 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP-Agent: A Calibrated Risk-Controlled Agent for Feedback-Driven Competitive Programming
May 23, 2026Large language models still struggle with contest-level programming, while many agentic remedies rely on massive inference-time sampling or expensive multi-stage post-training. We study when execution feedback reliably helps an LLM CP solver and which mechanisms govern the gains. We model feedback-driven solving as a calibrated stopped process and identify three quantities: false-admission risk, program-level evidence against bad programs, and the active-state success hazard. Under held-out trace calibration and selection from a pre-declared finite controller manifest, the resulting structural certificate lower-bounds the clean success probability before false admission. We instantiate mechanisms targeting these quantities as Dual-Granularity Verification, Test Augmentation, and Experience-Driven Self-Evolving, yielding CP-Agent. Without updating any parameters, CP-Agent raises Pass@1 from 25.8\% to 48.5\% on LiveCodeBench Pro and improves Refine@5 by 11.0\% on ICPC-Eval. Across three LLM backbones, CP-Agent lies on the cost--accuracy efficiency frontier, and ablations show that each component primarily affects its corresponding certificate quantity.
EvoMemBench: Benchmarking Agent Memory from a Self-Evolving Perspective
May 18, 2026Recent benchmarks for Large Language Model (LLM) agents mainly evaluate reasoning, planning, and execution. However, memory is also essential for agents, as it enables them to store, update, and retrieve information over time. This ability remains under-evaluated, largely because existing benchmarks do not provide a systematic way to assess memory mechanisms. In this paper, we study agent memory from a self-evolving perspective and introduce EvoMemBench, a unified benchmark organized along two axes: memory scope (in-episode vs. cross-episode) and memory content (knowledge-oriented vs. execution-oriented). We compare 15 representative memory methods with strong long-context baselines under a standardized protocol. Results show that current memory systems are still far from a general solution: long-context baselines remain highly competitive, memory helps most when the current context is insufficient or tasks are difficult, and no single memory form works consistently across all settings. Retrieval-based methods remain strong for knowledge-intensive settings, whereas procedural and long-term memory methods are more effective for execution-oriented tasks when their stored experience matches the task structure. We hope EvoMemBench facilitates future research on more effective memory systems for LLM-based agents. Our code is available at https://github.com/DSAIL-Memory/EvoMemBench.
SCOT: Multi-Source Cross-City Transfer with Optimal-Transport Soft-Correspondence Objective
Apr 08, 2026Cross-city transfer improves prediction in label-scarce cities by leveraging labeled data from other cities, but it becomes challenging when cities adopt incompatible partitions and no ground-truth region correspondences exist. Existing approaches either rely on heuristic region matching, which is often sensitive to anchor choices, or perform distribution-level alignment that leaves correspondences implicit and can be unstable under strong heterogeneity. We propose SCOT, a cross-city representation learning framework that learns explicit soft correspondences between unequal region sets via Sinkhorn-based entropic optimal transport. SCOT further sharpens transferable structure with an OT-weighted contrastive objective and stabilizes optimization through a cycle-style reconstruction regularizer. For multi-source transfer, SCOT aligns each source and the target to a shared prototype hub using balanced entropic transport guided by a target-induced prototype prior. Across real-world cities and tasks, SCOT consistently improves transfer accuracy and robustness, while the learned transport couplings and hub assignments provide interpretable diagnostics of alignment quality.
From Text to Forecasts: Bridging Modality Gap with Temporal Evolution Semantic Space
Mar 16, 2026Incorporating textual information into time-series forecasting holds promise for addressing event-driven non-stationarity; however, a fundamental modality gap hinders effective fusion: textual descriptions express temporal impacts implicitly and qualitatively, whereas forecasting models rely on explicit and quantitative signals. Through controlled semi-synthetic experiments, we show that existing methods over-attend to redundant tokens and struggle to reliably translate textual semantics into usable numerical cues. To bridge this gap, we propose TESS, which introduces a Temporal Evolution Semantic Space as an intermediate bottleneck between modalities. This space consists of interpretable, numerically grounded temporal primitives (mean shift, volatility, shape, and lag) extracted from text by an LLM via structured prompting and filtered through confidence-aware gating. Experiments on four real-world datasets demonstrate up to a 29 percent reduction in forecasting error compared to state-of-the-art unimodal and multimodal baselines. The code will be released after acceptance.
