 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimension-Reduction Attack! Video Generative Models are Experts on Controllable Image Synthesis
May 29, 2025Video generative models can be regarded as world simulators due to their ability to capture dynamic, continuous changes inherent in real-world environments. These models integrate high-dimensional information across visual, temporal, spatial, and causal dimensions, enabling predictions of subjects in various status. A natural and valuable research direction is to explore whether a fully trained video generative model in high-dimensional space can effectively support lower-dimensional tasks such as controllable image generation. In this work, we propose a paradigm for video-to-image knowledge compression and task adaptation, termed \textit{Dimension-Reduction Attack} (\texttt{DRA-Ctrl}), which utilizes the strengths of video models, including long-range context modeling and flatten full-attention, to perform various generation tasks. Specially, to address the challenging gap between continuous video frames and discrete image generation, we introduce a mixup-based transition strategy that ensures smooth adaptation. Moreover, we redesign the attention structure with a tailored masking mechanism to better align text prompts with image-level control. Experiments across diverse image generation tasks, such as subject-driven and spatially conditioned generation, show that repurposed video models outperform those trained directly on images. These results highlight the untapped potential of large-scale video generators for broader visual applications. \texttt{DRA-Ctrl} provides new insights into reusing resource-intensive video models and lays foundation for future unified generative models across visual modalities. The project page is https://dra-ctrl-2025.github.io/DRA-Ctrl/.
CoE: Chain-of-Explanation via Automatic Visual Concept Circuit Description and Polysemanticity Quantification
Mar 19, 2025Explainability is a critical factor influencing the wide deployment of deep vision models (DVMs). Concept-based post-hoc explanation methods can provide both global and local insights into model decisions. However, current methods in this field face challenges in that they are inflexible to automatically construct accurate and sufficient linguistic explanations for global concepts and local circuits. Particularly, the intrinsic polysemanticity in semantic Visual Concepts (VCs) impedes the interpretability of concepts and DVMs, which is underestimated severely. In this paper, we propose a Chain-of-Explanation (CoE) approach to address these issues. Specifically, CoE automates the decoding and description of VCs to construct global concept explanation datasets. Further, to alleviate the effect of polysemanticity on model explainability, we design a concept polysemanticity disentanglement and filtering mechanism to distinguish the most contextually relevant concept atoms. Besides, a Concept Polysemanticity Entropy (CPE), as a measure of model interpretability, is formulated to quantify the degree of concept uncertainty. The modeling of deterministic concepts is upgraded to uncertain concept atom distributions. Finally, CoE automatically enables linguistic local explanations of the decision-making process of DVMs by tracing the concept circuit. GPT-4o and human-based experiments demonstrate the effectiveness of CPE and the superiority of CoE, achieving an average absolute improvement of 36% in terms of explainability scores.
Large Language Model Safety: A Holistic Survey
Dec 23, 2024



The rapid development and deployment of large language models (LLMs) have introduced a new frontier in artificial intelligence, marked by unprecedented capabilities in natural language understanding and generation. However, the increasing integration of these models into critical applications raises substantial safety concerns, necessitating a thorough examination of their potential risks and associated mitigation strategies. This survey provides a comprehensive overview of the current landscape of LLM safety, covering four major categories: value misalignment, robustness to adversarial attacks, misuse, and autonomous AI risks. In addition to the comprehensive review of the mitigation methodologies and evaluation resources on these four aspects, we further explore four topics related to LLM safety: the safety implications of LLM agents, the role of interpretability in enhancing LLM safety, the technology roadmaps proposed and abided by a list of AI companies and institutes for LLM safety, and AI governance aimed at LLM safety with discussions on international cooperation, policy proposals, and prospective regulatory directions. Our findings underscore the necessity for a proactive, multifaceted approach to LLM safety, emphasizing the integration of technical solutions, ethical considerations, and robust governance frameworks. This survey is intended to serve as a foundational resource for academy researchers, industry practitioners, and policymakers, offering insights into the challenges and opportunities associated with the safe integration of LLMs into society. Ultimately, it seeks to contribute to the safe and beneficial development of LLMs, aligning with the overarching goal of harnessing AI for societal advancement and well-being. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLM-Safety-Papers.
