 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Metamemory Mechanisms for Enhanced Data-Free Code Generation in LLMs
Jan 14, 2025



Automated code generation using large language models (LLMs) has gained attention due to its efficiency and adaptability. However, real-world coding tasks or benchmarks like HumanEval and StudentEval often lack dedicated training datasets, challenging existing few-shot prompting approaches that rely on reference examples. Inspired by human metamemory-a cognitive process involving recall and evaluation-we present a novel framework (namely M^2WF) for improving LLMs' one-time code generation. This approach enables LLMs to autonomously generate, evaluate, and utilize synthetic examples to enhance reliability and performance. Unlike prior methods, it minimizes dependency on curated data and adapts flexibly to various coding scenarios. Our experiments demonstrate significant improvements in coding benchmarks, offering a scalable and robust solution for data-free environments. The code and framework will be publicly available on GitHub and HuggingFace.
AGMixup: Adaptive Graph Mixup for Semi-supervised Node Classification
Dec 11, 2024



Mixup is a data augmentation technique that enhances model generalization by interpolating between data points using a mixing ratio $\lambda$ in the image domain. Recently, the concept of mixup has been adapted to the graph domain through node-centric interpolations. However, these approaches often fail to address the complexity of interconnected relationships, potentially damaging the graph's natural topology and undermining node interactions. Furthermore, current graph mixup methods employ a one-size-fits-all strategy with a randomly sampled $\lambda$ for all mixup pairs, ignoring the diverse needs of different pairs. This paper proposes an Adaptive Graph Mixup (AGMixup) framework for semi-supervised node classification. AGMixup introduces a subgraph-centric approach, which treats each subgraph similarly to how images are handled in Euclidean domains, thus facilitating a more natural integration of mixup into graph-based learning. We also propose an adaptive mechanism to tune the mixing