What Papers Don't Tell You: Recovering Tacit Knowledge for Automated Paper Reproduction
Mar 02, 2026Automated paper reproduction -- generating executable code from academic papers -- is bottlenecked not by information retrieval but by the tacit knowledge that papers inevitably leave implicit. We formalize this challenge as the progressive recovery of three types of tacit knowledge -- relational, somatic, and collective -- and propose \method, a graph-based agent framework with a dedicated mechanism for each: node-level relation-aware aggregation recovers relational knowledge by analyzing implementation-unit-level reuse and adaptation relationships between the target paper and its citation neighbors; execution-feedback refinement recovers somatic knowledge through iterative debugging driven by runtime signals; and graph-level knowledge induction distills collective knowledge from clusters of papers sharing similar implementations. On an extended ReproduceBench spanning 3 domains, 10 tasks, and 40 recent papers, \method{} achieves an average performance gap of 10.04\% against official implementations, improving over the strongest baseline by 24.68\%. The code will be publicly released upon acceptance; the repository link will be provided in the final version.
Block Empirical Likelihood Inference for Longitudinal Generalized Partially Linear Single-Index Models
Feb 16, 2026Generalized partially linear single-index models (GPLSIMs) provide a flexible and interpretable semiparametric framework for longitudinal outcomes by combining a low-dimensional parametric component with a nonparametric index component. For repeated measurements, valid inference is challenging because within-subject correlation induces nuisance parameters and variance estimation can be unstable in semiparametric settings. We propose a profile estimating-equation approach based on spline approximation of the unknown link function and construct a subject-level block empirical likelihood (BEL) for joint inference on the parametric coefficients and the single-index direction. The resulting BEL ratio statistic enjoys a Wilks-type chi-square limit, yielding likelihood-free confidence regions without explicit sandwich variance estimation. We also discuss practical implementation, including constrained optimization for the index parameter, working-correlation choices, and bootstrap-based confidence bands for the nonparametric component. Simulation studies and an application to the epilepsy longitudinal study illustrate the finite-sample performance.
AlgBench: To What Extent Do Large Reasoning Models Understand Algorithms?