DA-MoE: Addressing Depth-Sensitivity in Graph-Level Analysis through Mixture of Experts
Nov 05, 2024



Graph neural networks (GNNs) are gaining popularity for processing graph-structured data. In real-world scenarios, graph data within the same dataset can vary significantly in scale. This variability leads to depth-sensitivity, where the optimal depth of GNN layers depends on the scale of the graph data. Empirically, fewer layers are sufficient for message passing in smaller graphs, while larger graphs typically require deeper networks to capture long-range dependencies and global features. However, existing methods generally use a fixed number of GNN layers to generate representations for all graphs, overlooking the depth-sensitivity issue in graph structure data. To address this challenge, we propose the depth adaptive mixture of expert (DA-MoE) method, which incorporates two main improvements to GNN backbone: \textbf{1)} DA-MoE employs different GNN layers, each considered an expert with its own parameters. Such a design allows the model to flexibly aggregate information at different scales, effectively addressing the depth-sensitivity issue in graph data. \textbf{2)} DA-MoE utilizes GNN to capture the structural information instead of the linear projections in the gating network. Thus, the gating network enables the model to capture complex patterns and dependencies within the data. By leveraging these improvements, each expert in DA-MoE specifically learns distinct graph patterns at different scales. Furthermore, comprehensive experiments on the TU dataset and open graph benchmark (OGB) have shown that DA-MoE consistently surpasses existing baselines on various tasks, including graph, node, and link-level analyses. The code are available at \url{https://github.com/Celin-Yao/DA-MoE}.
Dual-perspective Cross Contrastive Learning in Graph Transformers
Jun 01, 2024Graph contrastive learning (GCL) is a popular method for leaning graph representations by maximizing the consistency of features across augmented views. Traditional GCL methods utilize single-perspective i.e. data or model-perspective) augmentation to generate positive samples, restraining the diversity of positive samples. In addition, these positive samples may be unreliable due to uncontrollable augmentation strategies that potentially alter the semantic information. To address these challenges, this paper proposed a innovative framework termed dual-perspective cross graph contrastive learning (DC-GCL), which incorporates three modifications designed to enhance positive sample diversity and reliability: 1) We propose dual-perspective augmentation strategy that provide the model with more diverse training data, enabling the model effective learning of feature consistency across different views. 2) From the data perspective, we slightly perturb the original graphs using controllable data augmentation, effectively preserving their semantic information. 3) From the model perspective, we enhance the encoder by utilizing more powerful graph transformers instead of graph neural networks. Based on the model's architecture, we propose three pruning-based strategies to slightly perturb the encoder, providing more reliable positive samples. These modifications collectively form the DC-GCL's foundation and provide more diverse and reliable training inputs, offering significant improvements over traditional GCL methods. Extensive experiments on various benchmarks demonstrate that DC-GCL consistently outperforms different baselines on various datasets and tasks.
Hi-GMAE: Hierarchical Graph Masked Autoencoders
May 17, 2024Graph Masked Autoencoders (GMAEs) have emerged as a notable self-supervised learning approach for graph-structured data. Existing GMAE models primarily focus on reconstructing node-level information, categorizing them as single-scale GMAEs. This methodology, while effective in certain contexts, tends to overlook the complex hierarchical structures inherent in many real-world graphs. For instance, molecular graphs exhibit a clear hierarchical organization in the form of the atoms-functional groups-molecules structure. Hence, the inability of single-scale GMAE models to incorporate these hierarchical relationships often leads to their inadequate capture of crucial high-level graph information, resulting in a noticeable decline in performance. To address this limitation, we propose Hierarchical Graph Masked AutoEncoders (Hi-GMAE), a novel multi-scale GMAE framework designed to handle the hierarchical structures within graphs. First, Hi-GMAE constructs a multi-scale graph hierarchy through graph pooling, enabling the exploration of graph structures across different granularity levels. To ensure masking uniformity of subgraphs across these scales, we propose a novel coarse-to-fine strategy that initiates masking at the coarsest scale and progressively back-projects the mask to the finer scales. Furthermore, we integrate a gradual recovery strategy with the masking process to mitigate the learning challenges posed by completely masked subgraphs. Diverging from the standard graph neural network (GNN) used in GMAE models, Hi-GMAE modifies its encoder and decoder into hierarchical structures. This entails using GNN at the finer scales for detailed local graph analysis and employing a graph transformer at coarser scales to capture global information. Our experiments on 15 graph datasets consistently demonstrate that Hi-GMAE outperforms 17 state-of-the-art self-supervised competitors.