ratio $\lambda$ for diverse mixup pairs, guided by the contextual similarity and uncertainty of the involved subgraphs. Extensive experiments across seven datasets on semi-supervised node classification benchmarks demonstrate AGMixup's superiority over state-of-the-art graph mixup methods. Source codes are available at \url{https://github.com/WeigangLu/AGMixup}.
* Accepted by AAAI 2025
Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding
Nov 26, 2024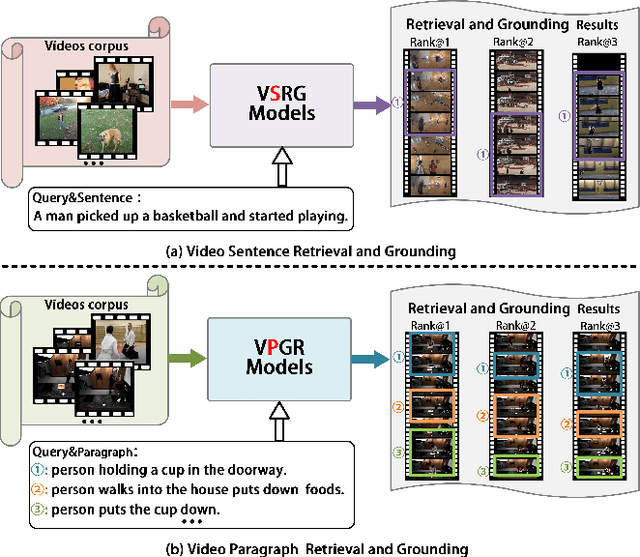
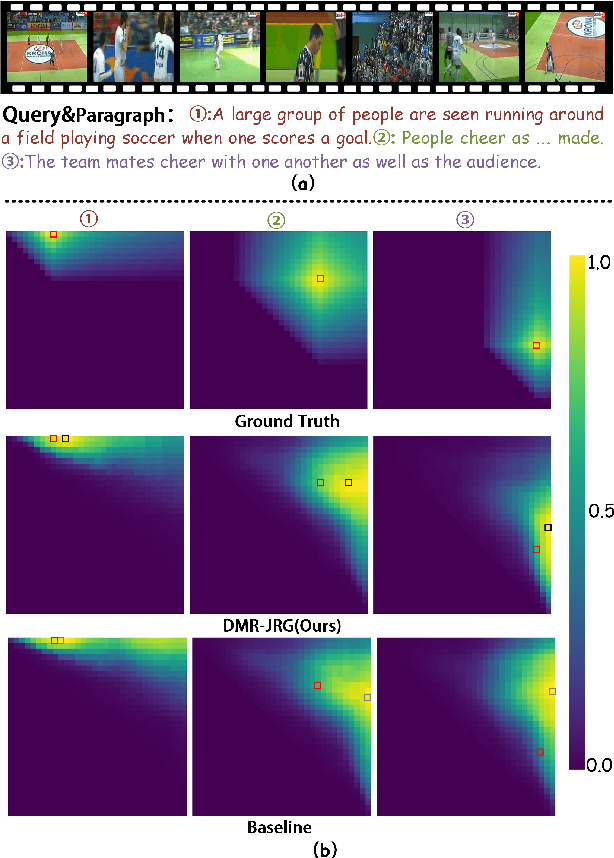

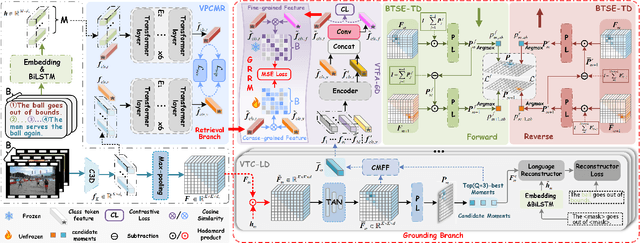
Video Paragraph Grounding (VPG) aims to precisely locate the most appropriate moments within a video that are relevant to a given textual paragraph query. However, existing methods typically rely on large-scale annotated temporal labels and assume that the correspondence between videos and paragraphs is known. This is impractical in real-world applications, as constructing temporal labels requires significant labor costs, and the correspondence is often unknown. To address this issue, we propose a Dual-task Mutual Reinforcing Embedded Joint Video Paragraph Retrieval and Grounding method (DMR-JRG). In this method, retrieval and grounding tasks are mutually reinforced rather than being treated as separate issues. DMR-JRG mainly consists of two branches: a retrieval branch and a grounding branch. The retrieval branch uses inter-video contrastive learning to roughly align the global features of paragraphs and videos, reducing modality differences and constructing a coarse-grained feature space to break free from the need for correspondence between paragraphs and videos. Additionally, this coarse-grained feature space further facilitates the grounding branch in extracting fine-grained contextual representations. In the grounding branch, we achieve precise cross-modal matching and grounding by exploring the consistency between local, global, and temporal dimensions of video segments and textual paragraphs. By synergizing these dimensions, we construct a fine-grained feature space for video and textual features, greatly reducing the need for large-scale annotated temporal labels.
Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction for Visual Grounding
Oct 31, 2024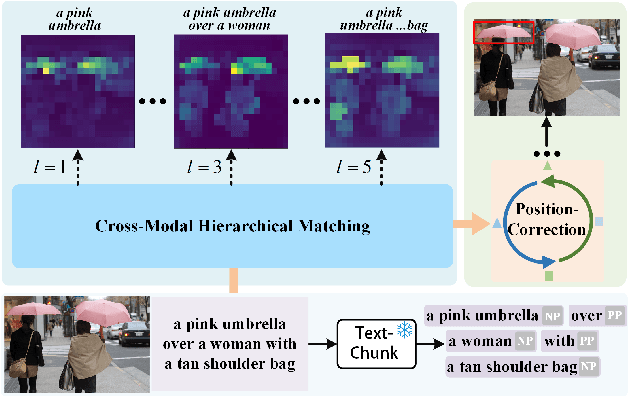

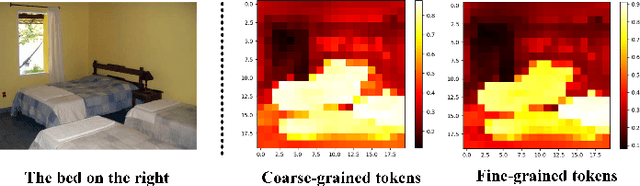
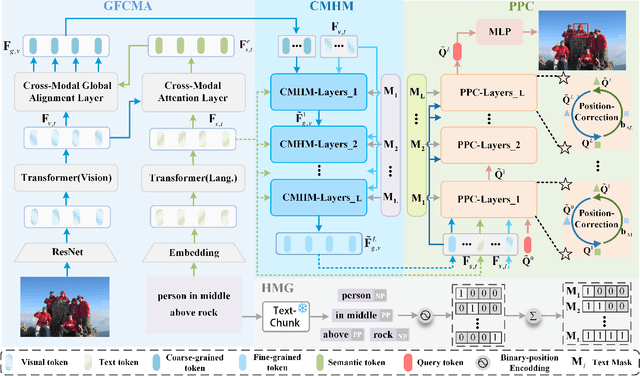
Visual grounding has attracted wide attention thanks to its broad application in various visual language tasks. Although visual grounding has made significant research progress, existing methods ignore the promotion effect of the association between text and image features at different hierarchies on cross-modal matching. This paper proposes a Phrase Decoupling Cross-Modal Hierarchical Matching and Progressive Position Correction Visual Grounding method. It first generates a mask through decoupled sentence phrases, and a text and image hierarchical matching mechanism is constructed, highlighting the role of association between different hierarchies in cross-modal matching. In addition, a corresponding target object position progressive correction strategy is defined based on the hierarchical matching mechanism to achieve accurate positioning for the target object described in the text. This method can continuously optimize and adjust the bounding box position of the target object as the certainty of the text description of the target object improves. This design explores the association between features at different hierarchies and highlights the role of features related to the target object and its position in target positioning. The proposed method is validated on different datasets through experiments, and its superiority is verified by the performance comparison with the state-of-the-art methods.
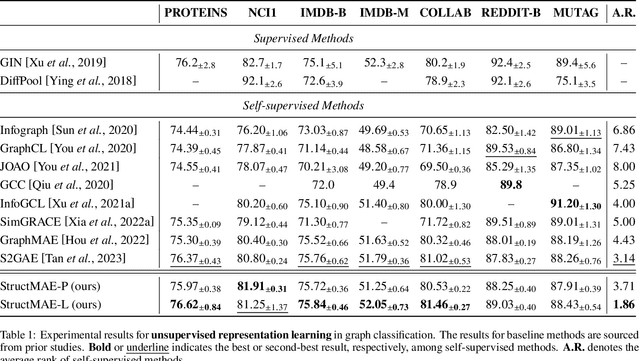
Hi-GMAE: Hierarchical Graph Masked Autoencoders
May 17, 2024Graph Masked Autoencoders (GMAEs) have emerged as a notable self-supervised learning approach for graph-structured data. Existing GMAE models primarily focus on reconstructing node-level information, categorizing them as single-scale GMAEs. This methodology, while effective in certain contexts, tends to overlook the complex hierarchical structures inherent in many real-world graphs. For instance, molecular graphs exhibit a clear hierarchical organization in the form of the atoms-functional groups-molecules structure. Hence, the inability of single-scale GMAE models to incorporate these hierarchical relationships often leads to their inadequate capture of crucial high-level graph information, resulting in a noticeable decline in performance. To address this limitation, we propose Hierarchical Graph Masked AutoEncoders (Hi-GMAE), a novel multi-scale GMAE framework designed to handle the hierarchical structures within graphs. First, Hi-GMAE constructs a multi-scale graph hierarchy through graph pooling, enabling the exploration of graph structures across different granularity levels. To ensure masking uniformity of subgraphs across these scales, we propose a novel coarse-to-fine strategy that initiates masking at the coarsest scale and progressively back-projects the mask to the finer scales. Furthermore, we integrate a gradual recovery strategy with the masking process to mitigate the learning challenges posed by completely masked subgraphs. Diverging from the standard graph neural network (GNN) used in GMAE models, Hi-GMAE modifies its encoder and decoder into hierarchical structures. This entails using GNN at the finer scales for detailed local graph analysis and employing a graph transformer at coarser scales to capture global information. Our experiments on 15 graph datasets consistently demonstrate that Hi-GMAE outperforms 17 state-of-the-art self-supervised competitors.