Jan 08, 2026Reasoning ability has become a central focus in the advancement of Large Reasoning Models (LRMs). Although notable progress has been achieved on several reasoning benchmarks such as MATH500 and LiveCodeBench, existing benchmarks for algorithmic reasoning remain limited, failing to answer a critical question: Do LRMs truly master algorithmic reasoning? To answer this question, we propose AlgBench, an expert-curated benchmark that evaluates LRMs under an algorithm-centric paradigm. AlgBench consists of over 3,000 original problems spanning 27 algorithms, constructed by ACM algorithmic experts and organized under a comprehensive taxonomy, including Euclidean-structured, non-Euclidean-structured, non-optimized, local-optimized, global-optimized, and heuristic-optimized categories. Empirical evaluations on leading LRMs (e.g., Gemini-3-Pro, DeepSeek-v3.2-Speciale and GPT-o3) reveal substantial performance heterogeneity: while models perform well on non-optimized tasks (up to 92%), accuracy drops sharply to around 49% on globally optimized algorithms such as dynamic programming. Further analysis uncovers \textbf{strategic over-shifts}, wherein models prematurely abandon correct algorithmic designs due to necessary low-entropy tokens. These findings expose fundamental limitations of problem-centric reinforcement learning and highlight the necessity of an algorithm-centric training paradigm for robust algorithmic reasoning.
History-Aware Transformation of ReID Features for Multiple Object Tracking
Mar 16, 2025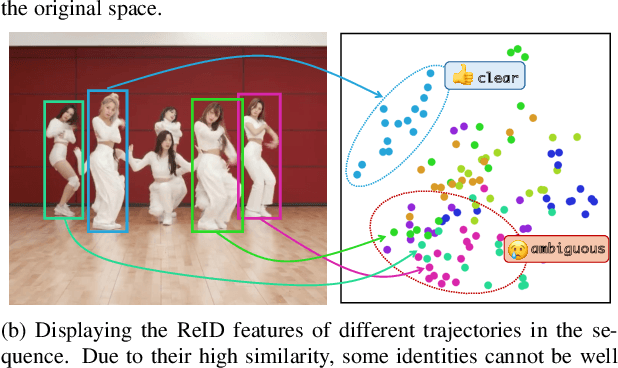
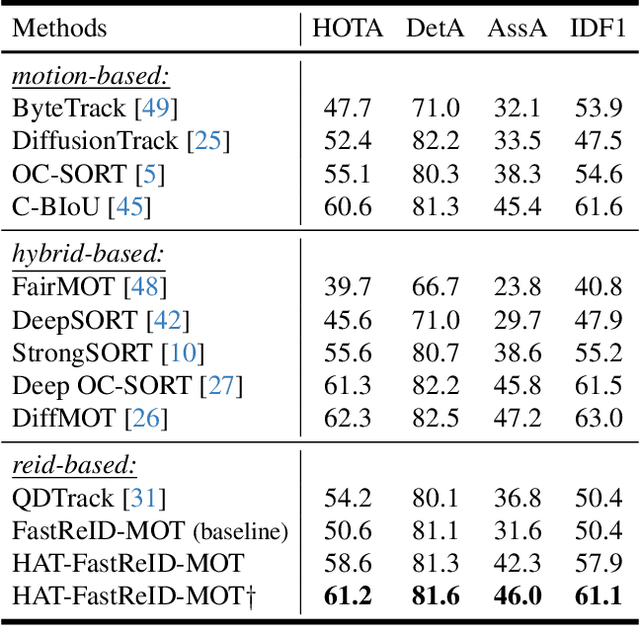
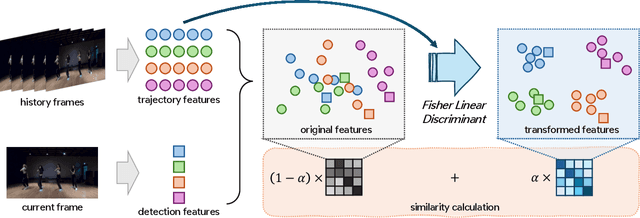
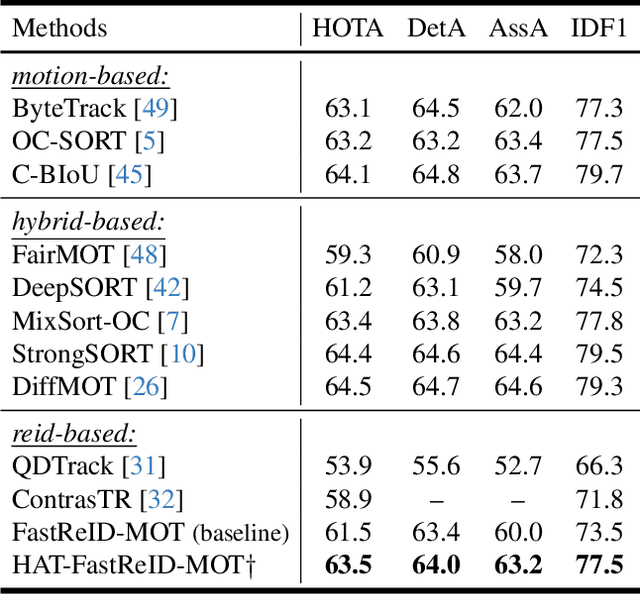
The aim of multiple object tracking (MOT) is to detect all objects in a video and bind them into multiple trajectories. Generally, this process is carried out in two steps: detecting objects and associating them across frames based on various cues and metrics. Many studies and applications adopt object appearance, also known as re-identification (ReID) features, for target matching through straightforward similarity calculation. However, we argue that this practice is overly naive and thus overlooks the unique characteristics of MOT tasks. Unlike regular re-identification tasks that strive to distinguish all potential targets in a general representation, multi-object tracking typically immerses itself in differentiating similar targets within the same video sequence. Therefore, we believe that seeking a more suitable feature representation space based on the different sample distributions of each sequence will enhance tracking performance. In this paper, we propose using history-aware transformations on ReID features to achieve more discriminative appearance representations. Specifically, we treat historical trajectory features as conditions and employ a tailored Fisher Linear Discriminant (FLD) to find a spatial projection matrix that maximizes the differentiation between different trajectories. Our extensive experiments reveal that this training-free projection can significantly boost feature-only trackers to achieve competitive, even superior tracking performance compared to state-of-the-art methods while also demonstrating impressive zero-shot transfer capabilities. This demonstrates the effectiveness of our proposal and further encourages future investigation into the importance and customization of ReID models in multiple object tracking. The code will be released at https://github.com/HELLORPG/HATReID-MOT.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024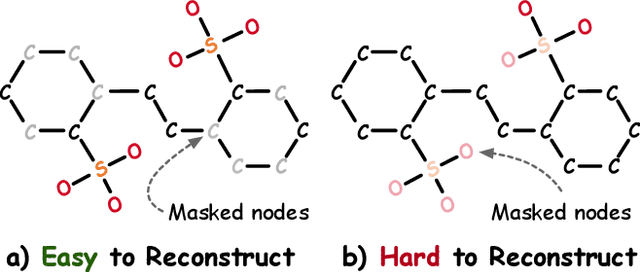
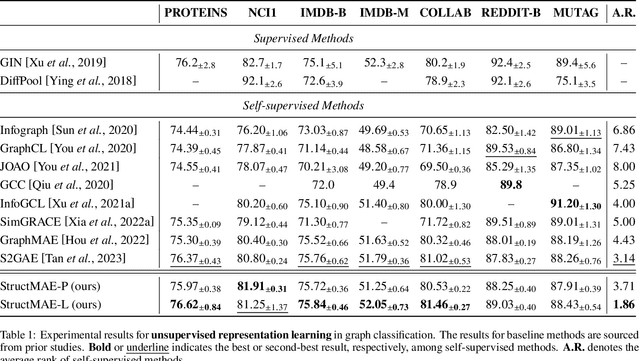
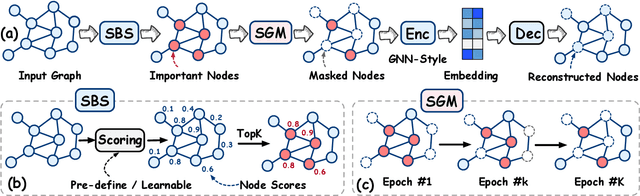
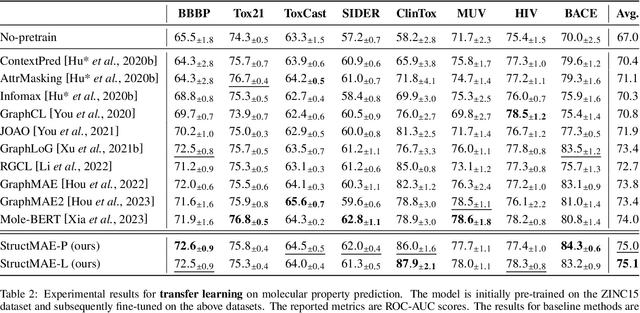
Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation
May 02, 2023
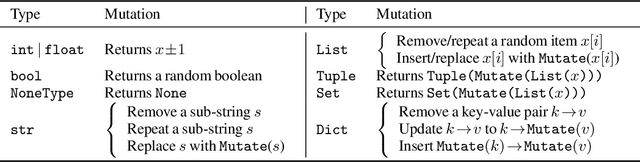
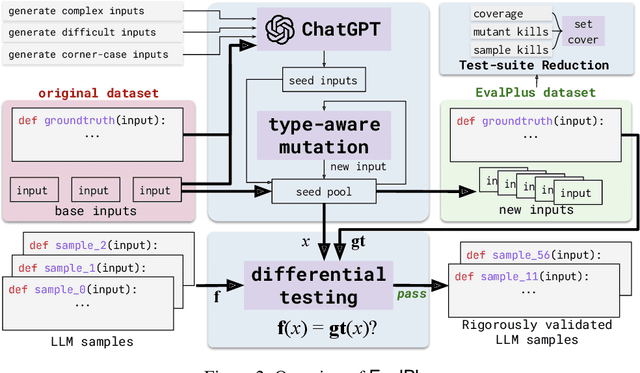
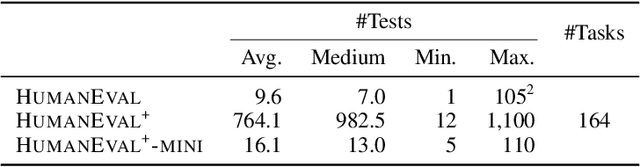
Program synthesis has been long studied with recent approaches focused on directly using the power of Large Language Models (LLMs) to generate code according to user intent written in natural language. Code evaluation datasets, containing curated synthesis problems with input/output test-cases, are used to measure the performance of various LLMs on code synthesis. However, test-cases in these datasets can be limited in both quantity and quality for fully assessing the functional correctness of the generated code. Such limitation in the existing benchmarks begs the following question: In the era of LLMs, is the code generated really correct? To answer this, we propose EvalPlus -- a code synthesis benchmarking framework to rigorously evaluate the functional correctness of LLM-synthesized code. In short, EvalPlus takes in the base evaluation dataset and uses an automatic input generation step to produce and diversify large amounts of new test inputs using both LLM-based and mutation-based input generators to further validate the synthesized code. We extend the popular HUMANEVAL benchmark and build HUMANEVAL+ with 81x additionally generated tests. Our extensive evaluation across 14 popular LLMs demonstrates that HUMANEVAL+ is able to catch significant amounts of previously undetected wrong code synthesized by LLMs, reducing the pass@k by 15.1% on average! Moreover, we even found several incorrect ground-truth implementations in HUMANEVAL. Our work not only indicates that prior popular code synthesis evaluation results do not accurately reflect the true performance of LLMs for code synthesis but also opens up a new direction to improve programming benchmarks through automated test input generation.