensive experiments have been performed on two improved versions of annotations (sanitized annotations and paired annotations) of the public dataset KAIST. The experimental results show that our method demonstrates a lower pedestrian miss rate and more accurate pedestrian detection boxes compared to the comparison method. Additionally, the ablation experiment also proved the effectiveness of each module designed in this paper.
Learning Modal-Invariant and Temporal-Memory for Video-based Visible-Infrared Person Re-Identification
Aug 04, 2022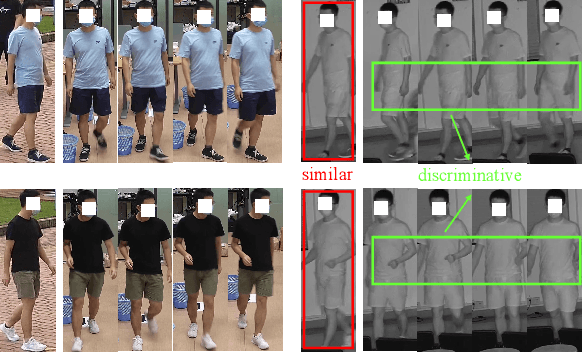


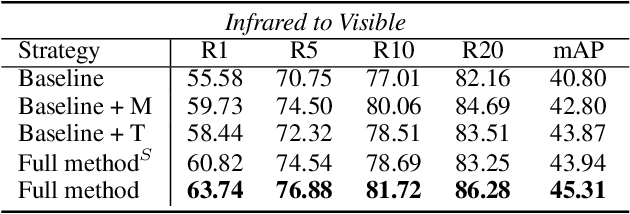
Thanks for the cross-modal retrieval techniques, visible-infrared (RGB-IR) person re-identification (Re-ID) is achieved by projecting them into a common space, allowing person Re-ID in 24-hour surveillance systems. However, with respect to the probe-to-gallery, almost all existing RGB-IR based cross-modal person Re-ID methods focus on image-to-image matching, while the video-to-video matching which contains much richer spatial- and temporal-information remains under-explored. In this paper, we primarily study the video-based cross-modal person Re-ID method. To achieve this task, a video-based RGB-IR dataset is constructed, in which 927 valid identities with 463,259 frames and 21,863 tracklets captured by 12 RGB/IR cameras are collected. Based on our constructed dataset, we prove that with the increase of frames in a tracklet, the performance does meet more enhancement, demonstrating the significance of video-to-video matching in RGB-IR person Re-ID. Additionally, a novel method is further proposed, which not only projects two modalities to a modal-invariant subspace, but also extracts the temporal-memory for motion-invariant. Thanks to these two strategies, much better results are achieved on our video-based cross-modal person Re-ID. The code and dataset are released at: https://github.com/VCMproject233/MITML.
Dual-Stream Reciprocal Disentanglement Learning for Domain Adaption Person Re-Identification
Jun 26, 2021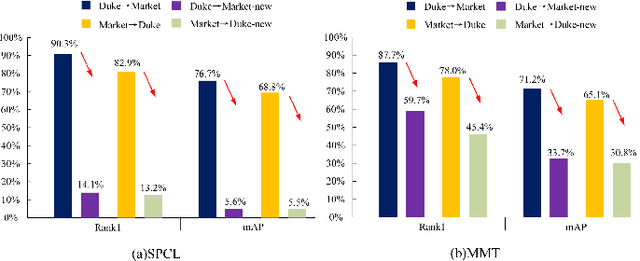
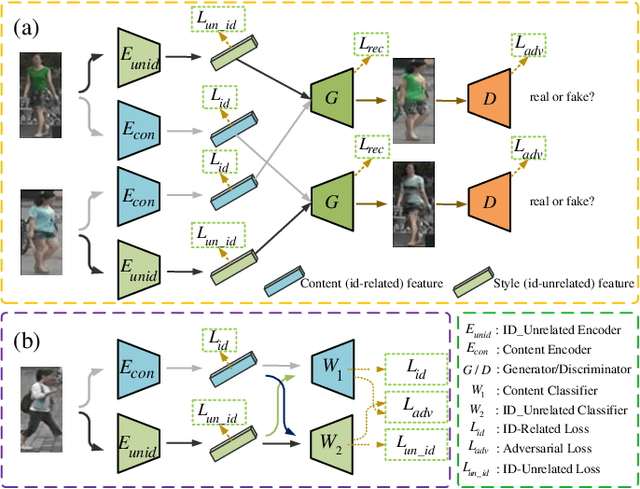
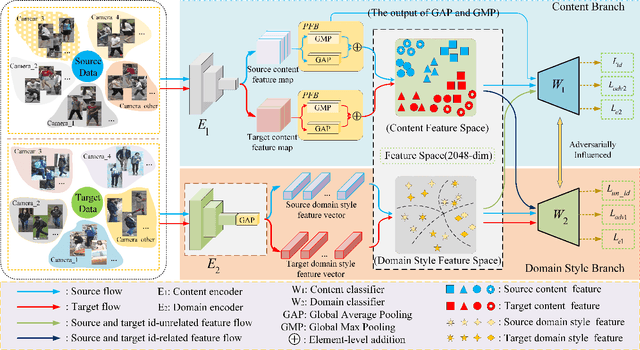
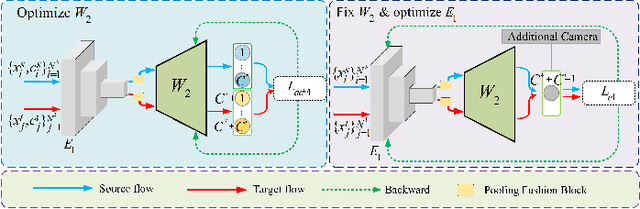
Since human-labeled samples are free for the target set, unsupervised person re-identification (Re-ID) has attracted much attention in recent years, by additionally exploiting the source set. However, due to the differences on camera styles, illumination and backgrounds, there exists a large gap between source domain and target domain, introducing a great challenge on cross-domain matching. To tackle this problem, in this paper we propose a novel method named Dual-stream Reciprocal Disentanglement Learning (DRDL), which is quite efficient in learning domain-invariant features. In DRDL, two encoders are first constructed for id-related and id-unrelated feature extractions, which are respectively measured by their associated classifiers. Furthermore, followed by an adversarial learning strategy, both streams reciprocally and positively effect each other, so that the id-related features and id-unrelated features are completely disentangled from a given image, allowing the encoder to be powerful enough to obtain the discriminative but domain-invariant features. In contrast to existing approaches, our proposed method is free from image generation, which not only reduces the computational complexity remarkably, but also removes redundant information from id-related features. Extensive experiments substantiate the superiority of our proposed method compared with the state-of-the-arts. The source code has been released in https://github.com/lhf12278/DRDL.