Where to Mask: Structure-Guided Masking for Graph Masked Autoencoders
Apr 24, 2024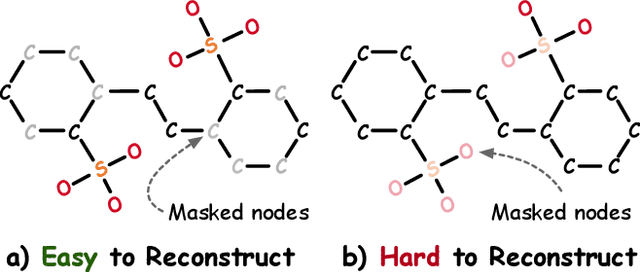
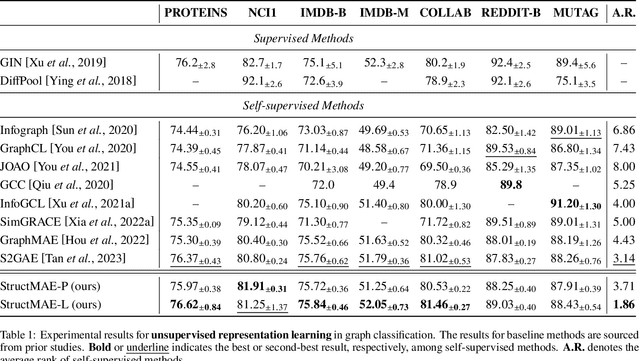
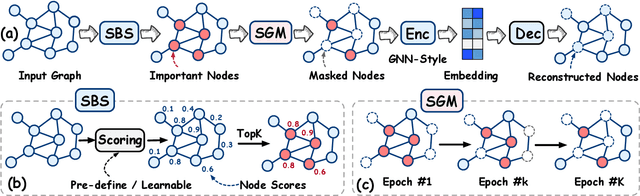
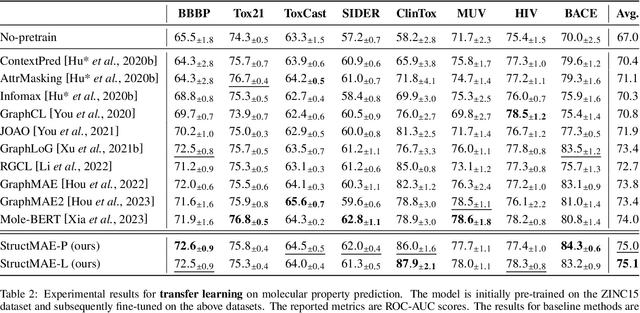
Graph masked autoencoders (GMAE) have emerged as a significant advancement in self-supervised pre-training for graph-structured data. Previous GMAE models primarily utilize a straightforward random masking strategy for nodes or edges during training. However, this strategy fails to consider the varying significance of different nodes within the graph structure. In this paper, we investigate the potential of leveraging the graph's structural composition as a fundamental and unique prior in the masked pre-training process. To this end, we introduce a novel structure-guided masking strategy (i.e., StructMAE), designed to refine the existing GMAE models. StructMAE involves two steps: 1) Structure-based Scoring: Each node is evaluated and assigned a score reflecting its structural significance. Two distinct types of scoring manners are proposed: predefined and learnable scoring. 2) Structure-guided Masking: With the obtained assessment scores, we develop an easy-to-hard masking strategy that gradually increases the structural awareness of the self-supervised reconstruction task. Specifically, the strategy begins with random masking and progresses to masking structure-informative nodes based on the assessment scores. This design gradually and effectively guides the model in learning graph structural information. Furthermore, extensive experiments consistently demonstrate that our StructMAE method outperforms existing state-of-the-art GMAE models in both unsupervised and transfer learning tasks. Codes are available at https://github.com/LiuChuang0059/StructMAE.