Harnessing the Power of MLLMs for Transferable Text-to-Image Person ReID
May 08, 2024



Text-to-image person re-identification (ReID) retrieves pedestrian images according to textual descriptions. Manually annotating textual descriptions is time-consuming, restricting the scale of existing datasets and therefore the generalization ability of ReID models. As a result, we study the transferable text-to-image ReID problem, where we train a model on our proposed large-scale database and directly deploy it to various datasets for evaluation. We obtain substantial training data via Multi-modal Large Language Models (MLLMs). Moreover, we identify and address two key challenges in utilizing the obtained textual descriptions. First, an MLLM tends to generate descriptions with similar structures, causing the model to overfit specific sentence patterns. Thus, we propose a novel method that uses MLLMs to caption images according to various templates. These templates are obtained using a multi-turn dialogue with a Large Language Model (LLM). Therefore, we can build a large-scale dataset with diverse textual descriptions. Second, an MLLM may produce incorrect descriptions. Hence, we introduce a novel method that automatically identifies words in a description that do not correspond with the image. This method is based on the similarity between one text and all patch token embeddings in the image. Then, we mask these words with a larger probability in the subsequent training epoch, alleviating the impact of noisy textual descriptions. The experimental results demonstrate that our methods significantly boost the direct transfer text-to-image ReID performance. Benefiting from the pre-trained model weights, we also achieve state-of-the-art performance in the traditional evaluation settings.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024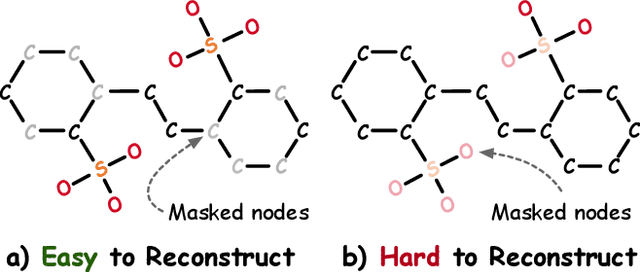
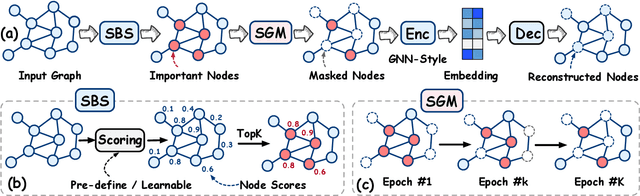
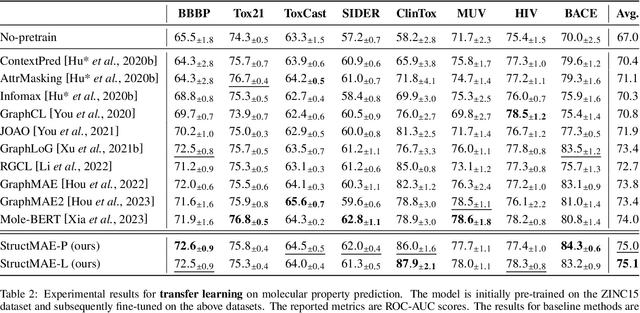
Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Single-Image HDR Reconstruction Assisted Ghost Suppression and Detail Preservation Network for Multi-Exposure HDR Imaging
Mar 07, 2024



The reconstruction of high dynamic range (HDR) images from multi-exposure low dynamic range (LDR) images in dynamic scenes presents significant challenges, especially in preserving and restoring information in oversaturated regions and avoiding ghosting artifacts. While current methods often struggle to address these challenges, our work aims to bridge this gap by developing a multi-exposure HDR image reconstruction network for dynamic scenes, complemented by single-frame HDR image reconstruction. This network, comprising single-frame HDR reconstruction with enhanced stop image (SHDR-ESI) and SHDR-ESI-assisted multi-exposure HDR reconstruction (SHDRA-MHDR), effectively leverages the ghost-free characteristic of single-frame HDR reconstruction and the detail-enhancing capability of ESI in oversaturated areas. Specifically, SHDR-ESI innovatively integrates single-frame HDR reconstruction with the utilization of ESI. This integration not only optimizes the single image HDR reconstruction process but also effectively guides the synthesis of multi-exposure HDR images in SHDR-AMHDR. In this method, the single-frame HDR reconstruction is specifically applied to reduce potential ghosting effects in multiexposure HDR synthesis, while the use of ESI images assists in enhancing the detail information in the HDR synthesis process. Technically, SHDR-ESI incorporates a detail enhancement mechanism, which includes a self-representation module and a mutual-representation module, designed to aggregate crucial information from both reference image and ESI. To fully leverage the complementary information from non-reference images, a feature interaction fusion module is integrated within SHDRA-MHDR. Additionally, a ghost suppression module, guided by the ghost-free results of SHDR-ESI, is employed to suppress the ghosting artifacts.
