 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Nov 26, 2024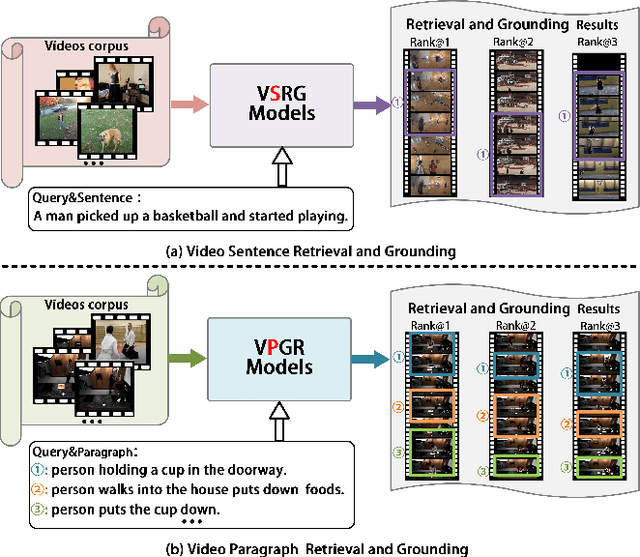
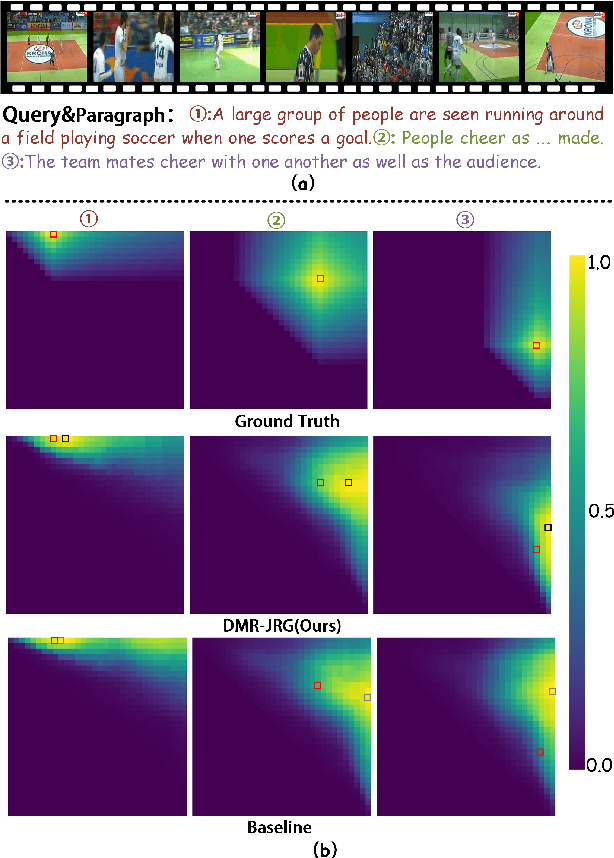

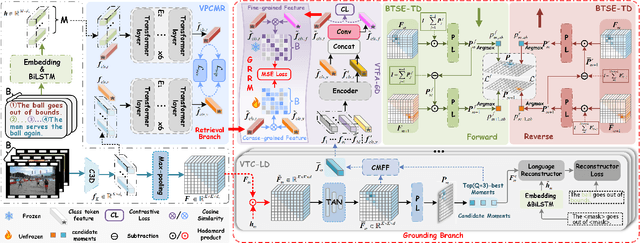
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.
Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding
Oct 31, 2024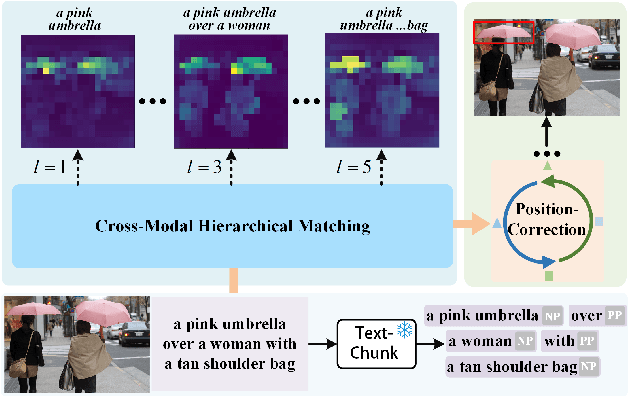

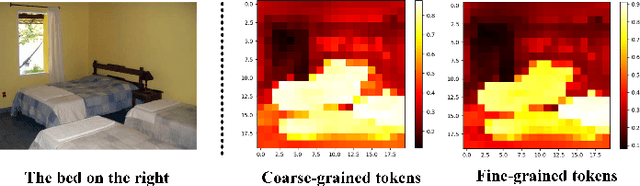
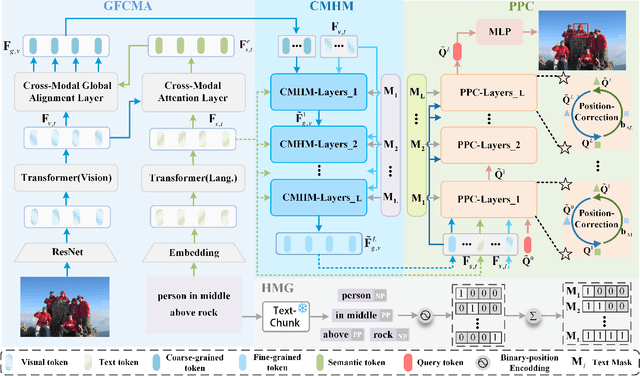
Visual grounding has attracted wide attention thanks to its broad application in various visual language tasks. Although visual grounding has made significant research progress, existing methods ignore the promotion effect of the association between text and image features at different hierarchies on cross-modal matching. This paper proposes a Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction Visual Grounding method. It first generates a mask through decoupled sentence phrases, and a text and image hierarchical matching mechanism is constructed, highlighting the role of association between different hierarchies in cross-modal matching. In addition, a corresponding target object position progressive correction strategy is defined based on the hierarchical matching mechanism to achieve accurate positioning for the target object described in the text. This method can continuously optimize and adjust the bounding box position of the target object as the certainty of the text description of the target object improves. This design explores the association between features at different hierarchies and highlights the role of features related to the target object and its position in target positioning. The proposed method is validated on different datasets through experiments, and its superiority is verified by the performance comparison with the state-of-the-art methods.
Optimizing rgb-d semantic segmentation through multi-modal interaction and pooling attention
Dec 06, 2023Semantic segmentation of RGB-D images involves understanding the appearance and spatial relationships of objects within a scene, which requires careful consideration of various factors. However, in indoor environments, the simple input of RGB and depth images often results in a relatively limited acquisition of semantic and spatial information, leading to suboptimal segmentation outcomes. To address this, we propose the Multi-modal Interaction and Pooling Attention Network (MIPANet), a novel approach designed to harness the interactive synergy between RGB and depth modalities, optimizing the utilization of complementary information. Specifically, we incorporate a Multi-modal Interaction Fusion Module (MIM) into the deepest layers of the network. This module is engineered to facilitate the fusion of RGB and depth information, allowing for mutual enhancement and correction. Additionally, we introduce a Pooling Attention Module (PAM) at various stages of the encoder. This module serves to amplify the features extracted by the network and integrates the module's output into the decoder in a targeted manner, significantly improving semantic segmentation performance. Our experimental results demonstrate that MIPANet outperforms existing methods on two indoor scene datasets, NYUDv2 and SUN-RGBD, underscoring its effectiveness in enhancing RGB-D semantic segmentation.