Gradformer: Graph Transformer with Exponential Decay
Apr 24, 2024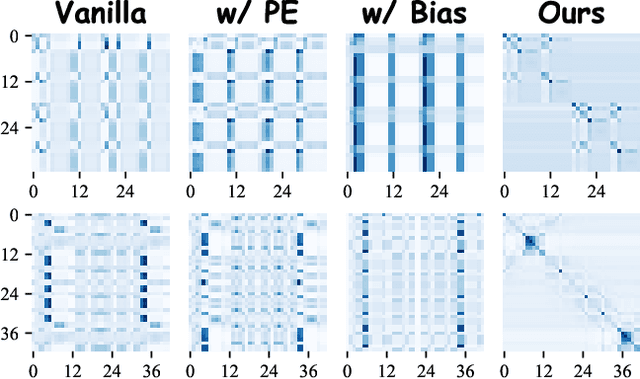
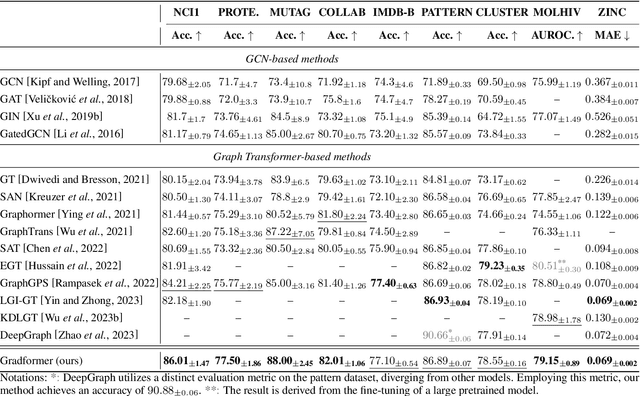
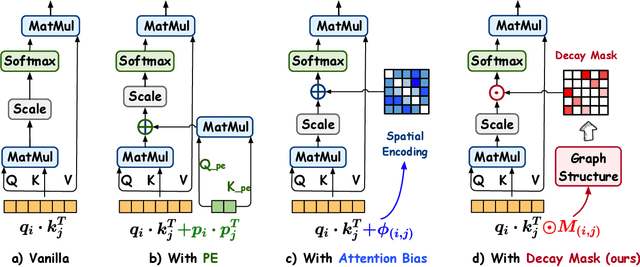
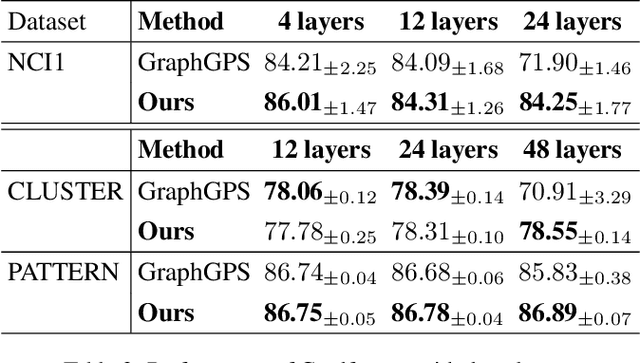
Graph Transformers (GTs) have demonstrated their advantages across a wide range of tasks. However, the self-attention mechanism in GTs overlooks the graph's inductive biases, particularly biases related to structure, which are crucial for the graph tasks. Although some methods utilize positional encoding and attention bias to model inductive biases, their effectiveness is still suboptimal analytically. Therefore, this paper presents Gradformer, a method innovatively integrating GT with the intrinsic inductive bias by applying an exponential decay mask to the attention matrix. Specifically, the values in the decay mask matrix diminish exponentially, correlating with the decreasing node proximities within the graph structure. This design enables Gradformer to retain its ability to capture information from distant nodes while focusing on the graph's local details. Furthermore, Gradformer introduces a learnable constraint into the decay mask, allowing different attention heads to learn distinct decay masks. Such an design diversifies the attention heads, enabling a more effective assimilation of diverse structural information within the graph. Extensive experiments on various benchmarks demonstrate that Gradformer consistently outperforms the Graph Neural Network and GT baseline models in various graph classification and regression tasks. Additionally, Gradformer has proven to be an effective method for training deep GT models, maintaining or even enhancing accuracy compared to shallow models as the network deepens, in contrast to the significant accuracy drop observed in other GT models.Codes are available at \url{https://github.com/LiuChuang0059/Gradformer}.