Large Language Models as an Indirect Reasoner: Contrapositive and Contradiction for Automated Reasoning
Feb 06, 2024Recently, increasing attention has been focused drawn on to improve the ability of Large Language Models (LLMs) to perform complex reasoning. However, previous methods, such as Chain-of-Thought and Self-Consistency, mainly follow Direct Reasoning (DR) frameworks, so they will meet difficulty in solving numerous real-world tasks which can hardly be solved via DR. Therefore, to strengthen the reasoning power of LLMs, this paper proposes a novel Indirect Reasoning (IR) method that employs the logic of contrapositives and contradictions to tackle IR tasks such as factual reasoning and mathematic proof. Specifically, our methodology comprises two steps. Firstly, we leverage the logical equivalence of contrapositive to augment the data and rules to enhance the comprehensibility of LLMs. Secondly, we design a set of prompt templates to trigger LLMs to conduct IR based on proof by contradiction that is logically equivalent to the original DR process. Our IR method is simple yet effective and can be straightforwardly integrated with existing DR methods to further boost the reasoning abilities of LLMs. The experimental results on popular LLMs, such as GPT-3.5-turbo and Gemini-pro, show that our IR method enhances the overall accuracy of factual reasoning by 27.33% and mathematical proof by 31.43%, when compared with traditional DR methods. Moreover, the methods combining IR and DR significantly outperform the methods solely using IR or DR, further demonstrating the effectiveness of our strategy.
CLIP-Driven Semantic Discovery Network for Visible-Infrared Person Re-Identification
Jan 12, 2024



Visible-infrared person re-identification (VIReID) primarily deals with matching identities across person images from different modalities. Due to the modality gap between visible and infrared images, cross-modality identity matching poses significant challenges. Recognizing that high-level semantics of pedestrian appearance, such as gender, shape, and clothing style, remain consistent across modalities, this paper intends to bridge the modality gap by infusing visual features with high-level semantics. Given the capability of CLIP to sense high-level semantic information corresponding to visual representations, we explore the application of CLIP within the domain of VIReID. Consequently, we propose a CLIP-Driven Semantic Discovery Network (CSDN) that consists of Modality-specific Prompt Learner, Semantic Information Integration (SII), and High-level Semantic Embedding (HSE). Specifically, considering the diversity stemming from modality discrepancies in language descriptions, we devise bimodal learnable text tokens to capture modality-private semantic information for visible and infrared images, respectively. Additionally, acknowledging the complementary nature of semantic details across different modalities, we integrate text features from the bimodal language descriptions to achieve comprehensive semantics. Finally, we establish a connection between the integrated text features and the visual features across modalities. This process embed rich high-level semantic information into visual representations, thereby promoting the modality invariance of visual representations. The effectiveness and superiority of our proposed CSDN over existing methods have been substantiated through experimental evaluations on multiple widely used benchmarks. The code will be released at \url{https://github.com/nengdong96/CSDN}.