LHMKE: A Large-scale Holistic Multi-subject Knowledge Evaluation Benchmark for Chinese Large Language Models
Mar 19, 2024Chinese Large Language Models (LLMs) have recently demonstrated impressive capabilities across various NLP benchmarks and real-world applications. However, the existing benchmarks for comprehensively evaluating these LLMs are still insufficient, particularly in terms of measuring knowledge that LLMs capture. Current datasets collect questions from Chinese examinations across different subjects and educational levels to address this issue. Yet, these benchmarks primarily focus on objective questions such as multiple-choice questions, leading to a lack of diversity in question types. To tackle this problem, we propose LHMKE, a Large-scale, Holistic, and Multi-subject Knowledge Evaluation benchmark in this paper. LHMKE is designed to provide a comprehensive evaluation of the knowledge acquisition capabilities of Chinese LLMs. It encompasses 10,465 questions across 75 tasks covering 30 subjects, ranging from primary school to professional certification exams. Notably, LHMKE includes both objective and subjective questions, offering a more holistic evaluation of the knowledge level of LLMs. We have assessed 11 Chinese LLMs under the zero-shot setting, which aligns with real examinations, and compared their performance across different subjects. We also conduct an in-depth analysis to check whether GPT-4 can automatically score subjective predictions. Our findings suggest that LHMKE is a challenging and advanced testbed for Chinese LLMs.
OpenEval: Benchmarking Chinese LLMs across Capability, Alignment and Safety
Mar 18, 2024



The rapid development of Chinese large language models (LLMs) poses big challenges for efficient LLM evaluation. While current initiatives have introduced new benchmarks or evaluation platforms for assessing Chinese LLMs, many of these focus primarily on capabilities, usually overlooking potential alignment and safety issues. To address this gap, we introduce OpenEval, an evaluation testbed that benchmarks Chinese LLMs across capability, alignment and safety. For capability assessment, we include 12 benchmark datasets to evaluate Chinese LLMs from 4 sub-dimensions: NLP tasks, disciplinary knowledge, commonsense reasoning and mathematical reasoning. For alignment assessment, OpenEval contains 7 datasets that examines the bias, offensiveness and illegalness in the outputs yielded by Chinese LLMs. To evaluate safety, especially anticipated risks (e.g., power-seeking, self-awareness) of advanced LLMs, we include 6 datasets. In addition to these benchmarks, we have implemented a phased public evaluation and benchmark update strategy to ensure that OpenEval is in line with the development of Chinese LLMs or even able to provide cutting-edge benchmark datasets to guide the development of Chinese LLMs. In our first public evaluation, we have tested a range of Chinese LLMs, spanning from 7B to 72B parameters, including both open-source and proprietary models. Evaluation results indicate that while Chinese LLMs have shown impressive performance in certain tasks, more attention should be directed towards broader aspects such as commonsense reasoning, alignment, and safety.